《处理器微架构实现》(英文名为Processor Microarchitecture: An Implementation Perspective)是CMU 18-447 Introduction to Computer Architecture推荐阅读的一本教材。首先介绍的内容是缓存,关于缓存的基本概念在网络上可以找到很多介绍,这里就不再详细展开了。我们在此只讨论一些缓存具体的实现问题。
地址翻译
我们访问内存的地址通常分为虚拟地址(Virtual Address)和物理地址(Physical Address)。其实还有有效地址(Effective Address),但是这个概念现在已经很少有人提到了,就不再单独讨论了。虚拟地址有诸多好处,如减少了程序员访问内存的工作量、实现对内存的保护等,现在最主流的实现虚拟地址的方式是分页,采用页表进行管理。由于不同的虚拟页面可能指向同一个物理页面,会发生别名(Alias)的问题,缓存需要正确处理这一问题。
当程序发出load或store指令时,我们需要多次访问内存。因此除了缓存之外,我们还需要TLB来对地址翻译的过程进行加速。在一些处理器(如Alpha系列处理器)中,TLB完全是由软件控制的,而在x86架构中,TLB由硬件控制,对操作系统透明。
缓存结构
并行与串行访问
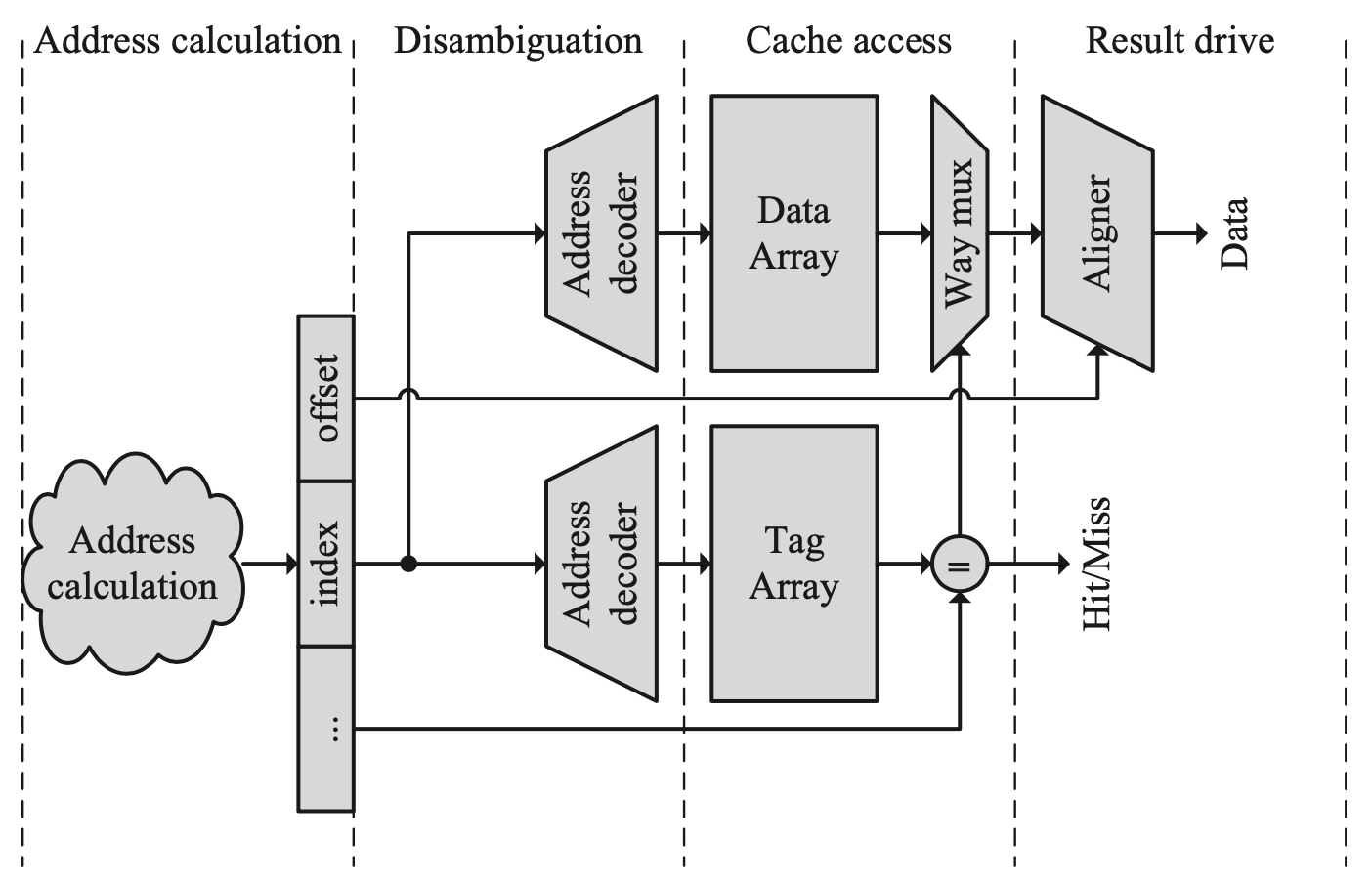 并行访问Tag与Data的流水线
并行访问Tag与Data的流水线
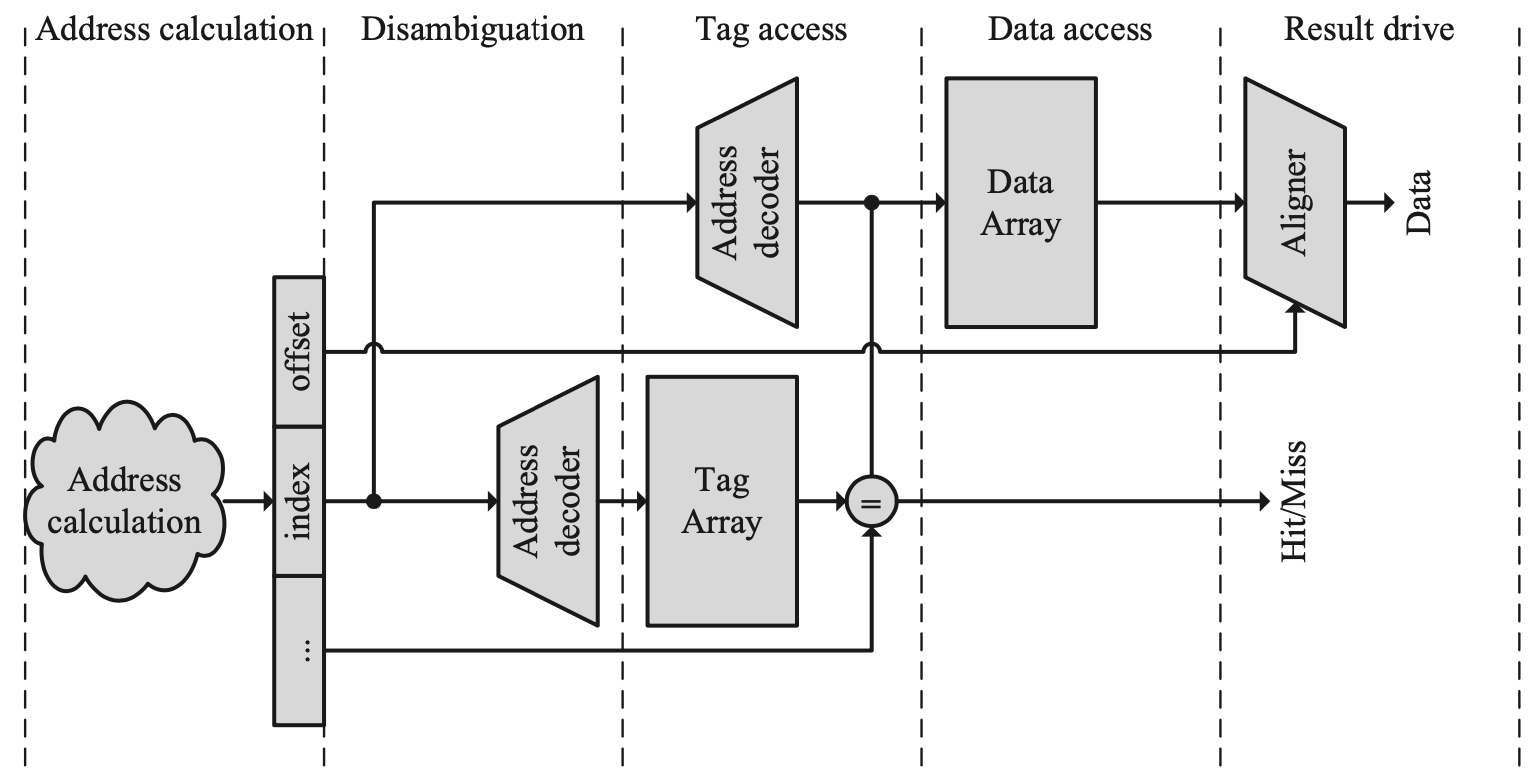 串行访问Tag与Data的流水线
串行访问Tag与Data的流水线
对Tag与Data的访问可以并行或串行进行。在第一种情况下,我们在访问Tag Array的同时,从Data Array中读取数据,并判断缓存是否命中,以及选择Set中的哪一个缓存行。最后,地址的偏移量用来决定取出数据中的哪些部分将被送回处理器。在第二种情况下,我们首先访问Tag Array,然后再根据Tag来决定访问哪一行数据,我们可以注意到这种设计的一大好处是减少了Mux的使用,关键路径更短,功耗更低。
非阻塞缓存
对阻塞式的缓存而言,在L1缓存未命中时,整个流水线都需要等待其从更高级的缓存或内存中取回数据。这样的设计比较简单,但是会严重影响性能(尤其是对于乱序处理器而言)。相比之下,非阻塞缓存允许缓存未命中时,流水线仍然可以继续处理其他的内存访问,这就需要一些跟踪这些未命中的指令的机制(如Scoreboard)。这一概念由Kroft在Lockup-Free Instruction Fetch/Prefetch Cache Organization一文中首先提出,采用了名为miss status holding registers (MSHR)的寄存器来存放Cache Miss指令的信息。除此之外还有一个input stack来存放取回但还没有写入到缓存中的数据(因此也叫做fill buffer)。在这样的设计中,Cache Miss会存在以下三种情况:
首次Miss:第一次Miss一个缓存行,将访问更高一级的缓存或内存。
第二次Miss:和之前的Miss访问同一个缓存行。
结构性Miss:由于MSHR容量有限,无法容纳更多的Miss指令,需要停顿流水线。
MSHR也有多种不同的实现方式,复杂性与性能各不相同,我们讨论三种不同的设计。
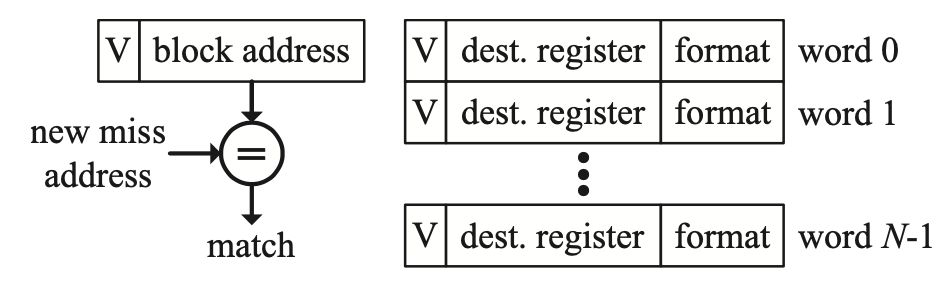 Implicitly addressed MSHR
Implicitly addressed MSHR
第一种是implicitly addressed MSHR,这是最简单的MSHR设计,由Kroft提出,如上图所示。每个MSHR包括一个Miss缓存行的地址与valid bit,以及相应的比较器。如果一个缓存行有N个words,那么MSHR也包括N个条目,每个条目都包含Miss指令的目标寄存器与一些格式信息(如果load数据的大小,是否为零扩展或符号扩展等)。
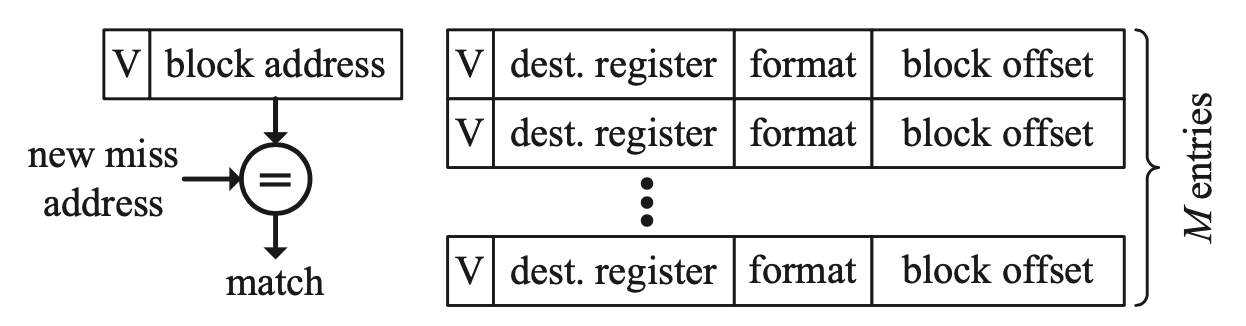 Explicitly addressed MSHR
Explicitly addressed MSHR
第二种是explicitly addressed MSHR。我们注意到第一种设计中,对每个缓存行只能容纳一条Miss指令,如果有第二条Miss的指令,就会有结构性Miss。在第二种设计中,每个MSHR都对应了M个条目,也就是说可以容纳M条同时Miss同一个缓存行的指令,每个条目都有对应的缓存块内偏移量。
第三种设计是in-cache MSHR,优点是可以减少保存MSHR信息所需的存储量。我们注意到缓存行在等待被重新填充时,也可以用作MSHR的存储。在这样的设计中,Tag Array需要添加额外的一位(transient bit)来表示当前这一缓存行是否被作为MSHR来使用。
多端口缓存
为了提升带宽,很多现代处理器都可以在每个周期内发出多条访存指令。我们首先研究一个真正的双端口缓存设计,接下来研究商业处理器如何尝试尽可能接近这种理想设计。
理想的多端口缓存设计
对于一个真正的双端口缓存来说,所有的东西都有两份:有两个地址解码器、Tag比较器等等,可以实现在每个周期内对缓存读取两次(注意写入两次不一定代表有两个写入端口,只要保证一个缓存行在同一周期内不会被写入两次就可以了)。这样的设计会大大增加缓存访问时间,可能会影响关键路径,增大面积等。
Array Replication
这种设计类似理想设计,但我们重复了Tag与Data Array,也就是用两个单端口的缓存来模拟一个双端口缓存。这种设计面积和真正的双端口设计面积相差不大,但面积还是非常大。
Virtual Multiporting
IBM Power2和Alpha 21264采用了这种设计。原理是利用了时分多路复用,在一个周期内对一个单端口缓存进行多次访问。在Alpha 21264中,有两个读端口,第一个读端口在时钟周期的前半部分访问缓存,第二个则在后半周期。这种设计无法扩展,现代处理器的时钟频率很高,没办法把一个周期拆成两半来用。
Multibanking
这种设计将缓存分成多个小的阵列(叫做bank)。在一个周期内,如果多个load请求访问了不同的bank,那么就可以同时处理这些load请求。我们仍然需要两个地址解码器、Mux、Tag比较器等,但是和理想设计相比,Tag与Data array不需要有多端口。这种设计是当今高性能处理器中模拟多端口的首选方法。MIPS R10000实现了这种方法,允许每个周期有两个load和一个store请求,32KB的数据缓存被分为两个bank,2路组相联,每个缓存块为32B,每个缓存bank逻辑上被分为两个物理阵列,如下图所示。
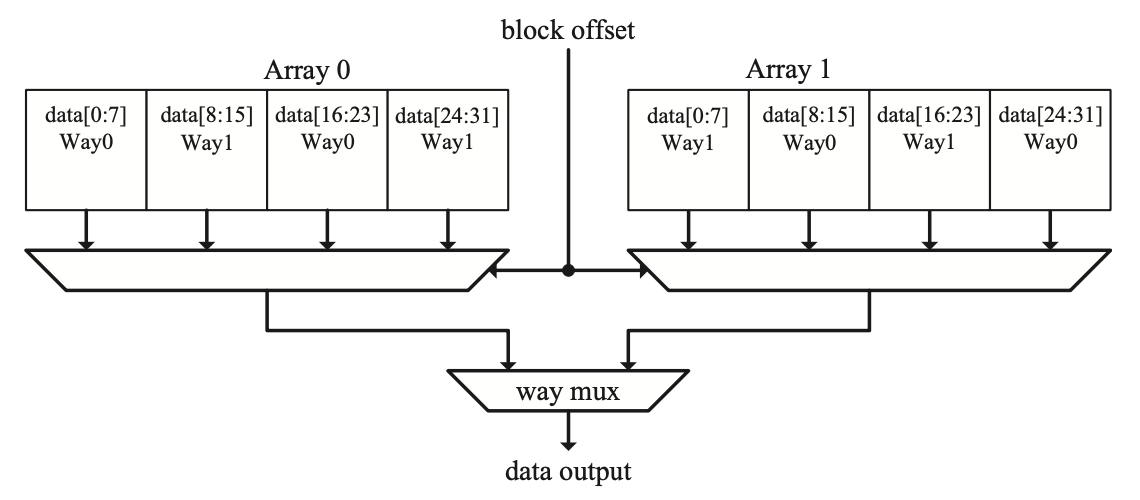 Data array bank中的数据组织方式
Data array bank中的数据组织方式
指令缓存
由于程序访问指令缓存的模式更简单,指令缓存通常设计也更为简单。指令缓存通常都是单端口的、阻塞式的,后者是因为指令的访问必须是按照顺序的,实现非阻塞缓存没有任何意义。当然,我们也需要仔细权衡,采用并行还是串行的方式来访问Tag和Data,以及采用什么样的相联度。