原文:Pigasus: Efficient Handling of Input-Dependent Streaming on FPGAs.
FPGA普遍应用于各种实时流媒体应用,如信号处理、机器学习推理、视频处理等,其特点是FPGA加速的部分是与输入无关的,因而加速的性能也和输入无关,具有固定的行为和性能。相比之下,网络入侵检测和预防(IDS/IPS)则是与输入相关的,性能取决于输入。之前有大量工作使用FPGA进行IDS/IPS,但大多数情况下都遵循传统的静态和固定性能的FPGA设计,效率低且成本高,这也就是Pigasus需要解决的问题。
Pigasus主要提出的观点有:(1)对常见情况进行优化,并在系统的不同层次上处理不常见的情况,用最少资源获得最大性能(这就是计算机体系结构本科课程的第一课);(2)在编译时和运行时针对不同输入的情况进行调整,适应不同的工作负载。背后的五个关键概念是:
FPGA优先的架构:FPGA作为主要的处理单元,直接连接到100 Gbps网络端口,执行大部分数据处理,只有少数数据包(即不常见的情况)交给CPU处理。
基于快慢分离路径SRAM的TCP重组:快速路径处理有序的数据包(常见情况),慢速路径处理乱序的数据包(不常见情况),可以使用一个内存密集的数据结构来跟踪乱序数据包而不影响整体性能。
分层模式匹配:通过分层过滤器来分离不同速率下的需求,如前端的小型过滤器和输入速率一致,针对所有规则检查所有数据包(常见情况),而后端的复杂过滤器只针对部分匹配的规则检查可疑的数据包(不常见情况)。
分散的面向服务的流设计:通过分解系统,对单个流服务进行参数化,并将它们连接到一个共同的通信抽象系统上,随着部署环境的变化,用户可以在编译时轻松选择最有效的设计。
动态溢出机制:在运行时按需引入更多的计算能力,启动备用的内核(如CPU上实现的内核)以支持工作负荷的临时增加。
这五个关键概念将在接下来的章节中详细展开。
Pigasus概述
Datapath
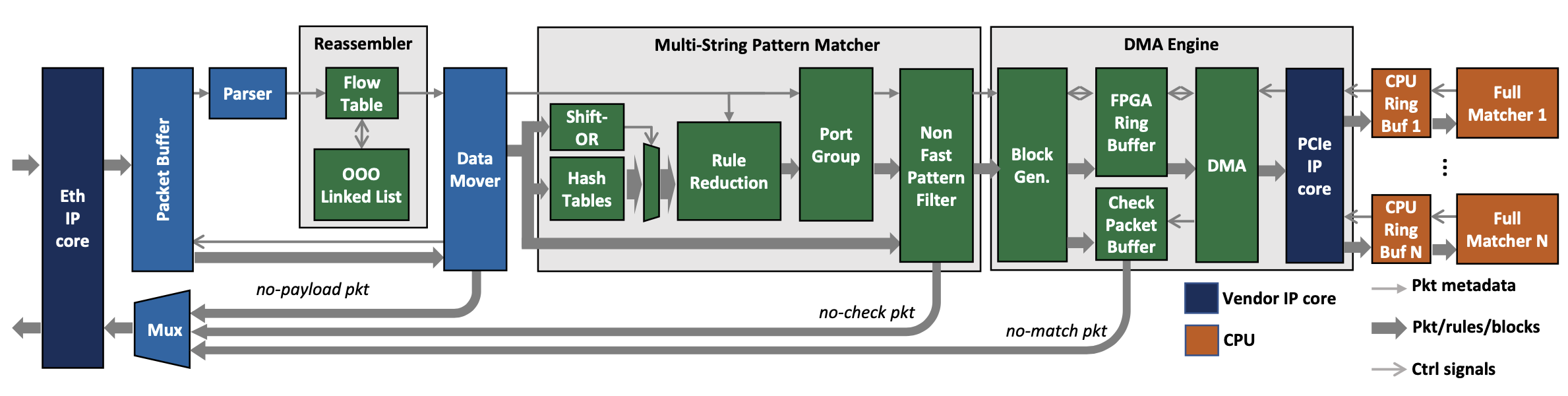 Pigasus架构
Pigasus架构
上图展示了Pigasus架构的主要组成部分,包括FPGA上的parser、reassembler、MSPM以及CPU上的full matcher,以下是工作流程。
数据包预处理:每个数据包首先经过一个100Gbps的以太网核心(Ethernet core),得到原始的以太网帧(Ethernet frames),并被暂时存储在数据包缓冲区(Packet Buffer),header被单独发送到parser(提取TCP/IP header中的metadata),然后将header转发到reassembler。
Reassembler:Reassembler按顺序对TCP数据包进行排序,以便对其进行连续扫描(即识别跨越多个数据包的匹配),不过UDP数据包不需要重组。
Data mover:Parser和reassembler只对header和metadata进行处理,而MSPM对完整的数据包进行处理,data mover从缓冲区获得原始数据包,转发到MSPM。
Multi-string pattern matcher:MSPM负责(1)根据10k条规则的header匹配检查每个数据包,(2)根据10k条规则的快速模式(fast pattern)来检查每个数据包的每个索引(every index of every packet),(3)检查部分匹配规则的非快速字符串模式(non-fast string patterns),这一部分在Snort的full matcher中,但在Pigasus放在了FPGA上。
DMA引擎:对于每个数据包,MSPM输出该数据包部分匹配的规则ID(rule ID)的集合,如果是空集,那么数据包就会被释放到网络中,否则就会被转发到DMA引擎,将数据包传输到CPU进行完全匹配。为了节省PCIe带宽,DMA引擎在FPGA侧的DRAM(检查数据包缓冲区,check packet buffer)中保留一份发送给full matcher的数据包,允许full matcher用一个(数据包ID,决策)的tuple作为响应,而不是在处理后通过PCIe复制整个数据包。
Full matcher:每个数据包都带有metadata,包括MSPM确定为部分匹配的规则ID,然后full matcher检索完整的规则并检查是否完全匹配,然后做出决策(转发或放弃)并写入一个环形缓冲区,由FPGA侧的DMA引擎轮询。
内存资源管理
BRAM仅保留给需要延迟敏感或吞吐量要求高的内存访问的模块,也就是reassembler和MSPM。具体来说,reassembler为每个数据包进行流量表的查找和更新,因此需要低延迟的内存访问以提高数据包的速率。MSPM需要高吞吐量,因为每个数据包的每个索引都必须在100Gbps的速率下与多个表(如ShiftOR表、Hash表、不同的header表等)进行检查。
为了节省BRAM,其他有状态的模块如数据包缓冲区、DMA引擎分别被分配到eSRAM和DRAM中,这些功能对带宽和延迟的要求不那么严格。
即使把BRAM全部给reassembler和MSPM,容量仍然是非常有限的,比如对MSPM使用传统的基于NFA的搜索算法需要23 MB,超过了Intel Stratix 10 MX 2100 FPGA上16 MB的BRAM容量,在后续的章节中会详述如何在不影响性能的情况下高效使用有线容量的BRAM。
评价
环境
实现:Intel Stratix 10 MX FPGA(16 MB BRAM + 10 MB eSRAM + 8 GB DRAM)+ Intel i9-9960X 16核 @ 3.1 GHz。
流量发生器:DPDK Pktgen与Moongen安装在一台单独的机器上,装有100 Gbps的Mellanox ConnectX-5 EN网络适配器。
Traces与规则集:使用公开的Snort Registered Rulset (snapshot-29141) 以及来自Stratosphere的traces来测试Snort和Pigasus。
测试吞吐量:(1)无损(Zero Loss)吞吐量是通过逐渐增加数据包生成器的传输速率来测量的,直到系统第一次开始丢弃数据包;(2)平均吞吐量为trace中数据包的累积大小(单位为bits)与处理trace所需的总时间的比值。
测试延迟:使用DPDK Pktgen的内置延迟测量程序来测量延迟。
性能与成本
具体的结论和分析可以参考原文。
FPGA优先架构
本章介绍了在端到端系统层面做出的设计决定,即FPGA优先架构,可以为常见的流量定制设计,同时实现高性能和低资源消耗。
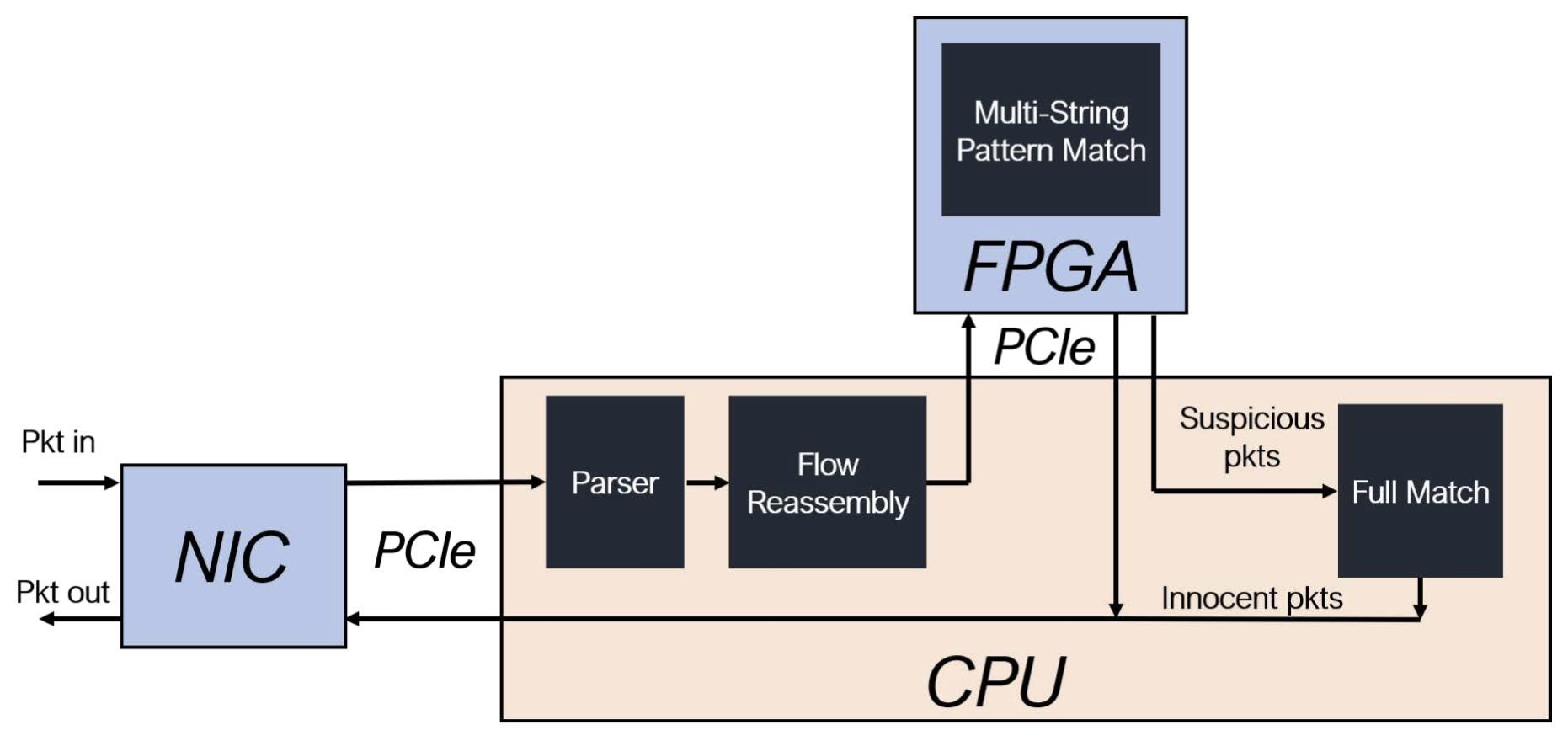 传统的FPGA-as-offload方案
传统的FPGA-as-offload方案
大多数现有的工作都采用了上图中的方案,CPU仍然是主要处理单元,FPGA作为加速器处理输入无关的单一任务,如MSPM。在FPGA优先的方案中,如下图所示,FPGA可以直接访问输入数据,并直接处理常见情况。最重要的区别在于,在这种架构中,FPGA本身也是控制单元,负责管理流量状态。
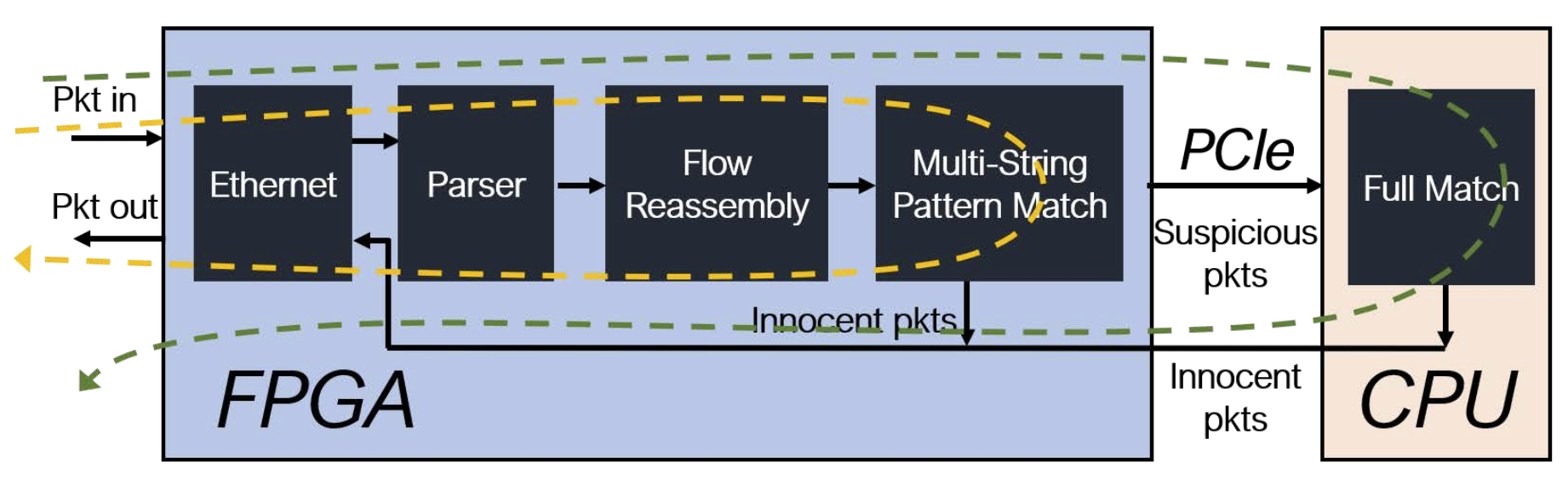 FPGA优先架构
FPGA优先架构
这种架构的好处在于可以通过只在FPGA上加速常用情况以平衡两个相互冲突的要求:高性能和低资源利用率。处理输入依赖行为的一个直接方法是为最坏的情况做准备,这样一个单一的设计可以满足所有情况下的要求,然而这种面向最坏情况的设计是不可行的,与普通情况下的设计相比,这样设计提供的性能优势很少,而且在内存方面的资源成本很高。因此,大多数工作都用FPGA加速单一任务,但如下图所示,根据Amdahl’s law,很容易看出仅仅通过加速单个任务来提升性能很难。
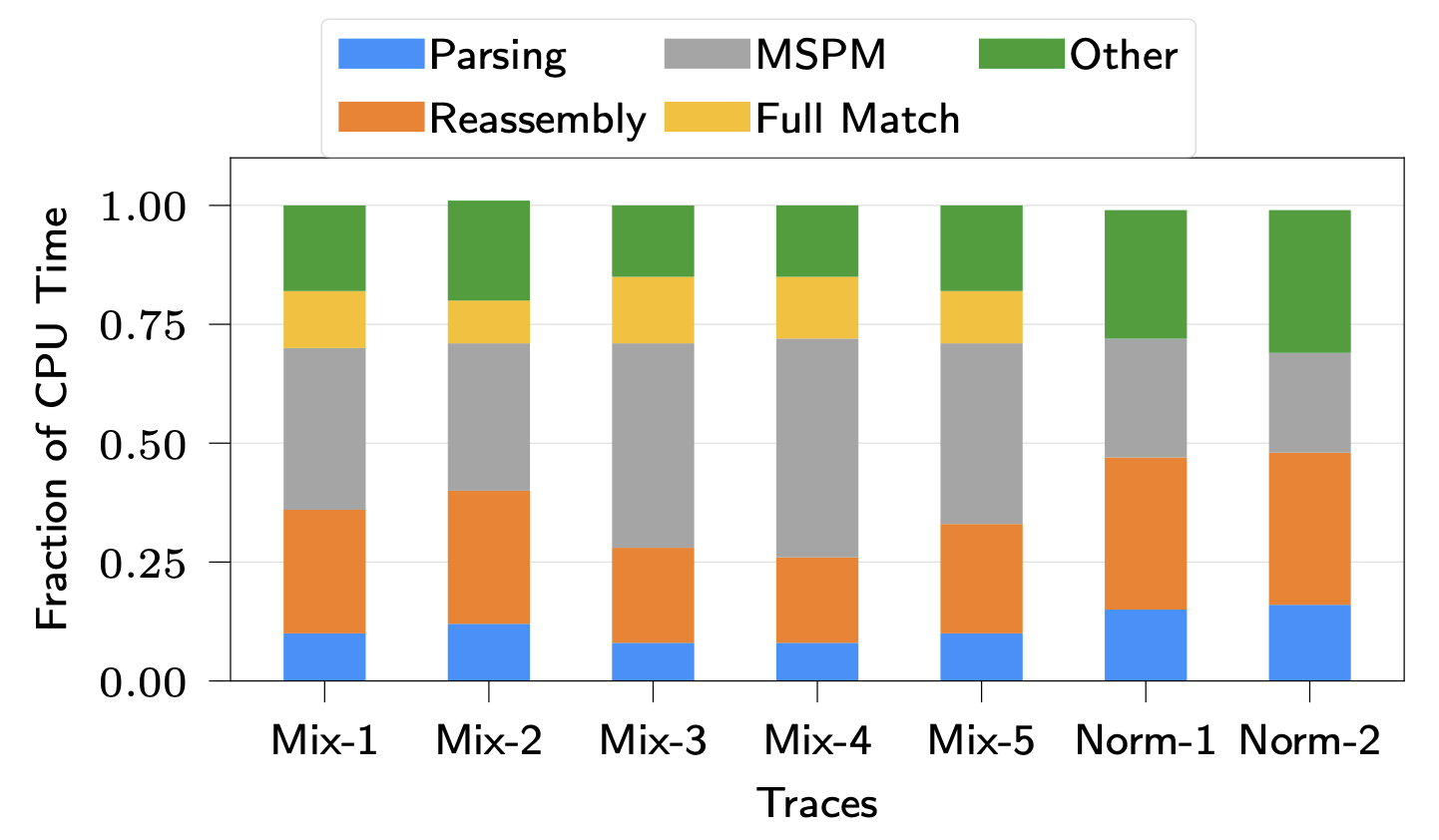 Fraction of CPU time spent performing each task in Snort 3.0 with Hyperscan
Fraction of CPU time spent performing each task in Snort 3.0 with Hyperscan
接下来的问题是,哪些任务应该留在CPU上?一般的原则是:(1)任务应该是对性能要求不高的,在CPU上运行时间很短和/或不经常被触发,(2)任务在处理流水线的末端,避免FPGA和CPU之间的多次数据移动,(3)任务在FPGA上的实现成本很高。根据这样的原则,full match可以放在CPU上执行。
基于快慢分离路径SRAM的TCP重组
上述架构要求在FPGA上支持TCP重组,本章介绍了TCP重组的要求和设计空间,以及基于快慢分离路径SRAM的设计。
设计要求与设计空间
重组是指在存在数据包碎片、丢失和乱序传输的情况下重建TCP字节流的过程。重组对于IDS/IPS是必要的,因为MSPM和full matcher必须检测可能跨越多个数据包的模式(字符串或正则表达式),如下图所示。Reassembler的关键设计目标是在FPGA的内存限制下,以100 Gbps的速度运行,对数十万个流量进行重新排序。
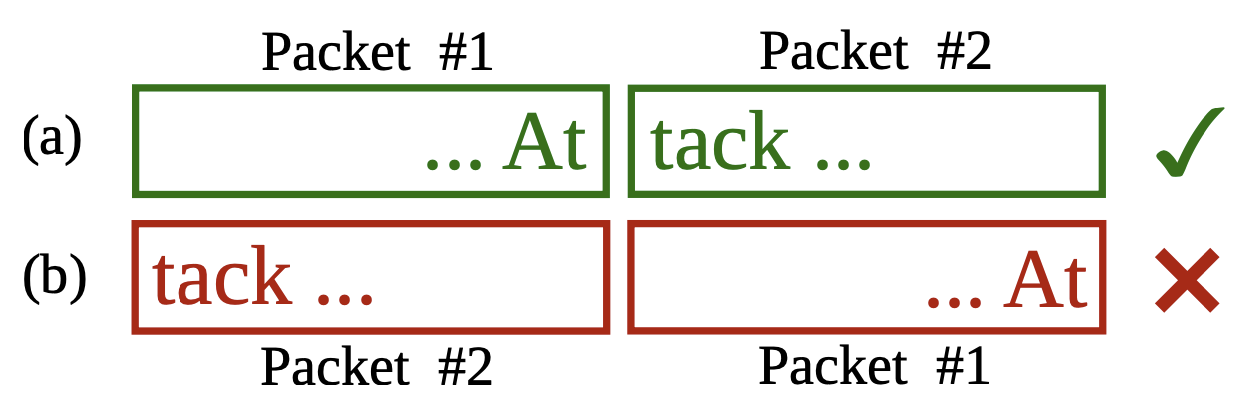 TCP重组的例子
TCP重组的例子
硬件设计通常倾向于固定长度、恒定时间和一般确定性的数据结构,大多数TCP重组设计也是如此,如采用固定的64 KB数据包缓冲区并使用指针来跟踪每个流量的乱序状态等,通过使用静态缓冲区,实现近乎恒定的时间来将乱序数据包放入内存,资源消耗也是有限制的,然而200 Gbps(读写各100 Gbps)的带宽很难用DDR4 3200来满足,需要有新的方式来缓存数据包。
一个潜在的方法是保持相同的数据结构,但开发一个具有保证双向200Gbps带宽的逻辑单地址空间存储器。我们可能可以将多个通道(每个通道都有自己的地址空间)的DRAM或甚至高带宽内存(HBM)聚集起来以获得足够的带宽,并在前面使用SRAM缓存来提供刚性的200Gbps读写带宽,以解决DRAM技术的非确定性。然而,多通道DRAM和HBM可能并不适用于很多FPGA,而且在提供有保证的性能的同时,在读写访问、不同通道和SRAM/DRAM之间进行平衡是非常 复杂的。
Pigasus最后采用了SRAM的方法,但简单地采用静态分配固定大小的缓冲区的方法是不行的,因为这种设计既浪费了空间也限制了乱序流量的情况。对软件工程师来说,可以用链表来解决,内存可以按需分配,但从硬件的角度来说,链表的插入时间是可变的,可能导致流水线停滞,降低吞吐量。不过,通过仔细设计重组流水线,分为快速路径(处理常见的顺序数据包)和慢速路径(处理不常见的乱序数据包)可以实现比较好的效果。
基于快慢分离路径SRAM的设计
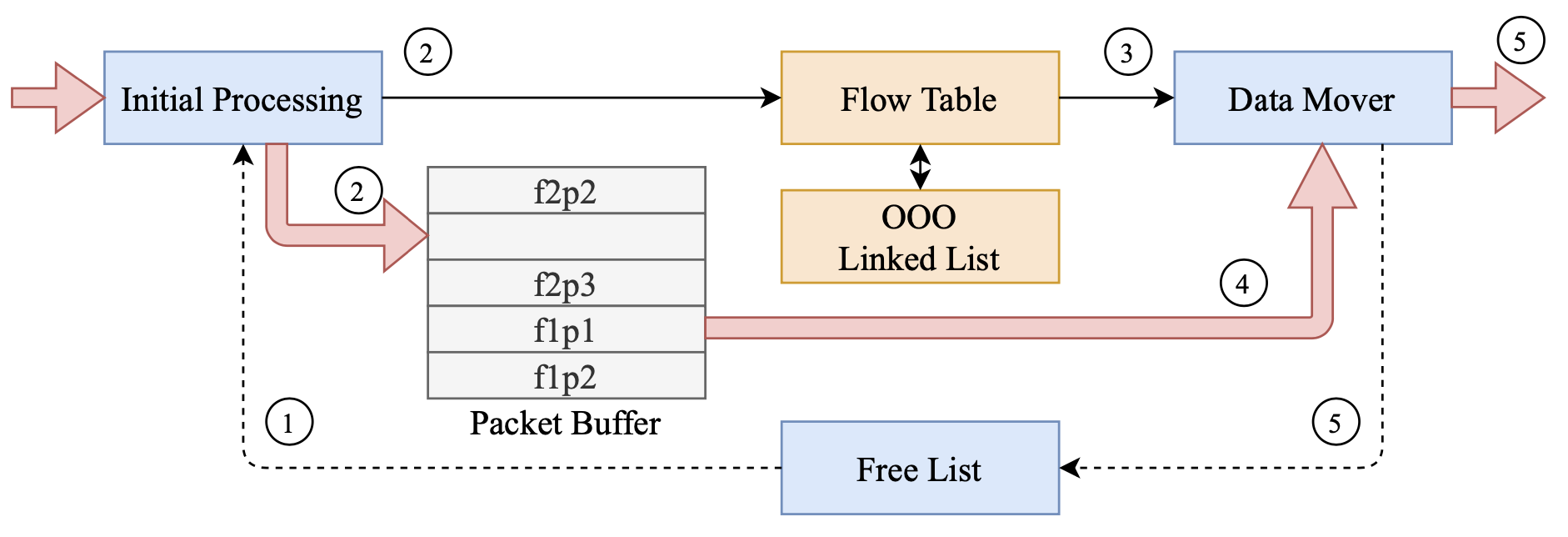 重组流程
重组流程
Reassembly流程如上图所示,具体过程如下:
从free list中获取一个未使用的数据包ID,跟踪数据包缓冲区中的空闲slot。
初始处理单元把数据包存储到2 KB的固定slot中,由eSRAM实现的数据包缓冲区中的数据包ID索引,注意数据包缓冲区是由所有流量共享的。同时,提取出来的metadata被发送到流量表。
流量表和乱序链表把分类后的数据包metadata发送给data mover。
Data mover从数据包缓冲区中根据数据包ID获取实际数据。
Data mover将数据包ID释放到free list中进行回收,并把数据包转发给MSPM阶段。
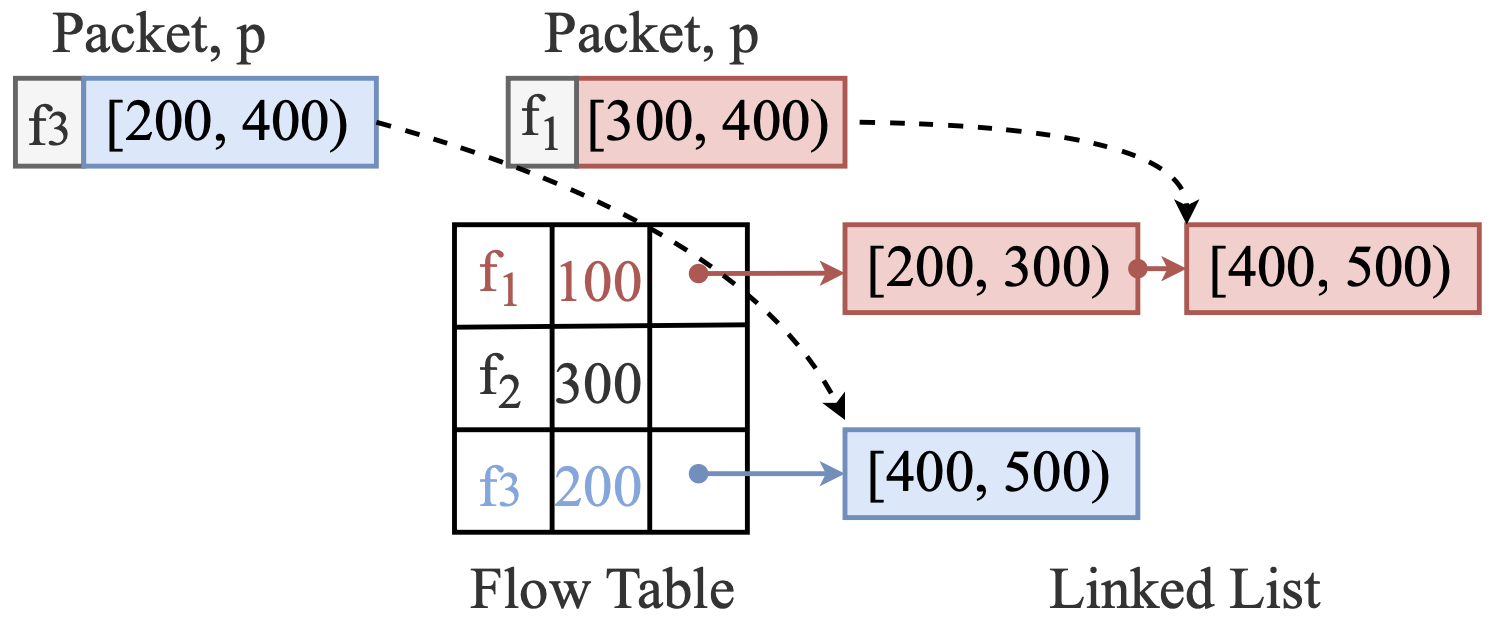 重组功能的简单例子
重组功能的简单例子
上图展示了我们处理不同数据包顺序的情况。流量表是一个在BRAM中实现的哈希表,将流量五元组标识符映射到一个包含(1)顺序数据包的下一个期望seq序号、(2)链表header节点的指针的表。注意乱序链表是在一个单独的BRAM中实现的,空间由所有的流量动态共享。
Pigasus使用三个执行引擎来管理重组状态。每个引擎处理不同类别的输入数据包的metadata:快速路径为已建立的流量处理有序的数据包,插入引擎为新流量处理SYN数据包,乱序引擎为现有流量处理乱序数据包。由于Pigasus是在硬件中实现的,这些引擎可以同时运行在不同的数据包metadata上,而不会互相停顿,但必须注意在获取重组流量表中的共享状态时不要发生冲突。下图展示了重组过程的流水线。
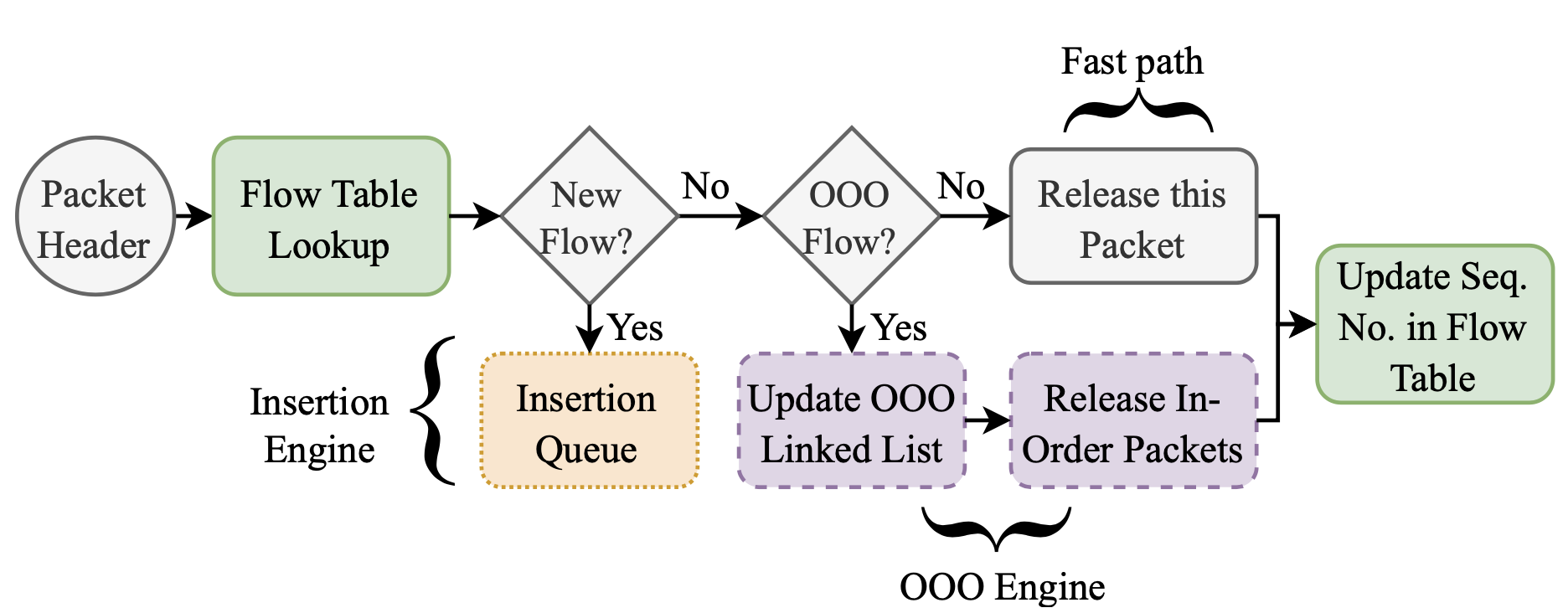 重组流水线
重组流水线
快速路径:首先在流量表中查找该流量的条目,如果不存在就将metadata放到插入引擎的队列中,如果存在,那么若metadata与流量表中下一个预期seq序号不匹配,或流量表中指针非空,快速通道就将metadata推送到乱序引擎的队列中,其余情况就将流量表中的预期seq序号更新为流量中后续数据包的seq序号,并将当前数据包送给MSPM。这一过程的时间是恒定的。
乱序引擎:乱序引擎的时间不恒定,对于每个刚刚进入队列的数据包,乱序引擎分配一个新的节点,代表数据包的开始和结束序号,遍历该流量的链表,并在适当的位置插入新分配的节点,还有一些具体的实现细节可以参考原文。
插入引擎:向流量表插入新的流量条目,时间也不恒定。
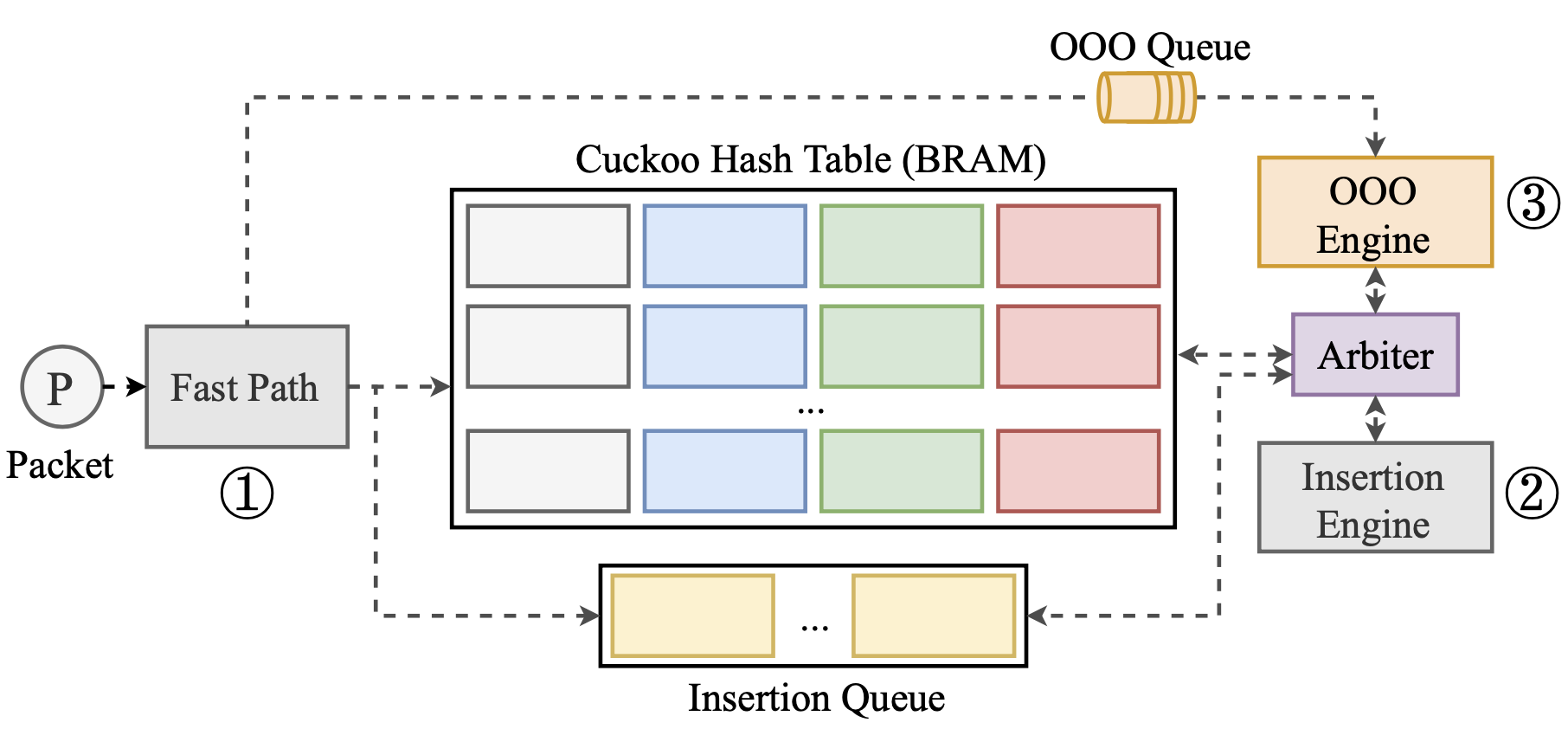 流量表与乱序引擎
流量表与乱序引擎
流量表的实现也比较复杂,快速路径、插入引擎和乱序引擎需要在流量表上进行同步,上图展示了流量表的数据结构,提供了很高的内存密度。具体的实现细节可以参考原文。
分层模式匹配
本章介绍了如何为常见情况进行优化,在FPGA上只用3.3 MB的BRAM实现MSPM并达到100 Gbps的性能。通过分层过滤器来分离不同速率下的需求,如前端的小型过滤器和输入速率一致,针对所有规则检查所有数据包(常见情况),而后端的复杂过滤器只针对部分匹配的规则检查可疑的数据包(不常见情况)。
MSPM
一个Snort规则包括三类模式:header匹配、精确字符串匹配的集合、一组正则表达式。如果所有模式都被识别,一个数据包就会触发规则。在Snort中,MSPM负责检查header匹配和一个高度选择性的精确字符串匹配,称为快速模式。只有两个同时匹配的字符串才会转发到完全匹配阶段,称为非快速字符串模式。Pigasus的MSPM检查快速模式、header和非快速模式,减少了完全匹配对CPU的负荷。
现有的设计有经典的基于状态机的FPGA设计和基于哈希表的软件设计(Hyperscan)。
基于状态机的FPGA设计:分为DFA和NFA,类似于编译原理课程中的概念,用FPGA实现,但最多只能适用于几百条规则,对内存和逻辑资源的要求很高。
Snort 3.0 + hyperscan软件设计:如下图所示。首先检查header匹配,然后检查快速字符串匹配模式,这一过程中会利用SIMD进行优化,相比状态机方法大幅提速。具体的实现细节可以参考原文或Snort 3.0的实现。
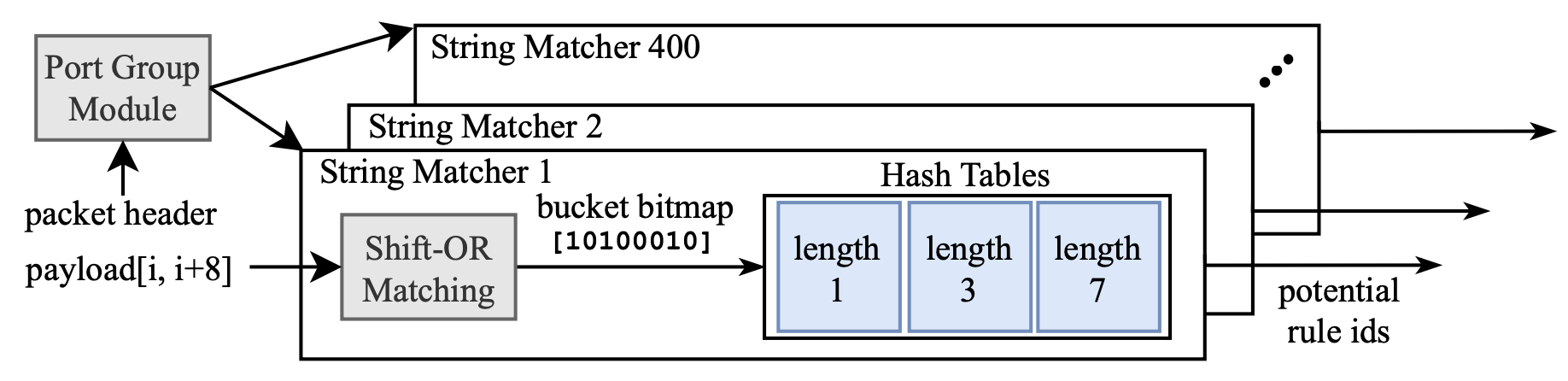 MSPM in Snort 3.0. Every String Matcher selected by the Port Group Module is evaluated sequentially.
MSPM in Snort 3.0. Every String Matcher selected by the Port Group Module is evaluated sequentially.
分层MSPM
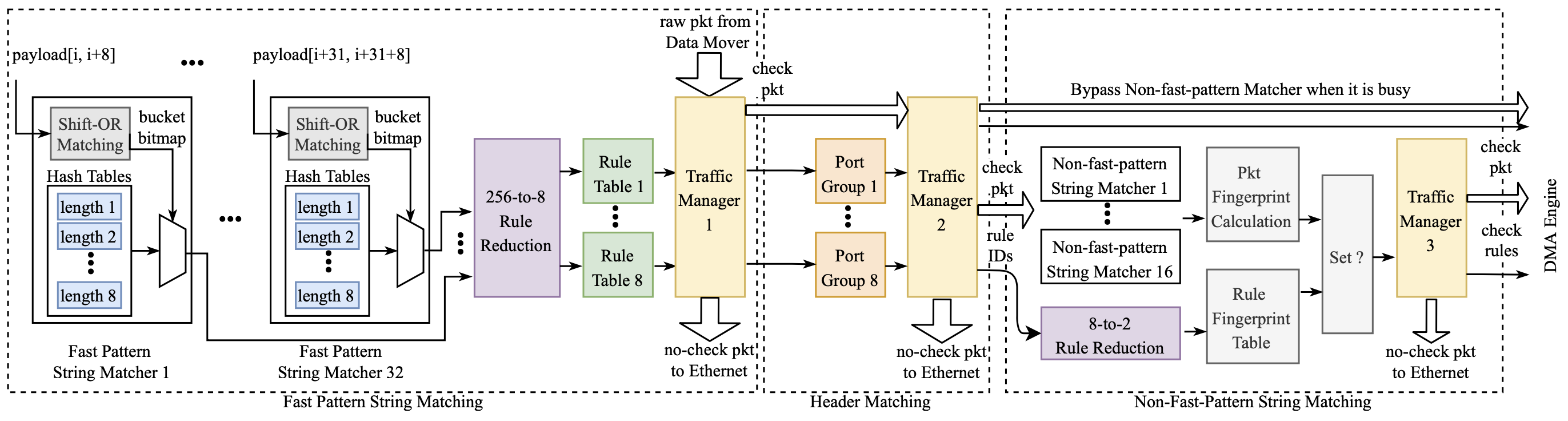 Pigasus的MSPM,共计消耗3.3 MB BRAM
Pigasus的MSPM,共计消耗3.3 MB BRAM
如上图所示,Pigasus首先从字符串匹配开始,然后再进行header匹配(端口分组)。
快速模式字符串匹配(Fast Pattern String Matching, FPSM)
类似Hyperscan,Pigasus也有一个过滤阶段,数据包会穿越两个并行的过滤器:一个Shift-or匹配器和一组快速模式长度的哈希表,并行检查Shift-or和32x8的哈希表,哈希表只存储一位的值,表示一个给定的 (index, length) 元组是否导致匹配,但是不存储规则ID。之后的规则归纳模块从过滤器的256项输出中选择非0的规则匹配,缩小到8项,如下图所示。具体来说,规则归纳逻辑是一个二分仲裁树,每个仲裁器前都有一个存储单个条目的缓存。
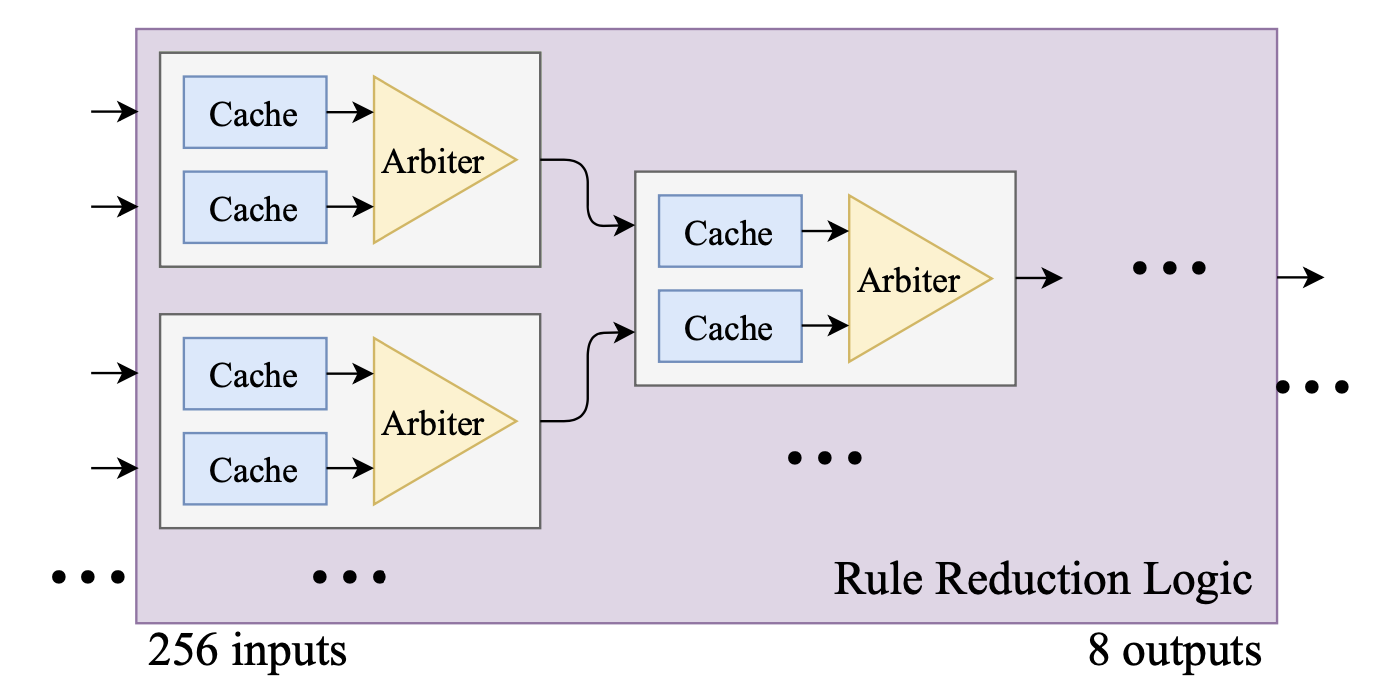 规则归纳逻辑(Rule reduction logic)
规则归纳逻辑(Rule reduction logic)
在这个过程之后,只需要为17 KB的规则表创建8个副本,对之前的输出在规则表中查找相应的规则ID,如果没有触发瑞和规则就直接转发到以太网,否则就进入下一阶段的过滤器。
header匹配(HM)
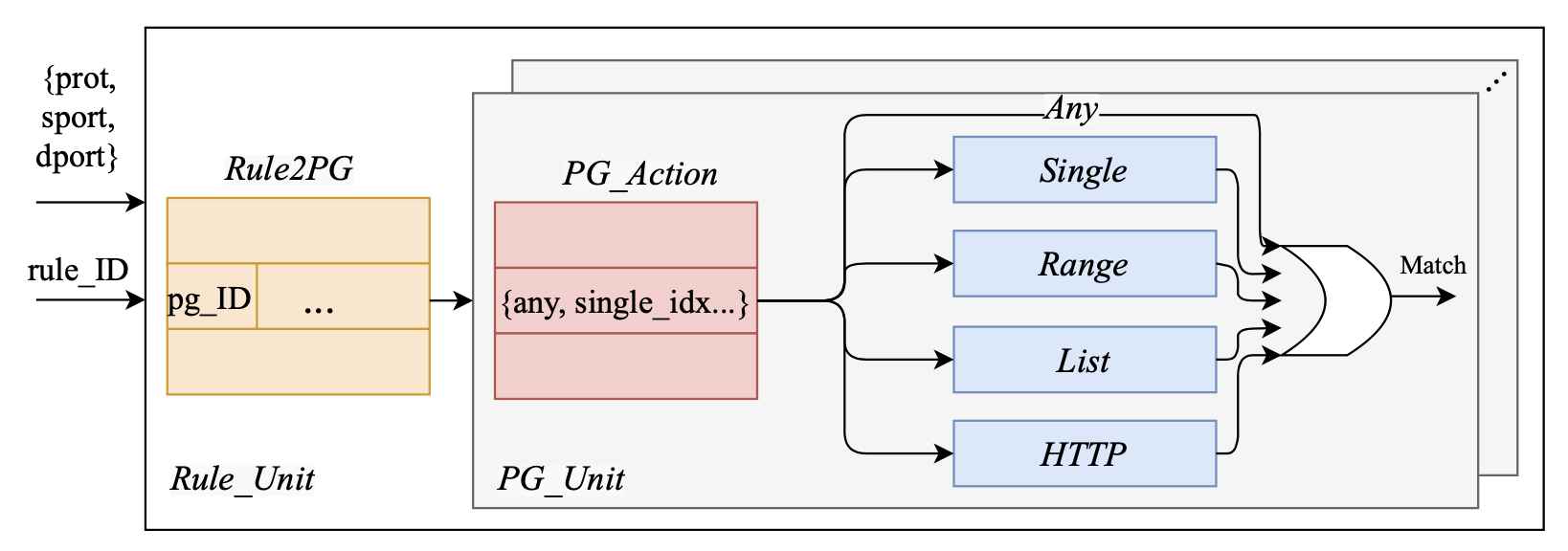 Header匹配设计
Header匹配设计
在这个阶段,我们使用header数据来确定FPSM阶段产生的匹配是否与相应的规则的端口分组一致,上图展示了header匹配的设计,每个规则单元用一个规则ID来匹配数据包的 (protocol, src port, dest port),规则ID用来索引Rule2PG表,该表最多返回4个端口分组ID(因为一个规则最多属于4个端口分组)。端口分组ID用来选择相关的PG单元,每个PG单元内查找一个特定的表。最后,所有的并行查询结果被合并,以产生最终的匹配结果。
非快速模式字符串匹配(NFPSM)
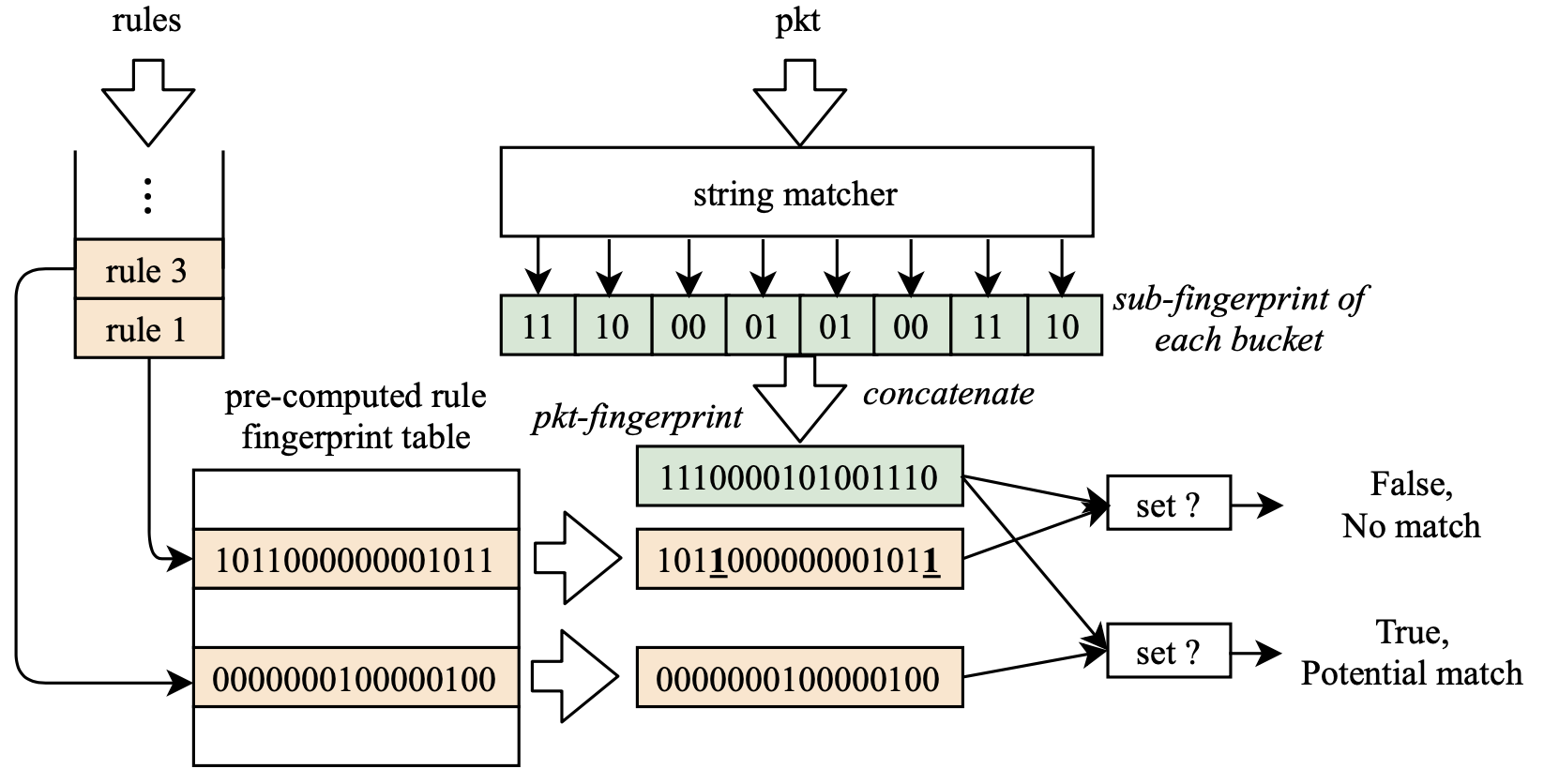 NFPSM中的规则匹配指纹
NFPSM中的规则匹配指纹
和FPSM一样,Pigasus采用一组哈希表来同时检查所有字符串,为匹配的字符串创建一个“指纹”,与规则指纹表中的指纹进行匹配,如上图所示。
分散的面向服务的流设计
之前已经有多个新的想法来提高系统不同层次的性能,同时使一组给定输入的资源消耗最小。虽然这些定制化对于高效率来说是至关重要的,但也会导致对输入的过度拟合。因此,Pigasus提出了一个分解和动态的架构,本章重点讨论分解问题。Pigasus 1.0是专门针对单一输入速率(100 Gbps)、特定FPGA(Intel Stratix 10 MX)和特定trace(Stratosphere)的一次性设计,而Pigasus 2.0是一个设计模板,允许用户便捷地重新构建一个分解的、可参数化的流服务库。
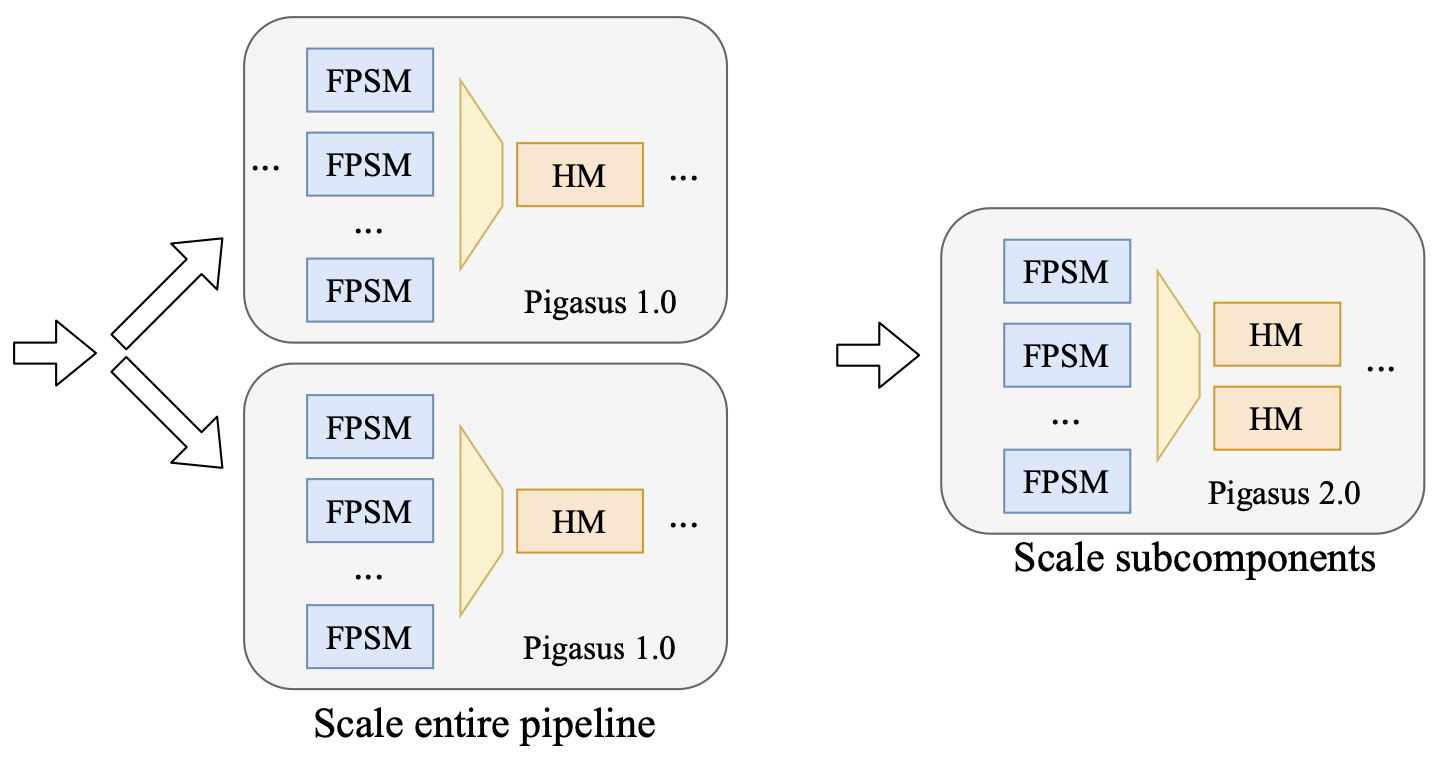 如果需要扩展header匹配器,Pigasus 1.0需要扩展整个流水线,而Pigasus 2.0只需要扩展其中一小部分
如果需要扩展header匹配器,Pigasus 1.0需要扩展整个流水线,而Pigasus 2.0只需要扩展其中一小部分
Pigasus最初的动机只是为了有效地处理不同的输入,但在这里反而提出了一个更普遍的问题:如何在不事先了解部署环境(包括输入、目标FPGA和目标性能)的情况下设计Pigasus,同时允许用户在编译时轻松地重新调整设计,以获得高效率。之前类似的工作包括分层模块化设计、IP开发、设计抽象化。Pigasus解决方案的三个关键部分包括分解、参数化和通信抽象。
 Pigasus 2.0架构,流服务通过一个共同的通信抽象进行逻辑连接,通信抽象的RTL实现是在编译时自动生成的
Pigasus 2.0架构,流服务通过一个共同的通信抽象进行逻辑连接,通信抽象的RTL实现是在编译时自动生成的
分解
将设计分解成小块后,用户可以按每个IP的粒度进行扩展,从而用更少的资源达到目标性能。如果分解得太少,我们就不太可能获得预期的效率,如果分解得太多,那么标准化接口的开销就会变得很明显,也会使用户难以理解。为了平衡,遵循以下三个原则:
扩大规模的最小单位:每个流媒体服务都应该是可以扩展的最小单位,如只想扩展header匹配的性能,扩展整个MSPM太大,分解到某一个子表则太小,根据这一原则将MSPM分为3个独立的服务,即FPSM、HM和NFPSM。
封装对延迟敏感的部分:不应该破坏任何对延迟敏感的部分,如eSRAM有固定的响应周期,使用eSRAM的data mover应该和数据包缓冲区以及重组逻辑封装为Pigasus 2.0中的一个更大的重组服务。
对外暴露相同的标准接口:Pigasus采用了Avalon流接口,可以很容易适应其他标准,如AXI接口等,下面的代码给出了一个服务的接口,每个服务包括数据包通道、metadata通道、用户数据通道。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
module example_service (
// Input packet data
input logic [511:0] in_pkt_data,
input logic in_pkt_valid,
input logic in_pkt_startofpacket,
input logic in_pkt_endofpacket,
input logic [5:0] in_pkt_empty,
output logic in_pkt_ready,
// Input metadata
input metadata_t in_meta_data,
input logic in_meta_valid,
output logic in_meta_ready,
// Input user data
input logic [511:0] in_usr_data,
input logic in_usr_valid,
input logic in_usr_startofpacket,
input logic in_usr_endofpacket,
input logic [5:0] in_usr_empty,
output logic in_usr_ready,
// Output direction is omitted for simplicity
)
参数化
通过SystemVerilog参数和基于Python的Jinja2模板的组合来实现的。例如,MSPM中的许多子模块(如哈希表、规则归纳等)都是在Jinja2模板中编码的,这些模板生成最终的SystemVerilog文件。原文给出了一些关键的可调参数及其影响。
通讯抽象
Pigasus提出了一个通信抽象,所有的服务都被逻辑连接到一个共同的抽象上,在高层次组合各种服务,编译器负责生成RTL,不损失效率的同时,提供了更好的可移植性、设计效率和可调试性。
不同的通道实现:通信抽象提供了服务间通信通道的不同物理实现,如FPGA内部(NoC)或FPGA之间(以太网或PCIe)的通信,用户只需要在Python级别选择适当的服务通道类型,不需要关心RTL实现细节。
负载平衡:通信抽象在内部提供了负载平衡服务,允许用户简单地创建副本,而不必关心负载分配和结果的合并。
调试:当数据在内核之间流动时可以收集统计数据,以供用户快速识别性能瓶颈或定位功能错误。
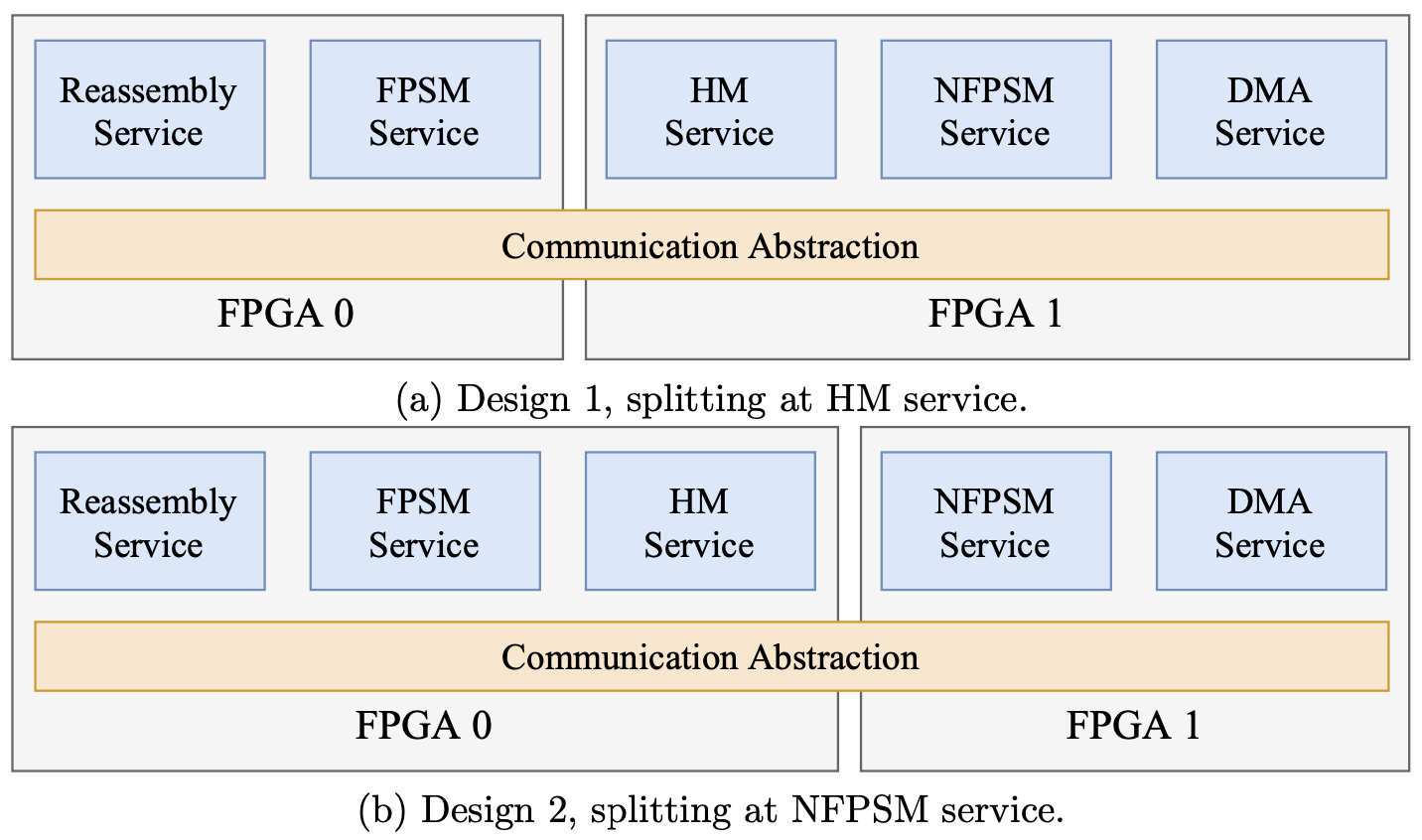 在多FPGA系统上使用共同通信抽象探索不同的流水线分割方式
在多FPGA系统上使用共同通信抽象探索不同的流水线分割方式
动态溢出机制
在编译时准确地预测实际工作负载在运行时的行为是非常困难的。因此,在编译时做出的设计决定很可能是不完美的,可能配置不足从而损失了性能,或过度配置从而浪费了资源。动态溢出机制可以动态地按需调出备份流服务,以吸收流量的变化。
Pigasus针对常见情况进行调整,分配足够的资源来提升常见情况下的性能,但也可能使设计在面对不断变化的工作负载时变得脆弱。处理流量突发性的典型方法是使用缓冲,但是在100 Gbps的情况下,流量中的小抖动(jitters)很容易溢出MB级别的片上缓冲空间,且由于实时处理(IPS模式)的延迟要求,我们不能无限期地缓冲流量。
以下是一个例子来说明动态溢出机制,当NFPSM作为MSPM模块的最后一个模式匹配阶段处于高负荷时,动态地将溢出的流量路由到CPU。Pigasus设计了一个溢出路径,可以将流量路由到CPU,如下图所示。调度器不断地检查输入缓冲区的占用率来监控NFPSM的负载,如果占用率超过了运行时间可配置的阈值,调度器将把溢出的流量送到DMA引擎,并分配给CPU内核。注意两个细节:当溢出发生时,NFPSM和CPU都在工作,没有完全绕过NFPSM;未被NFPSM处理的溢出流量不会破坏系统的正确性,因为CPU将对数据包进行更完全的匹配。
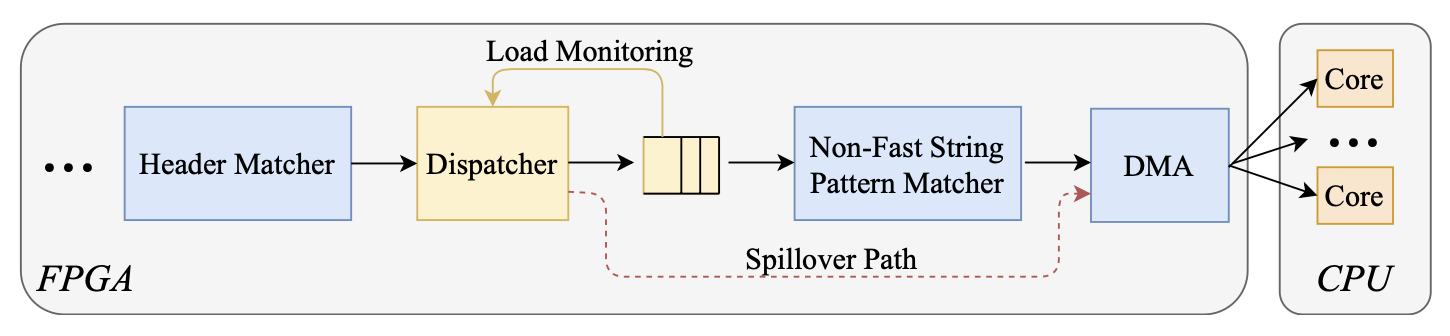 NFPSM CPU溢出设计
NFPSM CPU溢出设计
Notes
这篇笔记省略了相当多的实现细节和实验评价,但这些内容同样非常精彩,作者在原文的结论部分也给出了相当多的不足与未来工作值得学习,这篇笔记中并没有涉及,感兴趣的读者可以参考原文。另外,原文的附录给出了详细的环境配置、Pigasus构建、实验方法等内容可以参考。