分配阶段包括两个任务:寄存器重命名和指令分派,前者的目的是消除由于寄存器的重复使用而产生的不必要的数据依赖,而后者的目的是保留一些指令执行所需的资源。发射阶段负责向FU发射指令并执行,通常可以分为顺序发射和乱序发射。
分配
如上所述,分配阶段由两大任务。首先是寄存器重命名,此处我们讨论的重命名只限于寄存器的范畴,事实上这个概念也适用于内存操作数,会在之后进一步讨论。寄存器重命名最早是在Tomasulo在上世纪60年代在An Efficient Algorithm for Exploiting Multiple Arithmetic Units中提出的,应用于IBM 360/91的浮点单元。现代处理器通常有三种重命名的方式:ROB重命名、Rename Buffer重命名与合并RF重命名。
ROB重命名
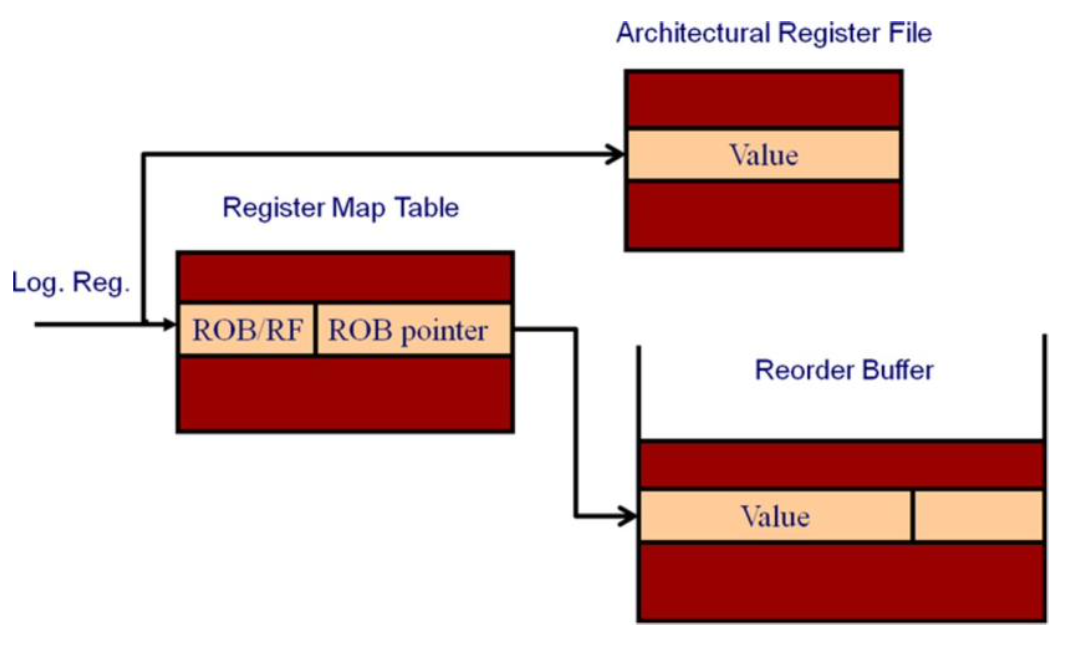 ROB重命名
ROB重命名
在这个设计中,寄存器的值既有可能存储在RF中,也可能存储在ROB中。如上图所示,Register Map Table会指明操作数应该从RF还是ROB中获取。当一条指令仍在执行时,目的操作数(即rd)的值会被存储在ROB中,在指令提交时,会把ROB中的值复制到RF中。
这一方案被Intel Core 2等处理器所采用。
Rename Buffer重命名
这个方案的动机在于,程序中有相当一部分比例的指令(大约为三分之一,但也要看具体的程序和指令集)不会写入寄存器。在之前的方案中,ROB每一行都要留出空间存储寄存器的结果,也就是说大约有三分之一的存储空间都被浪费了。这一设计的想法在于为每条正在执行的指令的结果提供一个单独的存储空间结构,也就是Rename Buffer。
和前一种方案一样,可以使用一个简单的FIFO来存储临时的寄存器数据,但也同样需要写入两次数据,第一次往Buffer里写入,第二次在指令提交时往RF写入。
这一方案被IBM Power 3等处理器所采用。
合并RF重命名
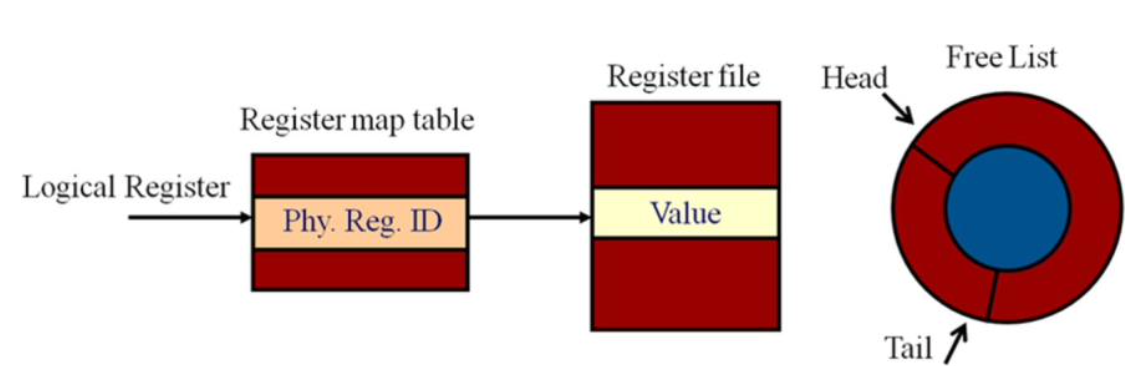 合并RF重命名
合并RF重命名
在这个设计中,只有一个单独的物理寄存器堆来存放所有的寄存器值,每个寄存器都有一个状态(空闲或者被分配,也可以有更多的状态)。空闲寄存器被记录在空闲列表中,寄存器映射关系被记录在映射表中,具体的组织结构如上图所示。
在重命名阶段,我们首先查找映射表,找到rs1和rs2对应的物理寄存器。如果这条指令还需要写回寄存器,我们会从空闲列表中找到一个空闲的物理寄存器,分配给rd并写入映射表。如果没有空闲的寄存器,就需要停顿流水线。
这一设计的优势在于寄存器只需要被写入一次,且源操作数的值来自单一的RF,省去了往ROB或Rename Buffer寻找的过程,缩小了连线的面积。
这一方案被Alpha 21264、MIPS R12000、Pentium 4等处理器所采用。
读取RF
什么时候读取RF也很重要,会对设计的几个关键部分有重要影响,通常有两个选择:发射前读取和发射后读取。
发射前读取:注意到指令发射时,可能并不是所有的源操作数都已经准备好了,这些操作数需要通过旁路网络获得。这种设计的优点在于RF需要的端口比较少,但缺点在于发射队列需要存储寄存器的值,面积较大,且需要不断的移动数据,功耗较高。
发射后读取:和前一种设计相反,这种设计要求RF有更多的端口,但操作数被读取一次就不用再反复挪动了。
理论上,这两个选择和重命名方案是正交的,但也有一些需要考虑的“协同作用”,使得有些组合非常常见。比如说,ROB重命名或Rename Buffer重命名通常会和发射前读取共同使用,具体的原因如下。
In particular, the challenge comes from the fact that the register values eventually move from one location (reorder buffer or rename buffer) to another (architectural register file). In the read- after-issue scheme, the issue queue stores the identifier of the source operands. If when an instruc- tion is renamed, a source operand is in the reorder buffer or the rename buffer, the issue queue will store a pointer to that location. If the instruction that produces this source operand commits before the operand is read by the consumer, the value will be moved to the architectural register file, and the pointer stored in the issue queue will not be correct anymore, since this entry may be allocated by a different instruction. In order to correct it, it would be necessary to do an associative search in the issue queue for every committed instruction to check if any entry is pointing to its destination register. If this is the case, the pointer should be changed to the corresponding architectural register file entry. All of this is very complex in hardware. The associative search is similar to the wakeup logic described later and, on top of that, additional write ports would be required to store the new pointer. Because of this, processors that use renaming through the reorder buffer or through the rename buffer normally opt for the read-before-issue scheme.
发射
顺序发射
顺序发射逻辑有时可以在解码阶段一并实现,通常使用Scoreboard实现,存储数据依赖和可用资源,前者对每个寄存器都存储了一个状态,表明该寄存器是否可用,后者记录了FU是否空闲,有些资源如加法器或Pipelined的乘法器总是空闲的,但有些资源如多周期的除法器则不一定。
乱序发射
发射逻辑决定了乱序处理器是否可以高效利用指令级别并行性(ILP),一旦源操作数可用,就立即把指令发射到对应的FU中。由于其功能的复杂性,实现一个高效且不影响关键路径的发射逻辑是非常重要的。
此处我们讨论那两种单一发射队列的设计,即发射前读取RF和发射后读取RF,我们假设采用合并RF重命名方案。除了单一发射队列之外也有其他的方案,如分布式发布队列。
发射前读取RF的发射过程
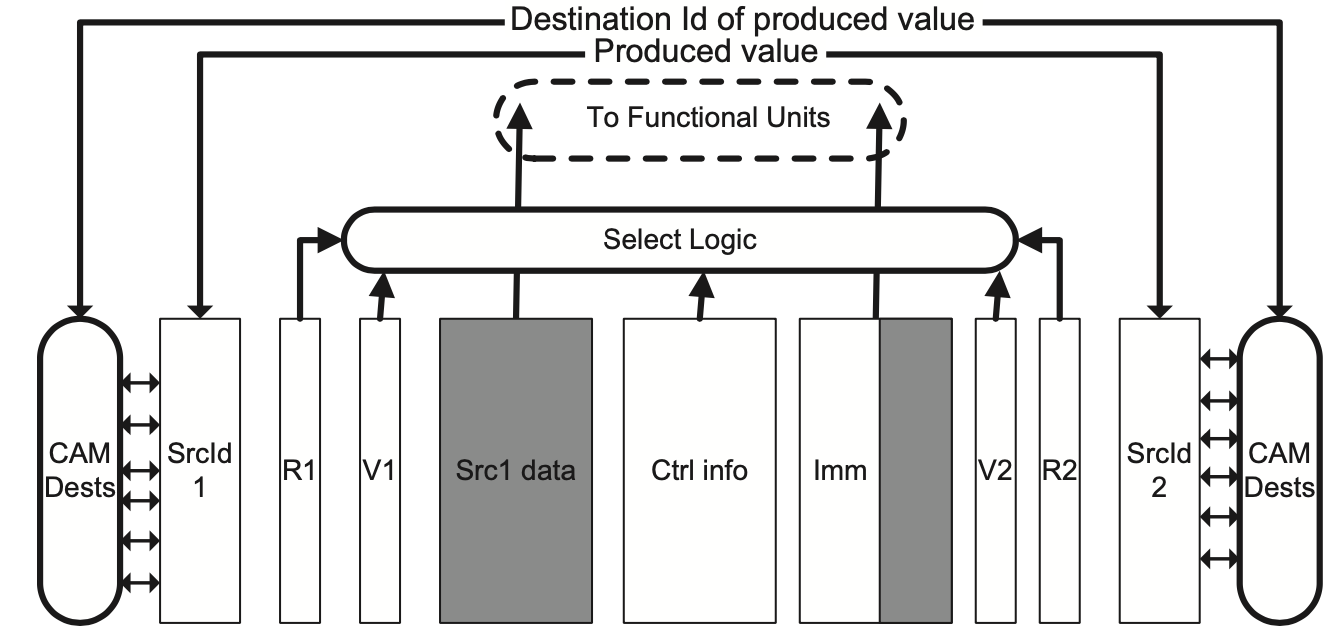
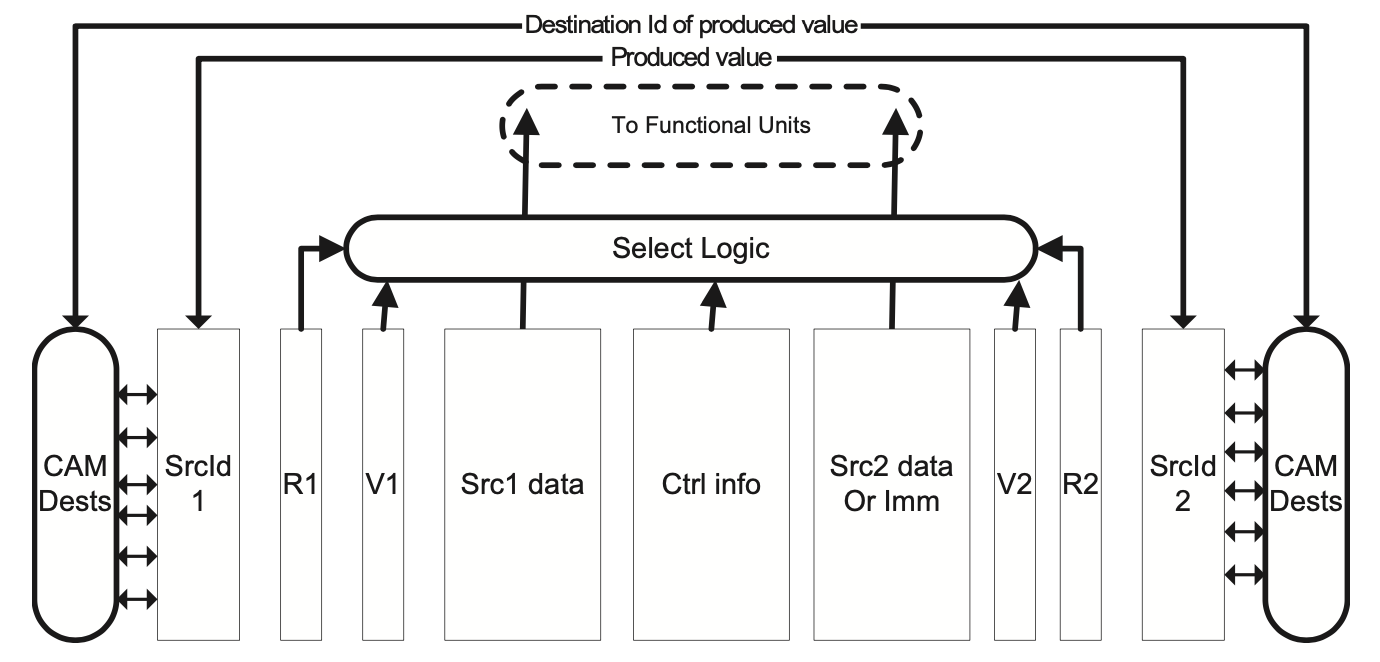 发射前读取RF发射队列的硬件组成
发射前读取RF发射队列的硬件组成
上图中每一个矩形都代表了一个表,行数等于发射队列中容纳的指令数量。我们假设采用RISC,最多可以有两个源操作数或一个源操作数加上一个立即数。Ctrl info保存了控制信号(如使用什么ALU、访存指令数据大小、是否使用立即数等),R1和R2表示两个源操作数是否已经可用,如果两个都为1,那么这条指令就可以发射了。接下来我们讨论具体的发射逻辑,包括发射队列分配、指令唤醒、指令选择和发射队列回收。
发射队列分配
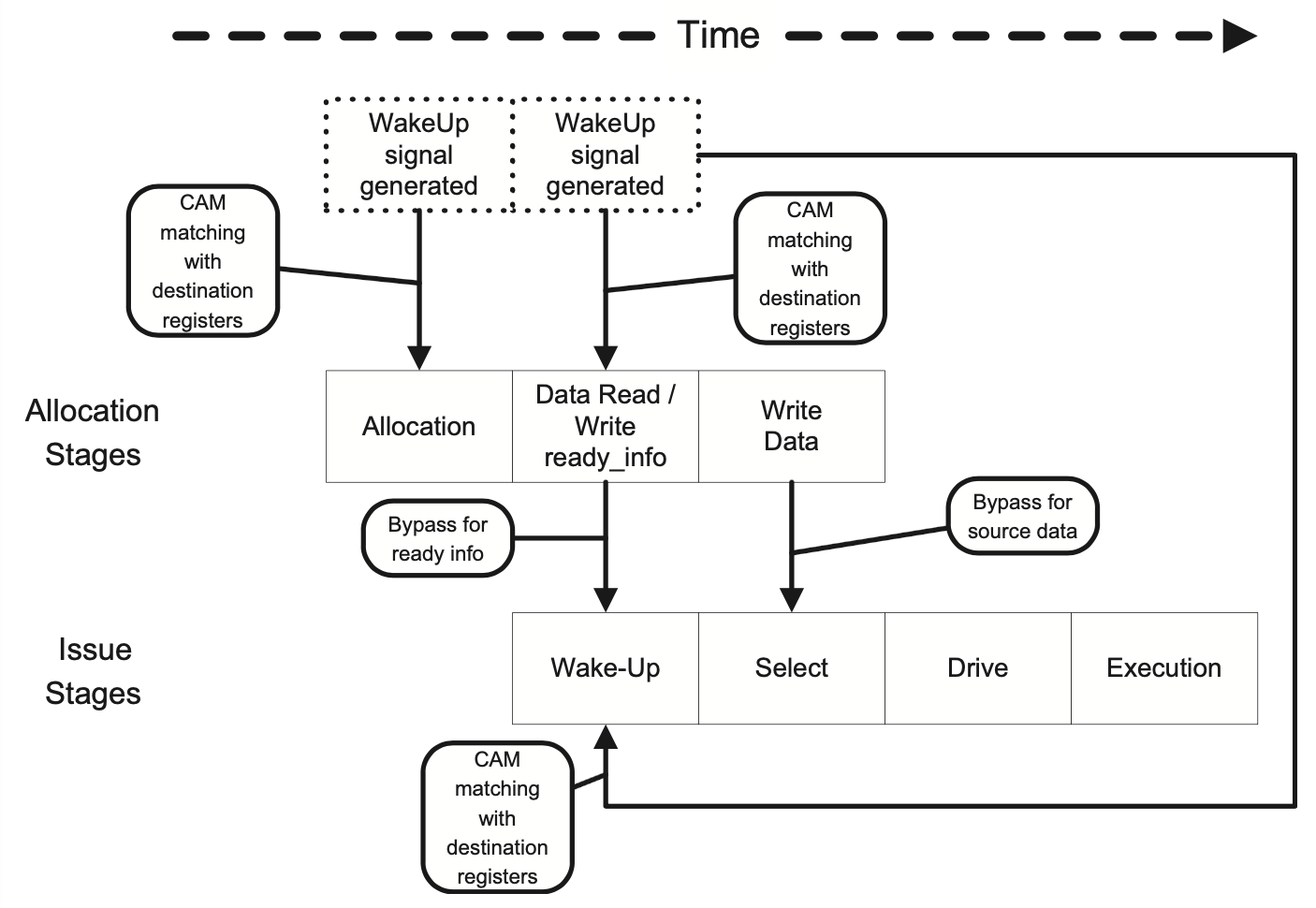 发射前读取RF发射队列的流水线设计
发射前读取RF发射队列的流水线设计
指令首先在分配阶段会被分派到发射队列,如果没有空闲的行,分配阶段就会停顿。接下来在下一个周期,指令访问寄存器堆。最后重命名后的指令被放入发射队列,并附上重命名相关的控制信号。
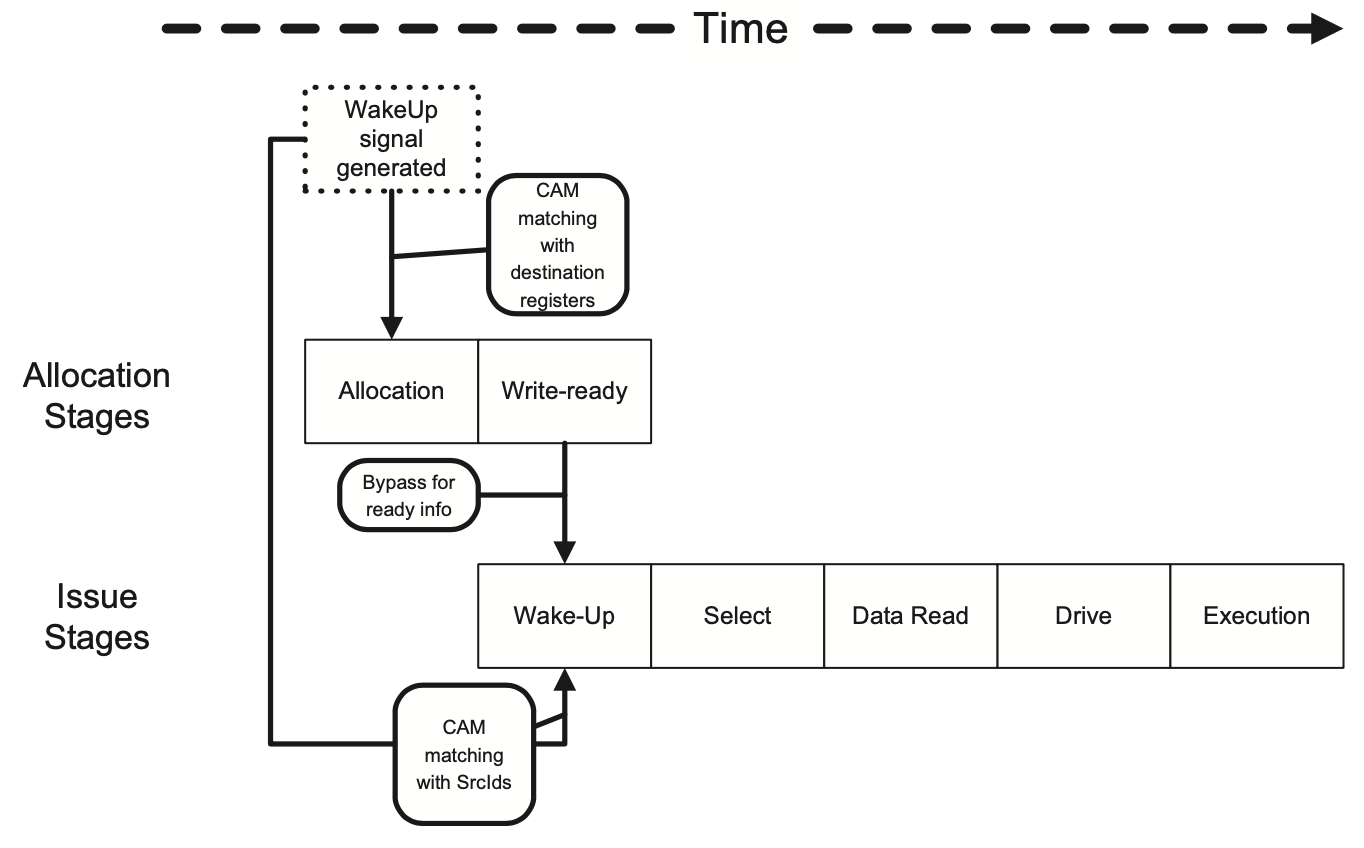
指令唤醒
唤醒是通知发射队列哪些源操作数已经准备好的一个事件,通常包括目标寄存器的物理寄存器ID、寄存器值以及一个有效位。CAM会把ID和发射队列中的每一个寄存器ID匹配,并设置相应的Ready位、把数据放到对应的位置中。这其中可能有一些细节需要处理,如对于发射前读RF的设计通常在重命名和发射队列分配之间要有一个额外的时钟周期,否则会产生死锁,具体的细节可以参考原书第6章。
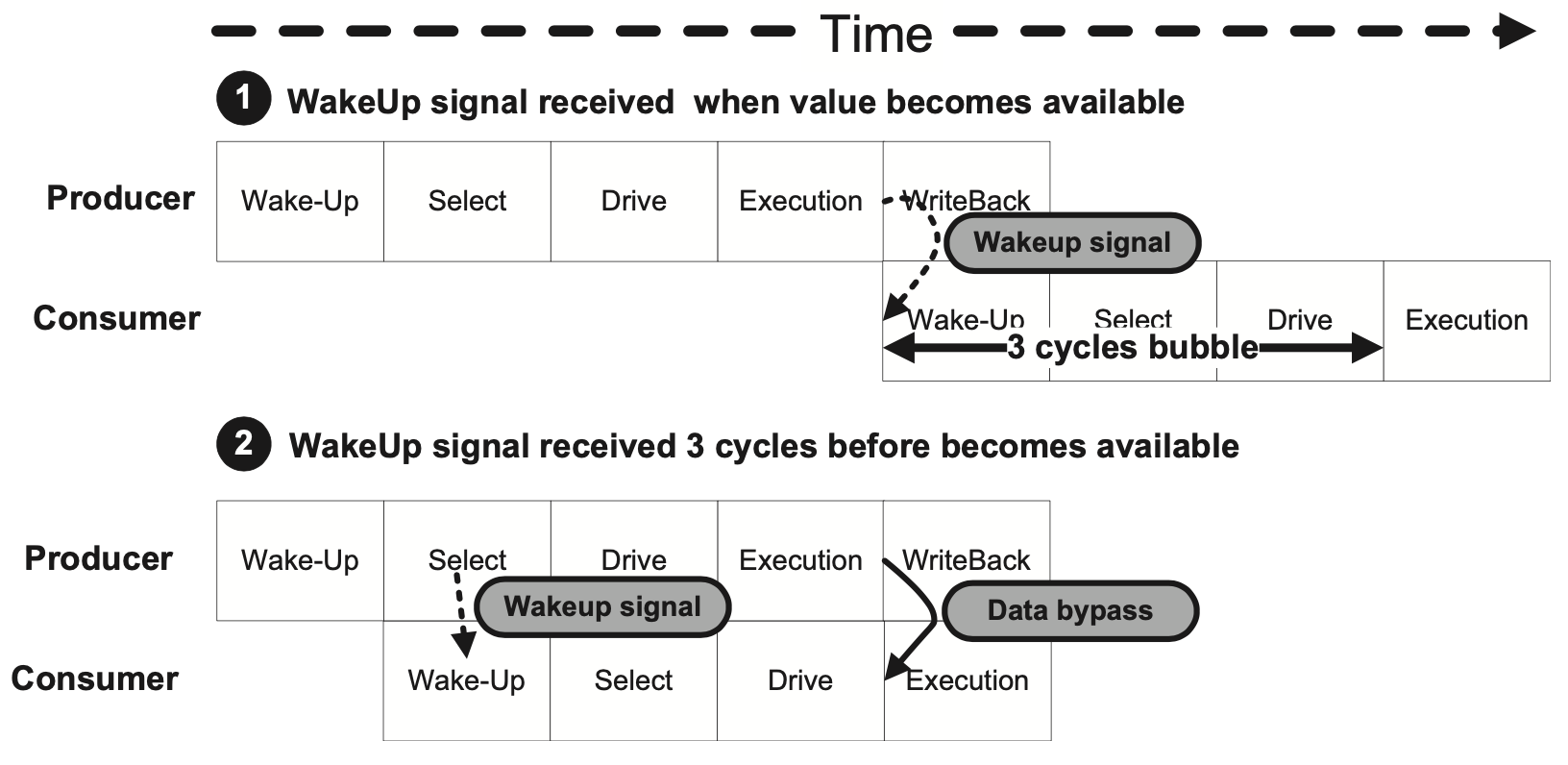 唤醒信号产生的时机
唤醒信号产生的时机
唤醒这个概念比较有意思的一点在于,唤醒信号其实可以在实际产生一个值之前就发出,以尽量缩短Producer和Consumer之间的距离。在上图的例子中,与其到Write Back再发出唤醒信号,可以在指令在发射队列中被选中的那个周期就向其依赖的指令发出唤醒信号,之后在执行阶段可以直接通过旁路网络读取输入,以达到指令背对背的执行。需要注意的是这里我们假设FU只需要一个周期完成、且Producer的选择和Consumer的唤醒也可以在一个周期内完成。
这一优化对性能至关重要,有两种常见的实现方式来产生唤醒信号。第一种方法是在指令执行完成前的三个周期在指令所在的流水线产生唤醒信号,第二种方法则是使用移位寄存器或Scoreboard。另外也需要注意的是,这种机制只有在一条指令需要的周期数是确定的情况下才有效,也就是说对于访存指令并不适用。对访存指令也有一些单独的优化技巧,比如Load指令可以用保守的方式处理,但其实也可以用更激进的方式处理。
指令选择
这一部分负责在发射队列中选择一部分已经准备好可以发射的指令,发射到对应的FU。由于时许的原因,选择逻辑通常会放在唤醒逻辑之后的一个周期进行,并使用仲裁器或调度器之类的组件来完成。具体的选择逻辑也有很多选项,如可以根据指令的顺序,或者也可以简单地根据发射队列中的位置进行排序等。
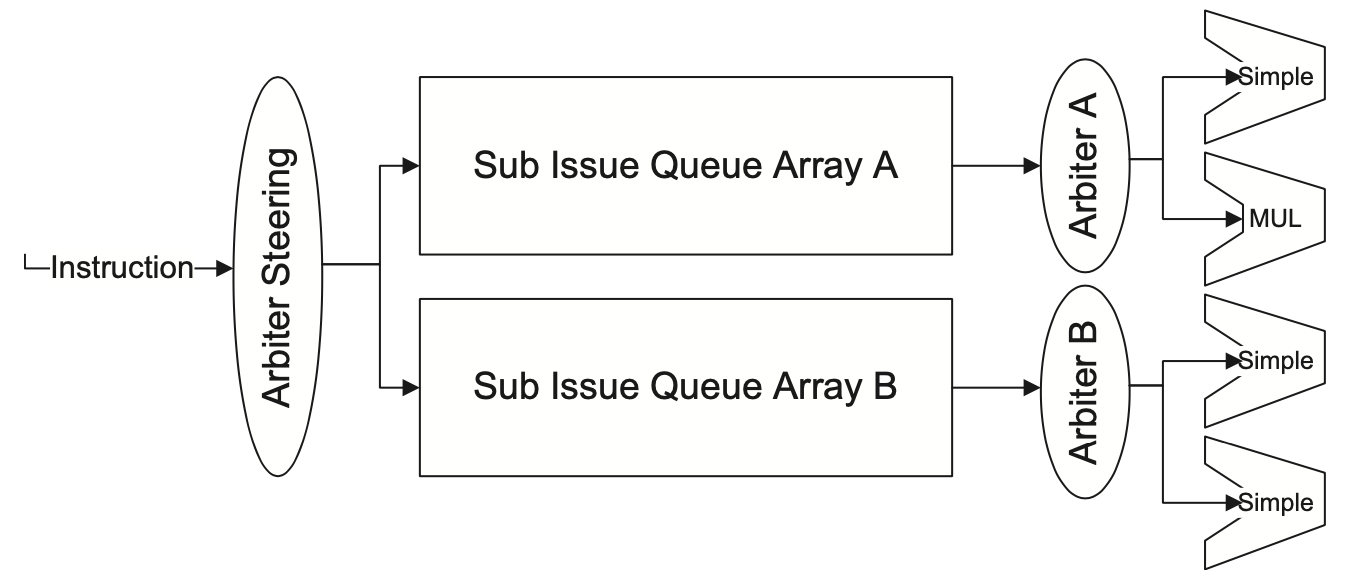 基于仲裁器的选择逻辑的实现
基于仲裁器的选择逻辑的实现
发射队列回收
一旦一条指令被发射到FU,对应的发射队列行就可以被回收,但是也有一些激进的优化如推测性唤醒,可能需要等待这条指令真正被发射成功之后才可以回收(类似于ROB的逻辑)。
发射后读取RF的发射过程
 发射后读取RF发射队列的硬件组成(灰色表示相比于之前的设计去掉的部分)
发射后读取RF发射队列的硬件组成(灰色表示相比于之前的设计去掉的部分)
 发射后读取RF发射队列的流水线设计
发射后读取RF发射队列的流水线设计
在这种设计中,发射队列不再需要存储寄存器的值。重命名和发射队列分配之间的流水线级数减少了,但唤醒逻辑和指令执行阶段之间需要多一个周期来读取RF。和前一种设计最重要的区别在于寄存器堆需要的端口数量,由发射宽度决定,且一般比前段的宽度更大。
减少读端口
寄存器堆的面积、功耗和访问延迟随着读端口的数量增加而增加,因此为了实现高能效的设计,需要尽可能减少读端口的数量。Alpha 21264分成了两个一样的寄存器堆,以减少单个寄存器堆的读端口的数量,代价是访问不同寄存器堆的Producer和Consumer无法背对背地执行。
不过,大部分寄存器源操作数其实是从旁路网络读取的,且发射宽度通常不会被完全利用,因此其实可以减少寄存器读端口的数量。有两种方法:主动或被动。主动的方法中,我们计算每条被选择的指令需要的读端口的数量,如果太多,就取消发射其中一部分指令。被动的方法中,只有在需要读端口数量过多的情况下才进行处理,一部分指令被取消、放回发射队列并重新发射。注意在被动的方法中,可能会发生starvation甚至live lock,因而需要定义一个公平的发射策略。
其他乱序发射的实现
分布式发射队列:每一个FU集群都有自己的发射队列,如Intel Pentium 4有两个队列:访存与非访存。
保留站:每一个FU都有自己的私有缓冲区,也就是Tomasulo在IBM 360/91中使用的方案。
访存操作的发射逻辑
访存指令的数据依赖性是基于内存地址的,在重命名阶段无法确定,只有计算出地址之后才可以确定依赖关系,这种机制称为内存消歧(memory disambiguation policy),上图中展示了不同的方案,主要可以分为两类:非推测性和推测性,前者不允许在不确定依赖关系的情况下执行访存操作,而后者会对依赖关系做出预测并执行。
选择一个合适的策略很重要,一方面如果过于保守会导致不必要的访存指令按序执行,降低性能,另一方面如果过于激进则会导致复杂的错误恢复机制,增大功耗。
非推测性内存消歧
在不确定依赖关系的情况下,这种策略不会执行任何访存操作,主要分为三种相关的策略:total ordering、load ordering with store ordering以及partial ordering。
Total ordering:所有访存操作都是按序执行的,目前没有按照这种方式实现的乱序处理器。
Load ordering with store ordering:load与store分别按序执行,但load不需要等待之前的store,如AMD K6等。
Partial ordering:load可以乱序执行,只要源操作数准备好,且之前所有的store都已经计算出访存地址,就可以发出load请求,如MIPS R10000、AMD K8等。
只要计算出访存地址,就可以进行内存消歧,因此一些处理器将store操作分为两个子任务:计算地址与存储数据。原书中给出了AMD K6和MIPS R10000的案例研究,此处就不再展开了。
推测性内存消歧
这种方案可以通过推测性地执行load指令来提升性能,load指令不需要等待先前的store来计算地址。注意到这个方案对依赖性进行推测,也就是说可能会发生错误,因此需要额外的硬件来识别错误并恢复正确执行。原书中给出了Alpha 21264的案例研究,此处也就不再展开了。
Load指令Consumers的推测唤醒
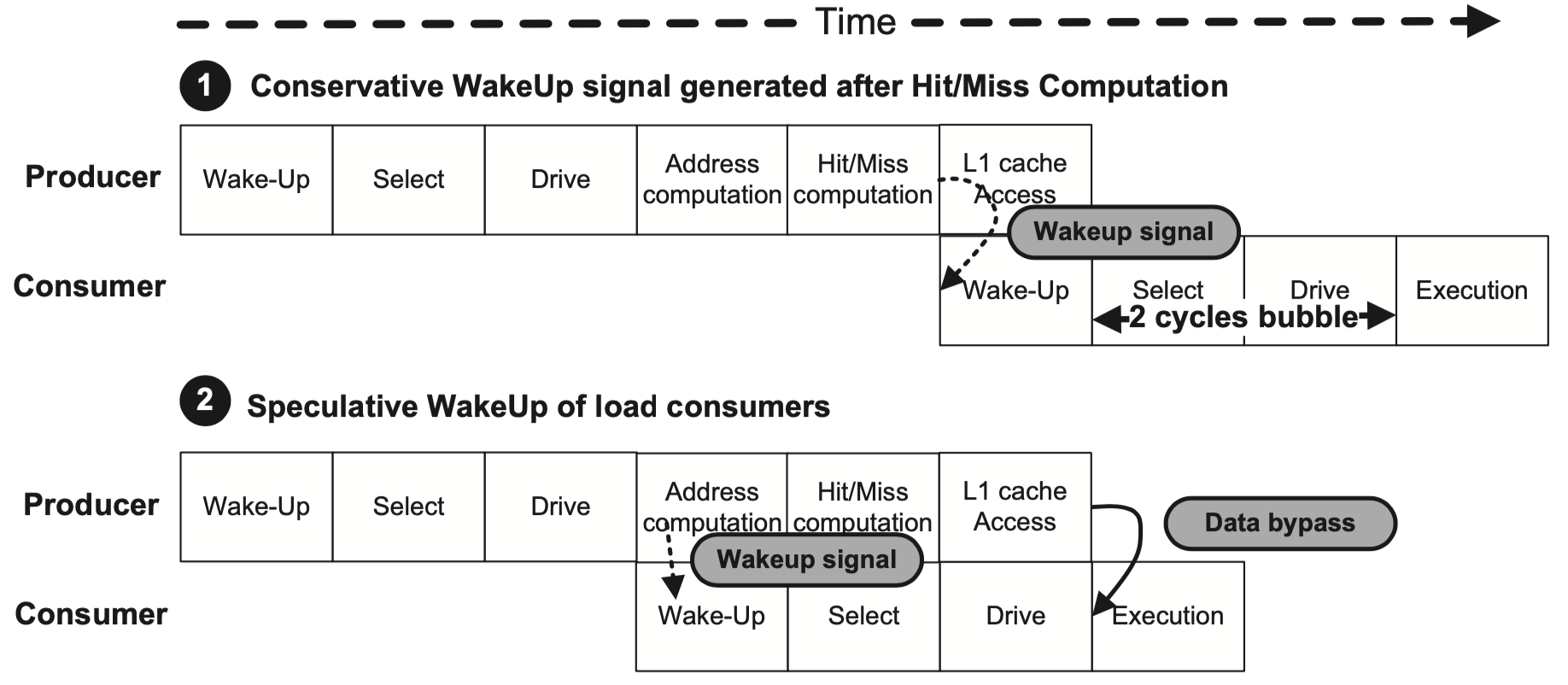 Load指令与其Consumer的流水线
Load指令与其Consumer的流水线
Load指令需要的周期数是不固定的。如上图所示,在保守的情况中,在缓存命中时才会唤醒下一条指令,会产生两个周期的气泡,但如果使用推测唤醒,就可以实现两条指令的背对背执行。不过,如果缓存未命中,Load指令的Consumer需要被放回发射队列并重新发射,且可能会导致死锁。
死锁有几种解决方案。一种是冲刷流水线中所有比放回发射队列的指令年轻的指令,类似Alpha 21264中实现的机制。另一种是推迟发射队列中条目的回收,直到确定这条指令已经被发射成功,但这种方式也需要增加发射队列的大小。