虚拟内存系统通常处于每个指令和数据访问的关键路径上,我们需要使用硬件来尽可能加速这一过程。本节我们深入讨论现代虚拟内存系统的硬件设计空间的细节,包括架构(如ISA规定的页表项格式)和微架构(如TLB的物理布局)。
反转页表
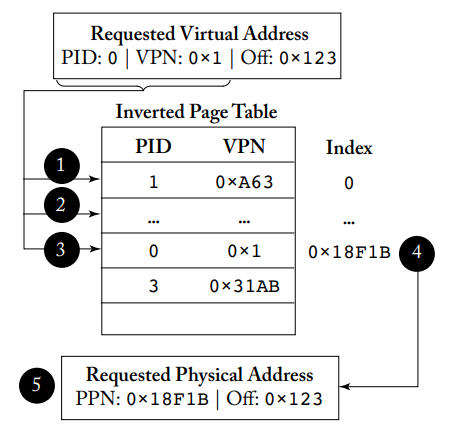
节省页表空间的一种方法是采用反转页表,为系统中的每个物理页面维护一个页表项,该页表项表示哪个进程使用这个物理页面,以及该进程的哪个虚拟页面映射到该物理页面,也就是说我们为系统中的所有进程维护一个单一的反转页表。具体的实现和访问过程如下图所示。
 反转页表的访问
反转页表的访问
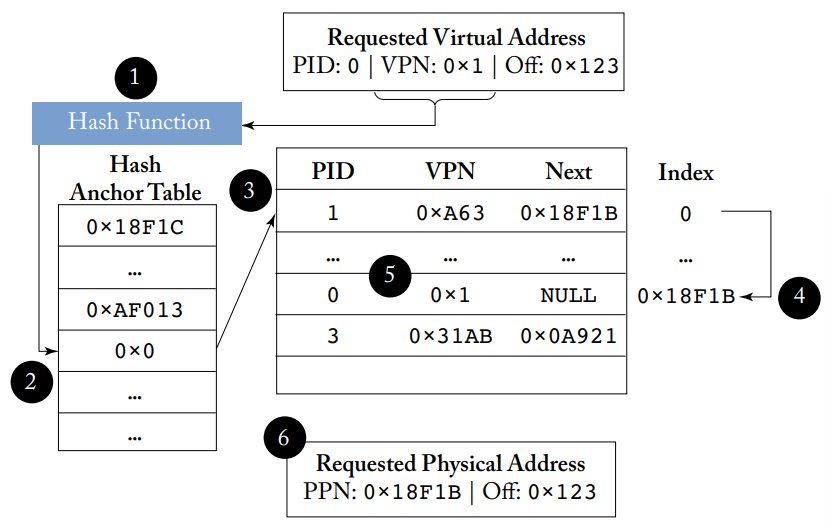
找到正确的页表项需要搜索反转页表的数据结构,最简单的是采用线性扫描,但显然速度很慢。我们通常采用哈希表以加快查找速度,首先计算哈希值,然后从哈希值开始搜索表,大大减少了需要搜索的页表项的数量。哈希碰撞的情况和软件上的哈希表处理方式类似,如果哈希值对应的位置上不匹配,那么就沿着碰撞链去搜索。碰撞链可以用不同的方式实现,例如可以放在表内,或者更常用的方法是采用HAT(Hash Anchor Table),结构和访问过程如下图所示,其关键创新点在于增加HAT的大小可以减少平均的碰撞链长度,无需改变反转页表的大小,更为灵活方便。
 使用HAT的哈希页表
使用HAT的哈希页表
TLB的设计
多级TLB
现代处理器普遍实现了多级TLB,一个是实现上的问题是,最后一级TLB应该是私有的还是共享的。私有TLB可以减少竞争、降低延迟,而共享TLB可以更有效地利用存储资源。同时,TLB可以设计为统一的或分离的,即是否要分离指令和数据。
相对于缓存的位置
 TLB放置策略
TLB放置策略
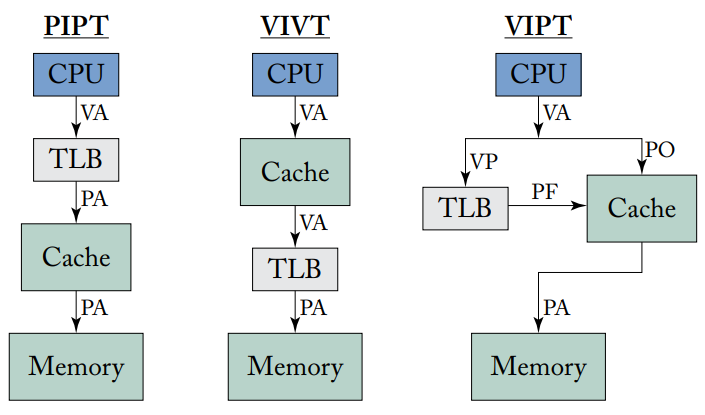
从概念上来说,现代TLB有四种不同的放置策略,如上图所示。
PIPT的好处是简单的缓存管理,在多程序的情况下可以无缝运行,很容易处理缓存一致性请求,但性能较差,因此通常只将L2缓存和LLC作为PIPT实现,在简单的嵌入式系统之外,L1缓存通常不会被实现为PIPT。
VIVT则可以不经过TLB而直接访问缓存,提高了性能,但也引入了一系列的问题,需要复杂的的硬件结构来解决。首先,TLB在缓存命中时不被查询,也就是说VIVT缓存不容易检测到内存访问违规并触发异常,这样的非法访问要么永远不会被捕获,要么只有在该行被evict的时候才会被捕获,一个解决方案是即使VIVT缓存命中时也要访问TLB,这需要在指令提交前完成,但不一定要在执行的时候完成。其次,相同的虚拟地址可能指代不同的物理地址,一个解决方法是在每个缓存行中增加PID或ASI字段,但需要增加额外的存储空间,且需要存储权限信息,并与tag和PID匹配并行查询。最后,即使在同一个进程中也存在synonym的问题。由于上述问题,VIVT缓存在通用处理器中并不十分常见。
VIPT缓存结合了上述两者的优点,关键点在于缓存查找实际上由两部分组成,首先进行索引,然后匹配tag。VPN用来查询TLB,VPO用来对缓存索引,注意在这种方式中缓存索引必须由不需要地址翻译的位来进行,其实VPO也就是PPO。这种方式的好处在于完全隐藏了TLB访问的延迟,且由于使用物理tag,避免了多程序和synonym的问题,但缺点是只能支持有限set数量的缓存,如果违反了这一规则,就会再次出现synonym的问题。一个解决方案是操作系统实现页面着色,内存分配器根据每个页面在缓存中的位置为其着色。
PIVT缓存没有存在的必要。
多种页面大小
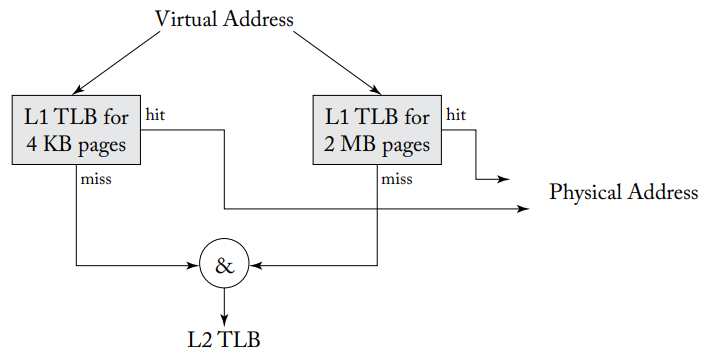
许多现代操作系统和体系结构支持多种页面大小。然而,与VIPT缓存对应的组相联TLB不能很容易地支持多种页面大小,因为查找时我们需要VPN的低位来选择TLB set,但这些位只有在页面大小确定时才能确定下来,但页面大小在TLB查找成功前都是未知的,也就是说TLB查找时需要知道页面大小,但页面大小只有查找后才能确定。
 访问不同大小的页面时查找多个TLB
访问不同大小的页面时查找多个TLB
大多数处理器采用的方法是分割TLB,如上图所示,每个页面大小一个TLB,虚拟地址可以并行查找所有TLB,根据TLB支持的页面大小,每个TLB使用不同的索引位,如4 KB、2 MB和1 GB页面,有16个set的TLB集合索引分别是15-12、24-21和33-30位。如果其中一个TLB命中,我们也就知道了页面大小,如果都没有命中,那么就访问下一级TLB。然而这种方式比较消耗能量,且分散的TLB也难以被充分利用。
页表项
本节我们重点讨论页表项中的metadata。
访问权限
页表项和TLB存储了对虚拟地址空间中每个区域的访问信息。一些架构明确提供特定的读取权限位,而另一些可能假设所有有效映射的区域都是可读的;一些架构可能提供W^X保护,而另一些把决定权留给操作系统。一些架构可能提供用户态或内核态控制状态,分别给予用户进程或操作系统访问页面的权限。
Accessed和Dirty位
这两个位对于良好的页面替换决策至关重要。
Accessed位标记最近访问过的页面,现代CPU上,PTW负责设置accessed位,访问某一页面并将其映射带入TLB前需要将accessed位置1,注意TLB本身通常不会维护accessed位。唯一重置的方式是由操作系统置0,通常用accessed位来近似LRU,定期重置accessed位。
Dirty位用来识别需要写回磁盘的数据,通常也需要在TLB中维护。注意即使TLB命中,也要通过PTW查询页表并设置dirty位。注意accessed位主要是用于性能方面,但dirty位是为了确保正常功能的实现。
ASID与Global位
如果TLB不跟踪上下文信息,操作系统切换上下文时需要完全刷新TLB的内容,在ARM和x86架构上,大范围的TLB刷新会导致高达10%的性能下降。TLB通过ASID和global位的硬件支持来减少TLB的刷新频率,上下文切换时没有必要刷新TLB,注意TLB的ASID不一定与操作系统的PID相同,前者往往位数更少,且需要操作系统跟踪ASID和软件上下文信息之间的映射。除了ASID外,global位用来识别对所有进程都是全局的转换,如内核地址空间。
PTW
英特尔Skylake L2 TLB有1536个条目和4KB页,可访问范围只有6MB,比今天典型应用的工作集小得多,因此我们也需要注意TLB缺失情况下的处理机制。
软件管理的TLB
在虚拟内存实现的早期,软件管理的TLB是很常见的,TLB缺失会触发异常,操作系统运行中断处理程序来访问页表,然后通过专用指令填充TLB。概念上来说这样实现很简单,但软件管理的TLB性能很差,每次TLB缺失都需要操作系统进行上下文切换。
硬件管理的TLB
这种方式的好处是减小了需要陷入内核态来处理页表的成本,CPU硬件维护PTW状态机来处理TLB缺失,不再需要冲刷流水线、保存上下文来进入中断处理程序。绝大多数PTW直接使用物理内存地址而不是虚拟地址来访问页表,避免了需要为页表进行虚拟到物理地址转换的尴尬问题。PTW需要知道页表的基址,因此ISA通常提供一个控制寄存器,由操作系统作为上下文切换的一部分来进行配置,如x86的CR3、ARM的TTBR0和TTBR1。缺点在于PTW状态机是硬件实现的,减少了改变页表组织的潜在灵活性。
MMU缓存
TLB不是唯一用于缓存地址转换信息的结构,为了减小TLB缺失的延迟,可以缓存多级页表前几级的页表项,一般称为MMU缓存。TLB缓存的是页表最后一级的PTE,而MMU缓存,相比之下存储的是L4、L3和L2 PTE。TLB缺失时访问MMU缓存,PTW状态机首先检查是否存在于该级的MMU缓存,在最好的情况下,如果每一级都可以命中MMU缓存,那么PTW访问的延迟是很小的。
设计MMU缓存的动机是,为前几级PTE提供缓存是有意义的,可以映射地址空间的较大部分,如x86-64标准四级分页方案中,页表的每一级分别覆盖512 GB、1 GB、2 MB和4 KB。基本的MMU缓存有很多变种,英特尔使用分页结构缓存(PSC),如下图所示,所有的PSC条目都可以并行查找,如果命中的话,最长的匹配用作PTW访问页表其余部分的起点,减少了内存访问次数并降低了延迟。
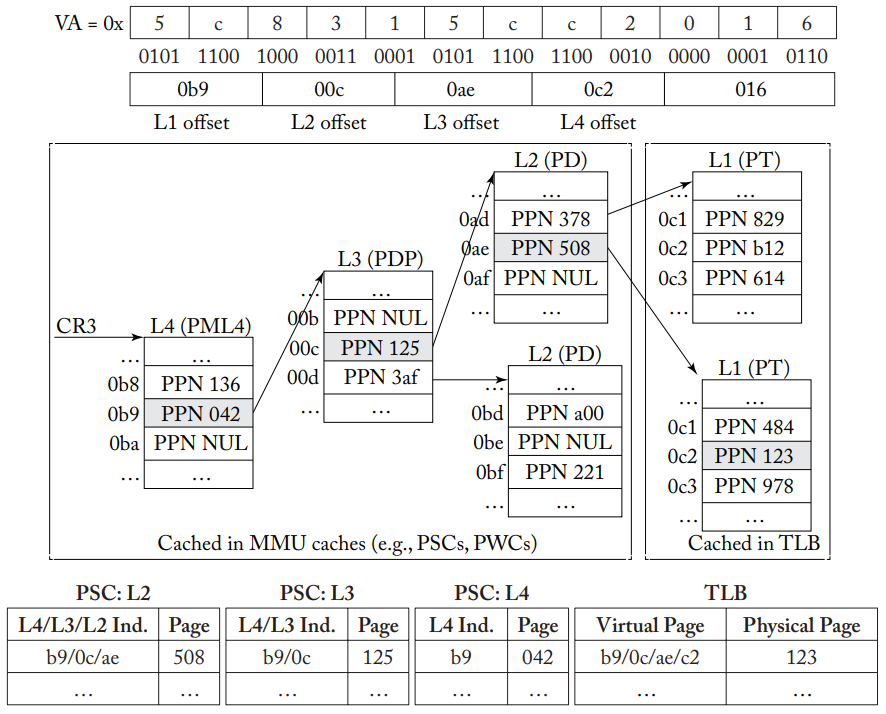 x86-64虚拟地址0x5c8315cc2016访问页表,TLB缓存L1 PTE,MMU缓存存储L2-L4 PTE
x86-64虚拟地址0x5c8315cc2016访问页表,TLB缓存L1 PTE,MMU缓存存储L2-L4 PTE
AMD则设计了页行缓存(PWC),和PSC不同的是,PWC只为每个页表级别提供专用的PIPT缓存,因此每一级都需要按顺序查找,但可能会有更低的延迟。目前MMU缓存仍然是一个活跃的研究领域。