在乱序流水线中,为了模拟指令的顺序执行,最常见的解决方案是在流水线的末尾实现额外的一个阶段,称为提交。在任何指令被提交之前,指令做出的任何行为都是推测性、或者叫投机性的,不会真正改变处理器的状态。通过这种方式也可以实现精确异常。
对于x86等CISC处理器,一条CISC指令可能被拆分成多条微指令,当所有对应的微指令都已经执行完成时,该条CISC指令也会随之被提交并更新处理器状态。这条规则的唯一例外是那些被分割成大量微操作的x86指令,如内存 拷贝指令,这类指令会在中途做周期性的部分提交。
最后,由于提交是指令执行的最后阶段,一条指令所分配的各种硬件资源,如重排序缓冲(ROB)条目、内存顺序缓冲(MOB)条目或物理寄存器将会被回收。
架构状态管理
架构状态包括内存状态和每个寄存器的值。
作为架构状态的一部分,内存不可以被随意修改。因此,所有的store操作都只有在真正提交之后才会把数据写入缓存或内存,在此之前,所有的相关信息都会被存放在store buffer中。所有的load操作都应该首先检查store buffer中是否有对应的数据,如果内存地址相匹配,那么应该直接从store buffer中获取数据,或者等待store buffer把数据写入缓存。
寄存器的管理则取决于重命名的方式,我们介绍两种方法:
基于ROB与退休寄存器堆(RRF)的架构状态管理,如Intel P6、Core等处理器。
基于合并RF的管理,如Intel Pentium 4、Alpha 21264、MIPS R10000等处理器。
基于RRF的架构状态
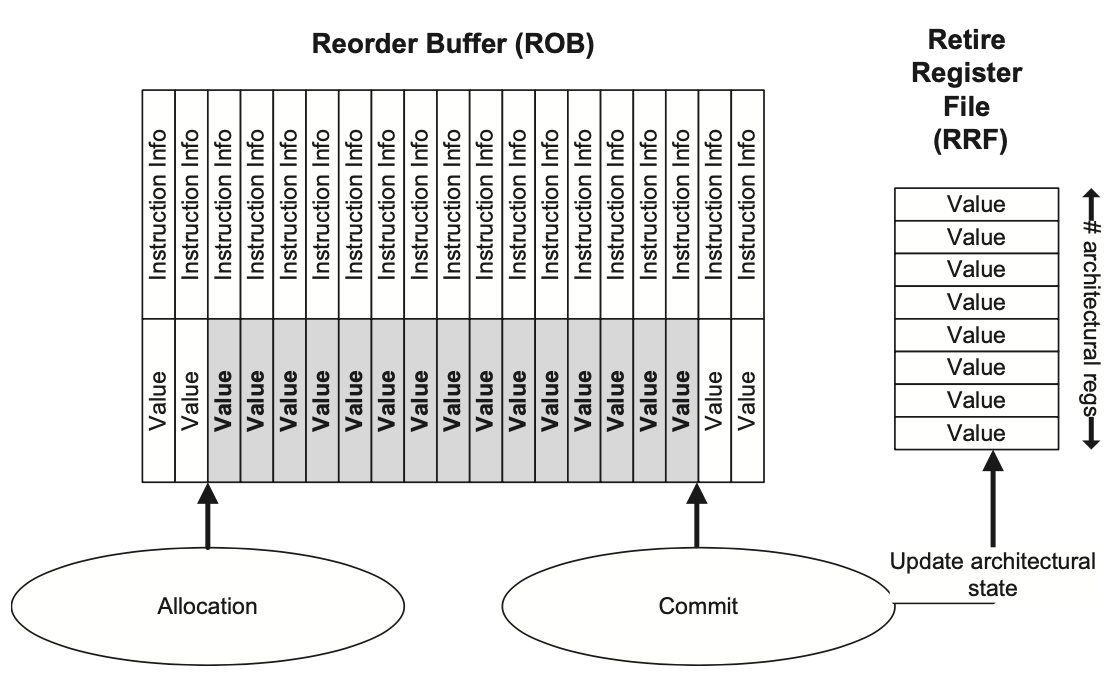 ROB与RRF
ROB与RRF
在这种重命名方式中,指令提交时会把ROB中存储的值复制到RRF中,具体的实现细节在之前的章节中已经做过细致的讨论了,这里就不再展开。
基于合并RF的架构状态
在这种设计中我们使用一个统一的物理寄存器堆,相比基于ROB和RRF的方案,这种设计有三个主要优势:
指令提交时,不需要移动寄存器值的位置。
基于ROB的实现需要为临时的值提供存储空间,但有相当一部分指令不会写回寄存器,合并RF的设计中可以更高效地使用物理寄存器堆。
ROB本身是集中式的结构,基于ROB的实现通常都是在发射前读取RF,不利于流水线不同阶段的解耦,例如在分布式的分组执行单元与寄存器堆设计中,比较适合在发射后读取RF,合并RF可以灵活选择在发射前还是发射后读取RF。
不过这种设计也更为复杂。在ROB的设计中,可以直接按FIFO顺序分配临时空间,但是在合并RF的设计中需要一个额外的空闲列表来存储可用的物理寄存器,且物理寄存器的回收也更为复杂。
推测性状态的记录
执行的指令不一定会被提交,有可能是因为分支预测错误或之前的指令触发异常。对这两种情况,应该恢复推测性的状态,撤销推测性执行的指令做出的修改。
从分支预测错误中恢复
分支预测错误的恢复通常可以分成前端恢复和后端恢复,通常前者更为简单。前者包括冲刷所有的中间缓冲区、恢复分支预测器的历史、更新PC等。后者包括清除所有属于错误路径的指令,这些指令存放在后端的各种缓冲区,包括MOB、发射队列、ROB、重命名表等,物理寄存器与发射队列条目等资源也应该被及时回收。
基于ROB和RRF处理分支预测错误
在分支预测错误时,处理器不会立刻恢复推测性的状态,而是会等到错误预测的分支指令与其之前的所有指令都被提交。此时,重命名表被恢复,并从正确的路径重新开始对寄存器重命名。
基于合并RF处理分支预测错误
分支预测错误时,处理器可以立刻进行状态恢复。处理器会保留一份日志,记录了当一条指令被重命名时,重命名表的修改方式以及这条指令分配的资源。在分支预测错误时,处理器遍历这个日志来恢复分支指令被重命名时的正确状态。该日志的每个条目包括:这条指令写入的逻辑寄存器和分配的物理寄存器、逻辑寄存器之前对应的物理寄存器。
MIPS R10000和Alpha 21264等处理器为了加速这个过程,实现了检查点机制,可以直接从检查点的指令开始遍历,实现快速分支预测错误恢复。
从异常中恢复
异常通常在提交时处理,原因有二:一是我们需要确定出发异常的指令不在分支预测错误的路径上,二是我们需要提供正确的处理器状态。