取指单元负责向处理器提供接下来要执行的指令,解码单元负责理解一条指令的语义并定义这条指令将如何被执行。
取指单元主要包括一个指令缓存和相关的逻辑。高性能处理器也需要在这一阶段预测下一条指令地址,包括两个部分:分支方向与分支目标地址。下图中是一个简单的取指流水线。
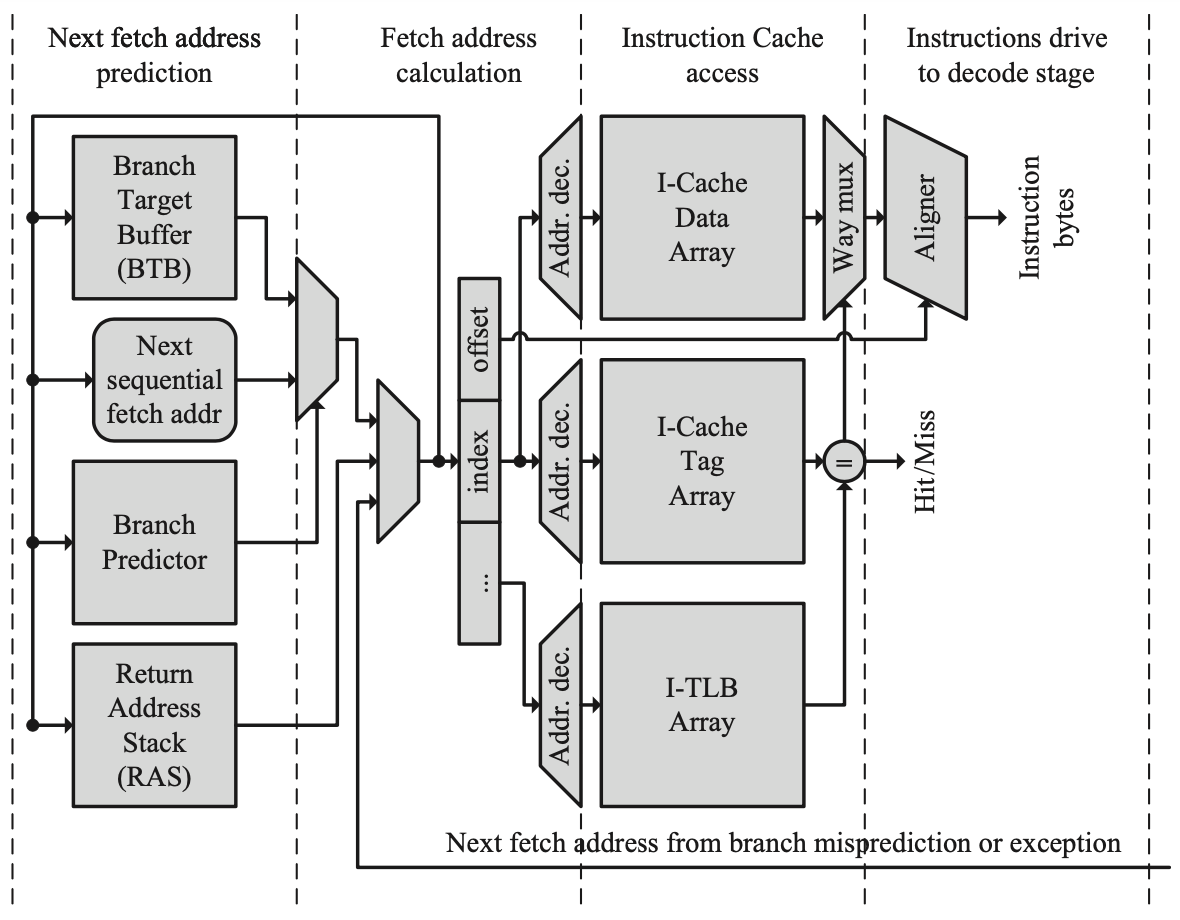 简单的取指流水线
简单的取指流水线
解码单元则负责将原始字节流分割成有效的指令,为指令生成一系列流水线控制信号,包括指令类型、执行什么操作、需要什么资源等。
取指
指令缓存
Trace缓存
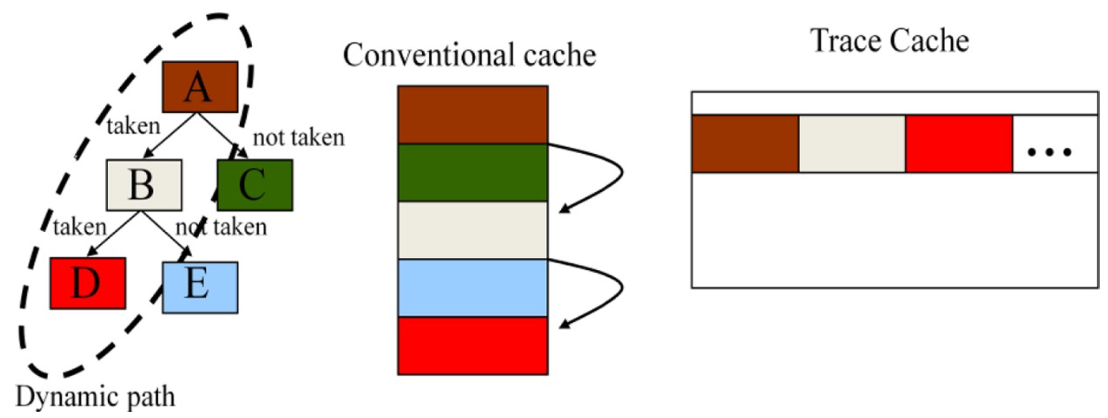 传统指令缓存与Trace缓存
传统指令缓存与Trace缓存
传统的缓存是按照指令在Binary中出现的顺序来存储的,但还有另一种组织方式是按照指令出现的动态顺序来存储的,也就是Trace缓存。上图说明了这两种组织的关键区别,包括数据重复与内存端口的带宽。在传统缓存中,一个数据只会出现一次,但是在Trace缓存中可能出现多次。同时,传统缓存中一个端口的带宽受限于分支的频率,相比之下Trace缓存可以连续读取数据。
Branch Target Buffer (BTB) 与Return Address Stack (RAS)
我们需要不断预测分支的目标地址,这一任务主要由BTB和RAS两大组件来完成,BTB负责预测普通的分支指令,而RAS主要负责预测函数的返回指令。
分支方向预测
分支方向预测可以通过静态(编译器或程序员完成)、动态或两者结合的方式进行。
静态预测可以通过程序的profiling信息完成,但如果没有profiling信息,也可以对循环等特殊的分支做出静态预测。从硬件角度来看,静态预测很容易实现,需要对指令进行一些编码。
相比之下,动态预测需要一些硬件来存储程序运行时的一些额外信息,如2位饱和计数器等。现代处理器也会使用更复杂的动态分支预测器,如2级分支预测器、GSHARE预测器、混合分支预测器等。混合分支预测器在某些场景下很有效,比如上下文切换之后,全局预测器的效果更好,但过了一段时间之后,局部预测器效果会更好,可以使用混合预测器在两种模式之间灵活切换。
解码
x86 ISA
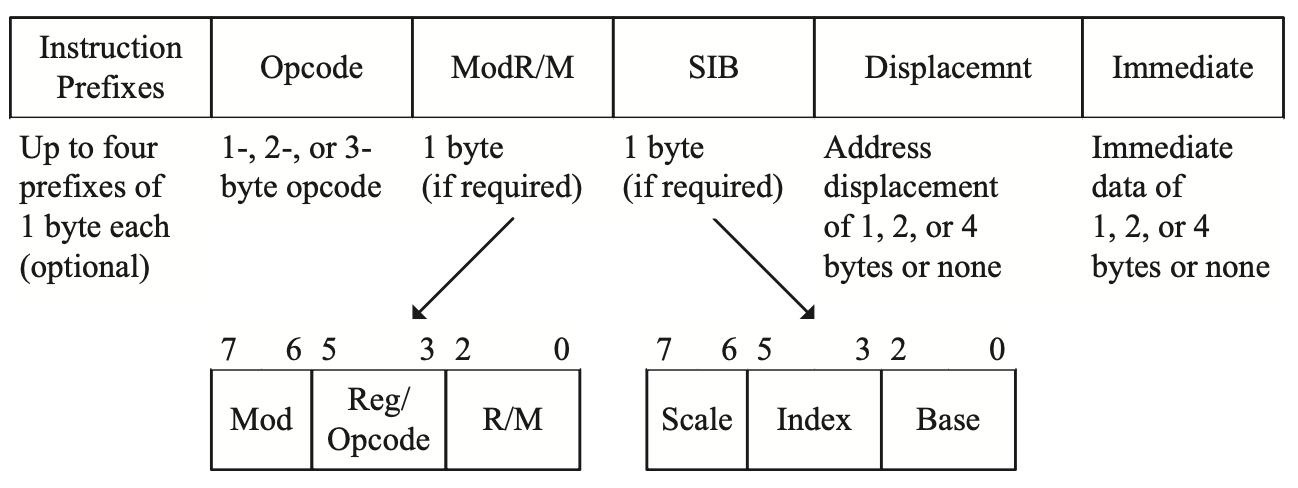 x86指令格式
x86指令格式
RISC的解码相对来说非常简单,且通常可以在一个周期内完成,事实上这也是RISC的最初设计目标之一。相比之下,作为CISC代表的x86指令集,解码则会更复杂一些。上图展示了x86指令的格式,一条x86指令最多包括4个prefix字节,1-3个opcode,可选的寻址指定符,有些指令还有立即数。如果我们想并行解码超过一条指令,我们就必须首先知道每条指令的长度,因此能够快速计算指令长度对x86指令集来说很重要,这个过程中存在两个问题。一是opcode不总是在指令开头的同一偏移量中,可以是前5个字节的任何地方;二是opcode本身大小也是可变的,最多是3个字节。对于寄存器编码也非常复杂,如用3个bit我们只能对8个通用寄存器编码,但是在32位模式下,一个数值为0的操作数可以解释为AL、AX、EAX、MM0或XMM0。
可见,CISC的解码非常复杂,接下来我们将会讨论高性能乱序超标量处理器中的解码单元实现。
动态翻译
一条x86指令可以包含很多信息,如 add [ax], ebx 这条指令包括了以下一些操作:
使用EAX和数据段寄存器DS计算出内存操作数的地址。
找到对应内存位置的值,加上寄存器EBX的值。
将加法的结果写回1中计算的内存位置。
乱序处理器需要大量的控制信号来跟踪每个时间点上指令执行的阶段,如果我们想提升性能,最好把指令执行的某些部分与其他指令并行化,比如地址的计算不应该依赖于前面的指令为寄存器EBX产生正确的值。相比之下,RISC指令集就会把这一条指令分解成三条简单的指令,可以更容易地被乱序处理器处理。
由于x86指令集的复杂性,x86处理器会在解码单元动态地将指令流翻译成类似RISC的指令,最早可以追溯至AMD K5和Intel P6,Intel将这种类似RISC的内部指令称为micro-operation,即微指令。在P6中,微指令有固定长度(118位)和格式,注意到微指令并不是真正的一条RISC指令,而更类似于解码之后的RISC指令。
高性能x86解码
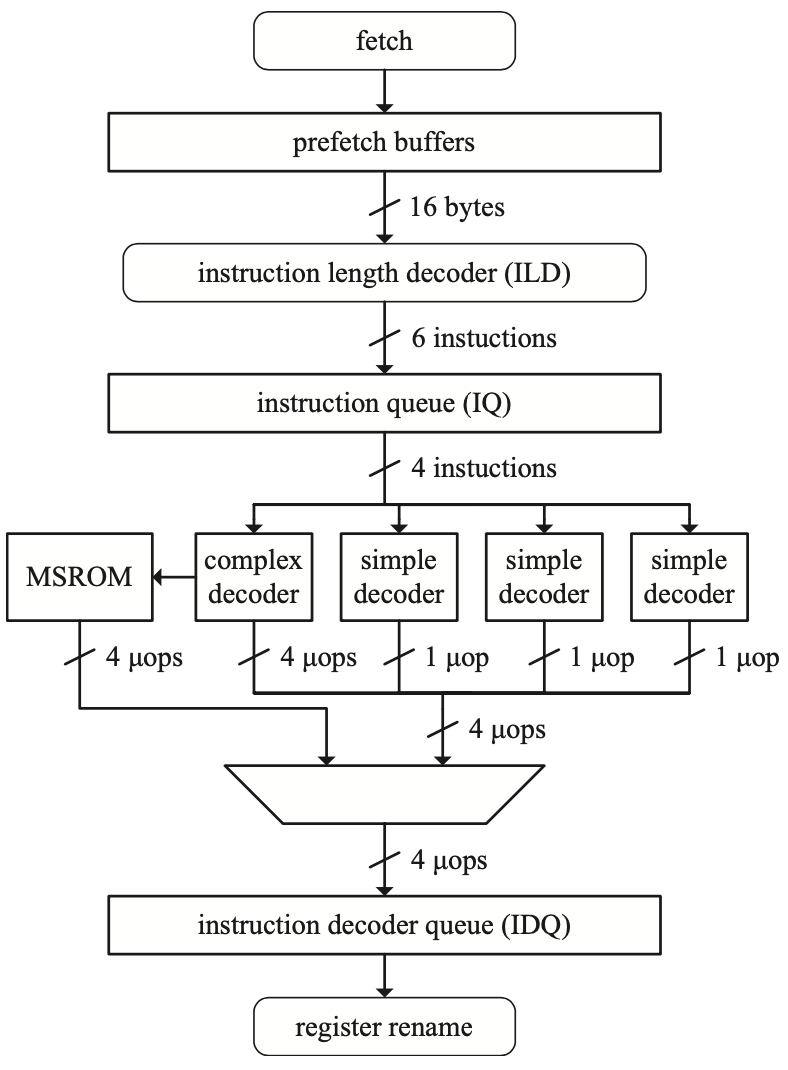 Intel Nehalem解码流水线
Intel Nehalem解码流水线
上图展示了Intel Nehalem架构的解码单元,可以看出,X86解码是一个多周期的操作。这个过程被分为两个阶段:指令长度解码(ILD)和动态翻译,这两个阶段通过一个指令队列(IQ)解耦,可以隐藏ILD中的气泡。
指令长度解码
ILD单元从prefetch buffers中取出对齐的16字节,执行一些基本的预编码,确定指令长度,对前缀进行解码,标记一些指令属性。这一过程是顺序的,大多数常见指令都可以在一个周期内完成,但有如下两种情况需要6个周期来处理:
An operand-size override prefix, preceding an instruction with a word immediate.
An address-size override prefix, preceding an instruction with a ModR /M byte.
动态翻译单元
在这个阶段,指令从IQ中取出,并翻译为微指令,上图的设计中包括3个简单解码器(一条指令转换为一个微指令)和一个复杂解码器(一条指令转换为四个微指令)。有一些特殊的指令(如字符串指令)可能需要超过4个微指令,这些指令会被发送到复杂解码器,停顿解码流水线,并由MSROM单元控制。MSROM会接收这样的复杂指令,并输出一串微指令,来模拟复杂的x86指令。