虚拟内存系统的设计空间正在不断扩展,也带来了全新的挑战,涵盖ISA设计、内存布局和管理、虚拟化等多个方面,虚拟内存实现的复杂度正在成倍增长。由异构系统和虚拟化带来的一些特殊挑战包括以下方面:
当被访问的数据在另一个设备甚至另一台机器上时,内存访问可能有更高的延迟;
设备的虚拟地址空间可能与某些主机进程的虚拟地址空间相同,也可能是其子集,也可能不相关;
很难处理page fault,通常加速器上不会运行操作系统;
实现跨设备的缓存一致性是非常困难和昂贵的,但是省略硬件实现的一致性会给程序员带来更大的负担;
面对不同的内存性能特征,对物理内存中的数据进行优化管理(分配、迁移和驱逐)成为一个不可忽视的难题;
在虚拟化系统中,内存访问和虚拟内存管理必须要么通过hypervisor(即增加一个额外的抽象层次),要么依靠专用硬件支持来避免额外的延迟;
…
加速器和共享虚拟内存
虚拟内存提供在设备间共享基于(虚拟地址)指针的数据结构的能力,GPU、DSP等加速器可以和CPU共享同一个虚拟地址空间。我们现在主要以GPU为例讨论共享虚拟内存,但大部分内容也同样适用于其他设备。
早期的GPU需要从CPU以粗粒度发送数据到GPU,但现在的GPU可以共享虚拟地址空间,可以管理自己的内存并动态启动新任务,在某些特殊情况下可以和CPU或其他GPU以细粒度共享数据。对程序员来说,也不再需要单独的内存分配,而是可以直接访问和管理映射的内存。目前关键的限制之一是缺乏对虚拟内存管理的系统级支持,如GPU上没有操作系统,就没有简单的方法来处理page fault。
即使是CPU上的操作系统对跨设备共享虚拟内存的支持也有一定的局限性。GPU通常还提供很弱的内存一致性模型,这使得通信更加难以推理,也使如何实现同步指令更有挑战性。GPU微架构的设计师为了最大程度地提高吞吐量,会激进地融合、重排各个内存请求,并且也不一定总是和CPU保持硬件上的一致性,也就是说GPU要么不允许CPU和GPU在一开始就同时访问数据,要么就需要一些特殊的机制(如按需的页面级数据移动),或者甚至根本不缓存那些存在于其他设备上的数据。
内存的异构性
我们之前可能总是隐含假设了内存访问的延迟和带宽是一致的,也就是统一内存访问(UMA),但在一个系统中有可能某些区域的行为和其他区域不同,即非统一内存访问(NUMA),同一集群内的内存访问延迟较低,不同集群间的内存访问则延迟较高。UMA和NUMA的例子如下图所示。
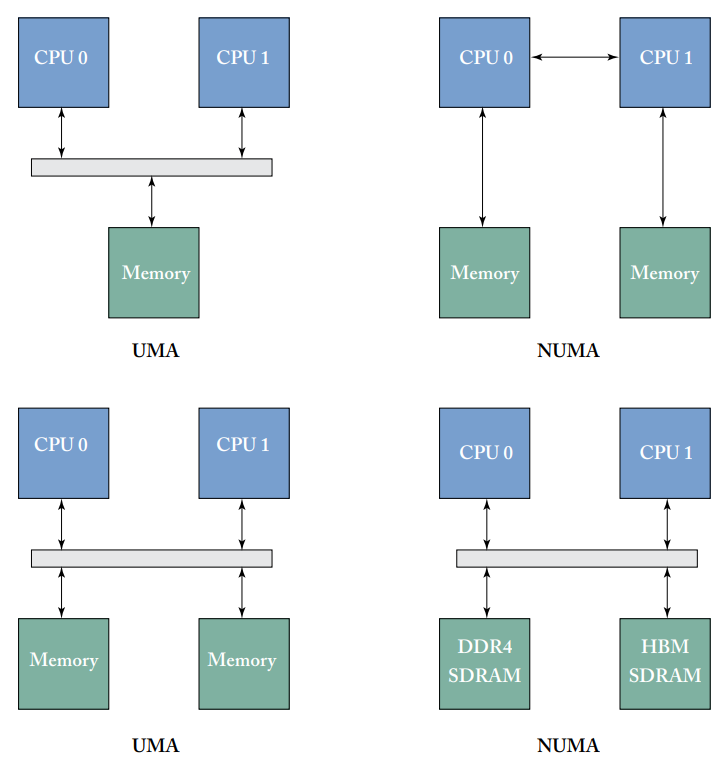 UMA和NUMA系统的例子
UMA和NUMA系统的例子
NUMA
虚拟机可能会在分布式系统中的多个不同节点上共享。早期分布式NUMA实现不支持缓存一致性,因此会依赖于过于复杂的编程模型,程序员使用起来比较困难。斯坦福大学的DASH项目是第一个建立可扩展的分布式缓存一致性NUMA(ccNUMA)系统。
现在更常见的是,当内存分布在单个系统中的多个处理器上时,就会出现NUMA系统。例如,现在许多服务器级系统在一块主板上有多个处理器,使用板载总线互连,如AMD HyperTransport或Intel QPI来在处理器之间进行通信。单一系统的NUMA通常通过使用复杂的缓存一致性协议(如MOESI、MESIF)来保持一致性,并尽可能减少处理器间的通信。单系统共享虚拟内存空间也正在扩展到外围设备,如GPU。
NUMA带来的主要挑战是为优化系统性能而必须进行一系列更复杂的内存管理。最简单的选择是忽略NUMA,但往往会导致性能低下,数据可能被放在很远的地方。相反,在理想情况下,所有的内存都要尽可能地靠近访问的处理器,尽可能减少延迟、提高吞吐量。例如,系统可以选择尽可能靠近某个处理器来分配内存区域,然后采用某种动态页面迁移策略,根据不断变化的系统状态来移动页面。
新兴内存技术
一个系统中还可能使用不同的物理内存类型,如GPU使用GDDR来取代传统的DDR DRAM,吞吐量更高但功耗也更大,甚至有些高端GPU已经开始采用HBM内存,虚拟内存管理策略需要考虑到这些不同种类的物理内存。甚至有些非易失性的存储器也正在进入内存系统。
跨设备通信
DMA
DMA的一个重要方面是,硬件并不总是自动保证DMA操作和CPU的缓存保持一致性。在缓存一致的DMA系统中,DMA请求会自动探测缓存内容,如果需要的话会在执行DMA之前将缓存中的内容更新到内存,但如果不保证缓存一致性的话,则需要软件来手动执行这些操作。
IOMMU
加速器上的虚拟内存是通过IOMMU来支持的,所有从外部设备到CPU内存的访问,如果未命中设备自己的TLB,都要通过IOMMU来进行地址翻译,且page fault时进行处理。IOMMU和普通MMU的区别在于其相对于管理设备的位置,IOMMU也位于CPU片上,和加速器设备有一定距离,也是所有设备地址翻译请求的中央枢纽,如下图所示。
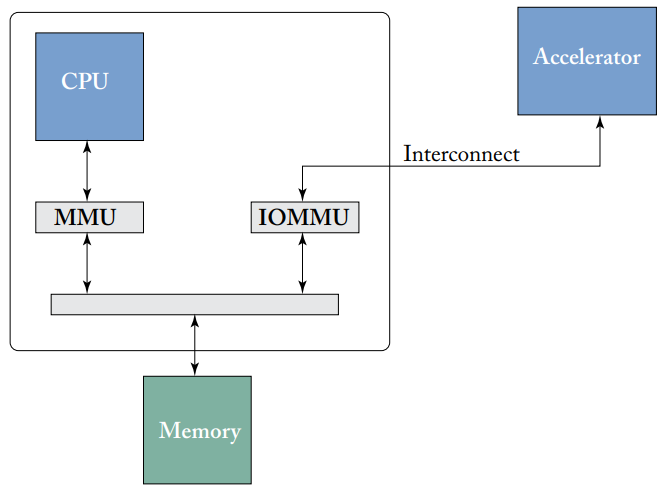 IOMMU为外部设备和加速器进行虚拟内存管理
IOMMU为外部设备和加速器进行虚拟内存管理
IOMMU使加速器可以从虚拟内存中获益,不仅为外部设备提供虚拟内存功能,也可以确保其不会访问操作系统没有明确定义的任何其他内存区域。
MMIO
虚拟内存的另一个特殊而重要的用途是MMIO,一些外部通信机制,最常见的是一些外部设备的配置寄存器,被映射到CPU的物理地址空间,映射到进程的虚拟地址空间后,就可以使用一般的读写命令来与设备进行通信。
尽管MMIO的抽象对于编程模型和实现的简单性来说是很好的,但把IO请求当作内存请求来处理会带来一些额外的麻烦,如需要小心这些请求不会无限期停留在缓存中,且需要注意这些MMIO请求可能违反内存通常遵循的其他规则,如MMIO的读取可能不会返回最近写到同一地址的值。
为了使MMIO能正常工作,大多数处理器都提供了一些机制来指示某些内存区域与某些内存访问应该被视为不可缓存的,会完全绕过各种缓冲区,和fence类似,会保证请求的顺序,其访问通常也是很慢的,需要尽可能减少使用。
虚拟化
虚拟化是当今实现云基础设施的关键技术,好处是提高了安全性、隔离性、服务 器整合能力和容错性,但也带来了性能挑战。理想情况下,系统在虚拟机上运行应用程序时,其性能与在本地运行应用程序时相同,然而,虚拟内存是造成本地和虚拟化应用性能差距的主要因素之一,主要问题在于虚拟化需要两级地址转换。在第一层,guest虚拟地址(gVA)通过guest操作系统页表(gPT)转换为guest物理地址(gPA),然后,gPA通过主机页表(hPT)转换为主机物理地址(hPA)。有两种方法来管理这些页表,分别为嵌套页表和影子页表。
嵌套页表
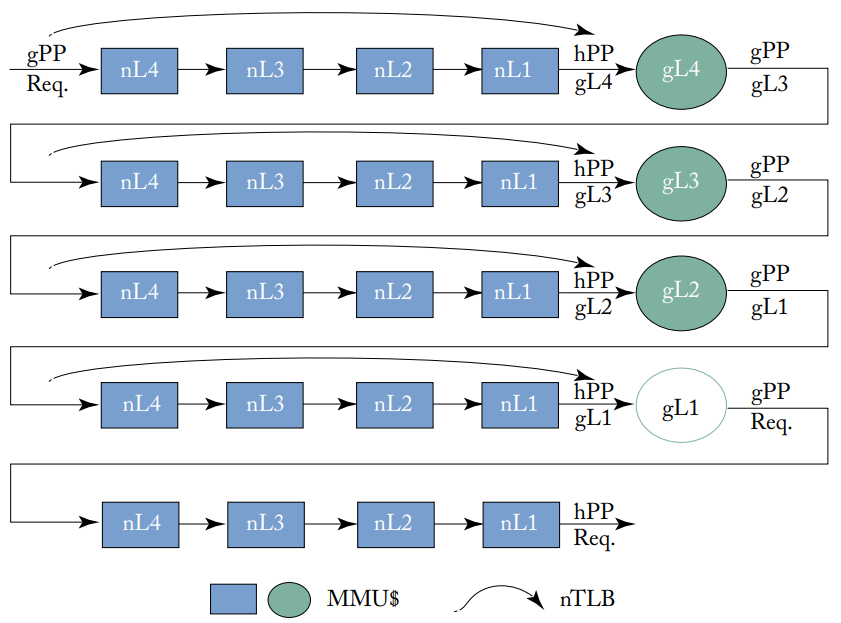 虚拟化系统的二维页表遍历,圆圈是guest页表,TLB(没有画在图上)缓存了从请求的gVP到hPP的转换
虚拟化系统的二维页表遍历,圆圈是guest页表,TLB(没有画在图上)缓存了从请求的gVP到hPP的转换
大多数虚拟化系统使用嵌套页表,当guest虚拟机中运行的进程访问内存时,需要把gVA翻译成hPA,如上图所示。Guest的CR3寄存器和请求的gVP一同得出页表第四级的gPP,并开始访问嵌套页表,这个过程如图所示总共需要24次内存访问,会带来一些性能问题,且这些内存访问是顺序、有依赖性的。CPU使用三种类型的结构来加速这一过程:
每个CPU的私有TLB缓存了gVP到hPP的映射,避免了整个页表访问过程;
每个CPU的私有MMU缓存存储中间页表信息来加速部分页表遍历的过程;
每个CPU的私有n级TLB跳过了从GPP到HPP的页表访问过程(如上图弧线箭头所示)。
影子页表
影子页表是嵌套页表的替代方法,hypervisor创建一个影子页表,合并了gPT和hPT,存储gVA到hPA的转换。TLB命中的过程和嵌套页表类似,但TLB未命中时,和二维页表遍历不同,影子页表可以通过标准的4个内存访问来进行遍历。影子页表的缺点在于这种页表更新的开销很大,主要问题在于影子页表必须和guest和主机页表保持一致,尤其是guest页表的更新往往很频繁,需要通过hypervisor来更新影子页表,这种机制会严重影响性能。