路由器的设计必须在严格的面积和功率限制下满足延迟和吞吐量的要求,这也是在多核系统扩展时面临的一个主要挑战。对吞吐量要求较低时,可以使用非常简单的路由器,其面积和功率开销较低,但是当NoC的延迟和吞吐量要求提高时,就会对路由器设计提出挑战。
路由器的微架构决定了关键路径延迟,影响每一跳以及整个网络的延迟。路由的实现、流量控制和实际的路由器流水线会影响到使用缓冲区和链接的效率,从而影响到整个网络的吞吐量。路由器的微架构也会影响网络功耗(包括动态和静态)和面积占用。
虚拟通道路由器微架构
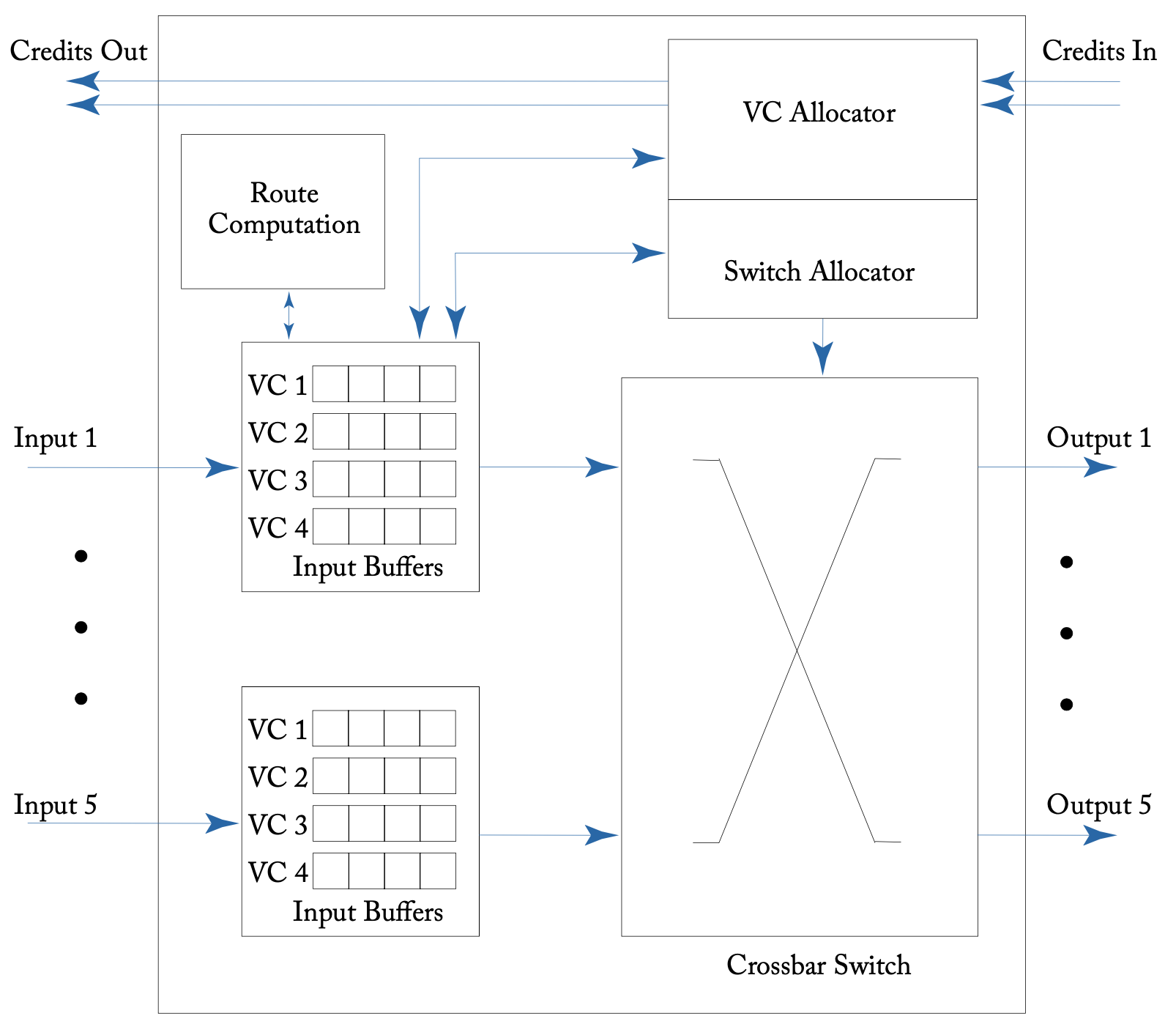 基于信用的VC路由器微架构
基于信用的VC路由器微架构
上图展示了基于信用的VC路由器微架构,以解释典型路由器的工作原理。在这个例子中,我们假设有一个2-D Mesh结构,每个路由器有5个输入和输出端口,分别对应4个相邻方向以及一个本地处理器端口,每个输入端口有4个VC,每个VC都有自己的缓冲队列,队列深度为4 flits。
构成路由器的主要部件是输入缓冲、路由计算逻辑、虚拟通道分配器、开关分配器和crossbar开关。如果不使用源节点路由,路由计算器将计算(或查找)当前数据包的输出端口,分配器决定哪些flits被选择进入下一个阶段,并穿越crossbar,最后crossbar负责将flits从输入端口物理地移动到输出端口。
缓冲区和虚拟通道
当数据包或flits不能立即转发到输出时,会被存放在缓冲区中,可以在输入端口和输出端口上进行缓冲。当交换机的分配速率大于通道的传输速率时,就需要输出缓冲。
缓冲区组织结构
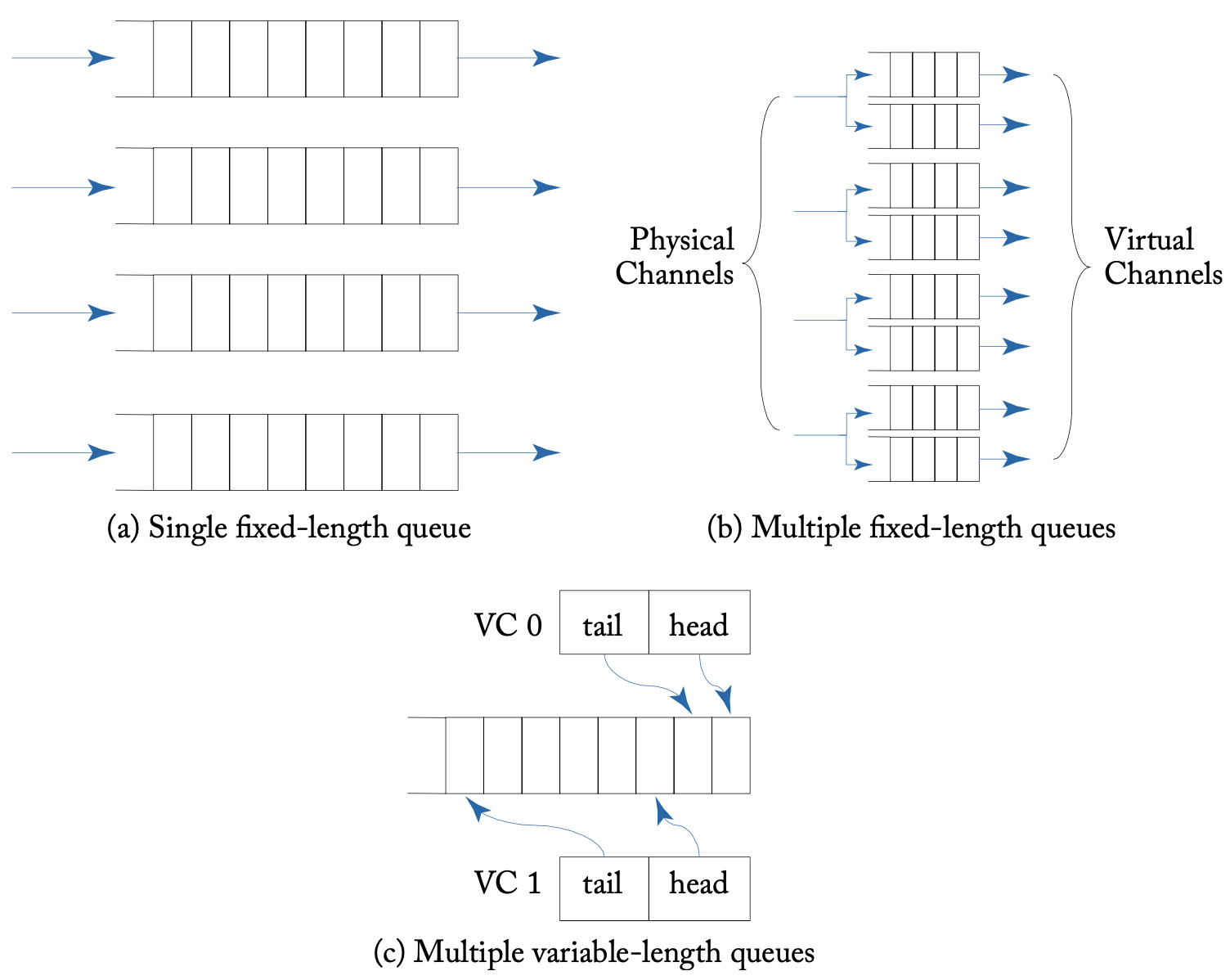 缓冲区与VC组织结构
缓冲区与VC组织结构
缓冲区组织结构会很大程度上影响网络吞吐量,具体的设计有:单个固定长度的队列、多个固定长度的队列(每个队列被称为虚拟通道,复用并共享物理通道或带宽)、多个可变长度的队列(多个VC共享一个大的缓冲区,但电路更复杂,且需要为每个VC保留一定大小以避免死锁)、最小数量的虚拟通道、最小缓冲区数量。
输入VC状态
每个VC都和其中flit的以下状态有关:
Global (G): Idle/Routing/waiting for output VC/waiting for credits in output VC/Active. Active VCs can perform switch allocation.
Route (R): Output port for the packet. This field is used for switch allocation. The output port is populated after route computation by the head flit. In designs with lookahead routing or source routing, the head flit arrives at the current router with the output port already designated.
Output VC (O): Output VC (i.e., VC at downstream router) for this packet. This is populated after VC allocation by the head flit, and used by all subsequent flits in the packet.
Credit Count (C): Number of credits (i.e., flit buffers at downstream router) in output VC O at output port R. This field is used by body and tail flits.
Pointers (P): Pointers to head and tail flits. This is required if buffers are implemented as a shared pool of multiple variable-length queues, as described above.
开关设计
路由器的crossbar开关是路由器数据通路的核心部分,将数据从输入端口移动到输出端口。
Crossbar设计
下面给出了一个基本的描述Crossbar开关的Verilog模块,如上图所示,大多数低频路由器使用这种crossbar。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
module xbar (clk, reset, in0, in1, in2, in3, in4, out0, out1, out2 out3, out4, colsel0, colsel1,colsel2, colsel3, colsel4);
input clk;
input reset;
input ['CHANNELWIDTH:0] in0, in1, in2, in3, in4;
output ['CHANNELWIDTH:0] out0, out1, out2, out3, out4;
input [2:0] colsel0, colsel1, colsel2, colsel3 colsel4;
reg [2:0] colsel0reg, colsel1reg, colsel2reg, colsel3reg, colsel4reg;
bitxbar bx0(in0[0],in1[0],in2[0],in3[0],in4[0],out0[0],out1[0],out2[0] out3[0],out4[0],colsel0reg,colsel1reg,colsel2reg,colsel3reg,colsel4reg,1'bx);
bitxbar bx1(in0[1],in1[1],in2[1],in3[1],in4[1],out0[1],out1[1],out2[1],out3[1],out4[1],colsel0reg,colsel1reg,colsel2reg,colsel3reg,colsel4reg,1'bx);
bitxbar bx2(in0[2],in1[2],in2[2],in3[2],in4[2],out0[2],out1[2],out2[2],out3[2],out4[2],colsel0reg,colsel1reg,colsel2reg,colsel3reg,colsel4reg,1'bx);
bitxbar bx3(in0[3],in1[3],in2[3],in3[3],in4[3],out0[3],out1[3],out2[3],out3[3],out4[3],colsel0reg,colsel1reg,colsel2reg,colsel3reg,colsel4reg,1'bx);
endmodule
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
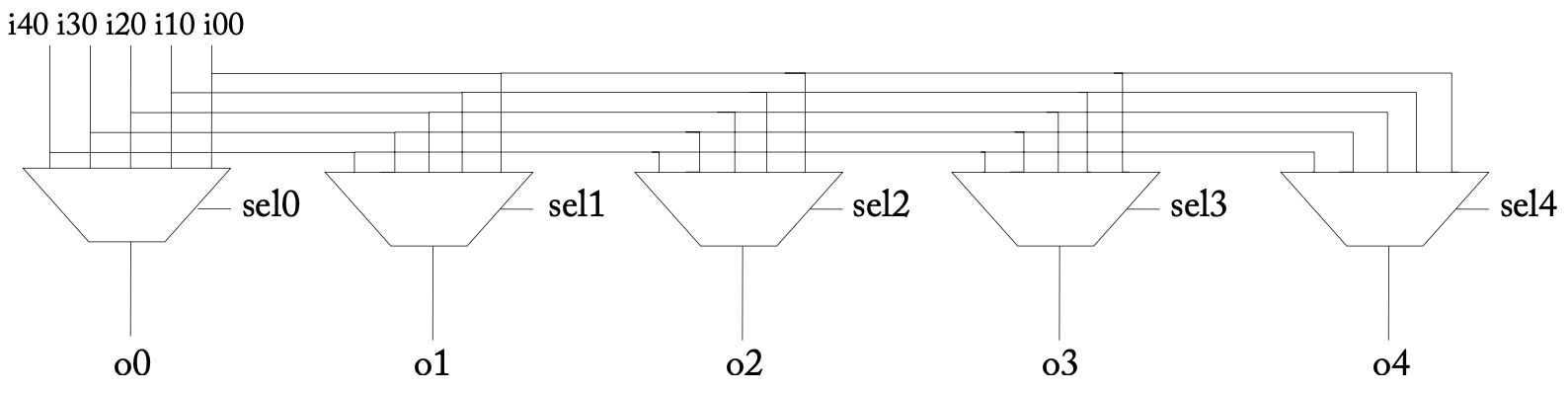
module bitxbar (i0,i1,i2,i3,i4,o0,o1,o2,o3,o4,sel0,sel1,sel2,sel3,sel4,inv);
input i0,i1,i2,i3,i4;
output o0,o1,o2,o3,o4;
input [2:0] sel0, sel1, sel2, sel3, sel4;
input inv;
buf b0(i00, i0); // buffer for driving in0 to the 5 muxes
// ...
buf b4(i40, i4);
mux5_1 m0(i00, i10, i20, i30, i40, o0, sel0, inv);
// ...
mux5_1 m4(i00, i10, i20, i30, i40, o4, sel4, inv);
endmodule
当频率要求更高时,会采用下图所示的设计,但无论采用哪种设计,面积和功率都会以O((pw)^2)的复杂度增长,其中p是crossbar端口的数量,w是端口宽度(单位bit)。
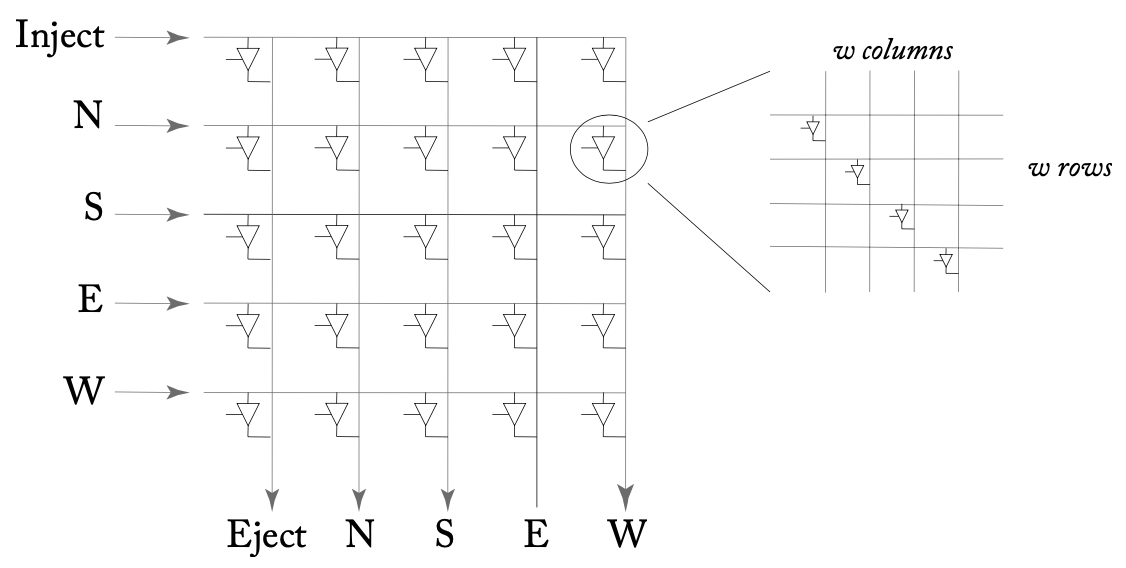 一个5x5的crossbar开关
一个5x5的crossbar开关
分配器与仲裁器
一个分配器将N个请求与M个资源相匹配,而一个仲裁器将N个请求与1个资源相匹配。对路由器来说,资源是VC和crossbar开关的端口。在多个VC的路由器中,我们需要一个VC分配器(VA)以及一个交换机分配器(SA),前者将VC分配给数据包或flit,或者将crossbar端口分配给VC。一个能提供高匹配概率的分配器或仲裁器可以使更多包顺利获得VC并通过crossbar,提高网络吞吐量。在大多数NoC中,路由器的分配逻辑决定了周期时间,因此分配器和仲裁器必须是快速的,并且是流水线的,以便在高时钟频率下工作。
循环(Round-robin)仲裁器
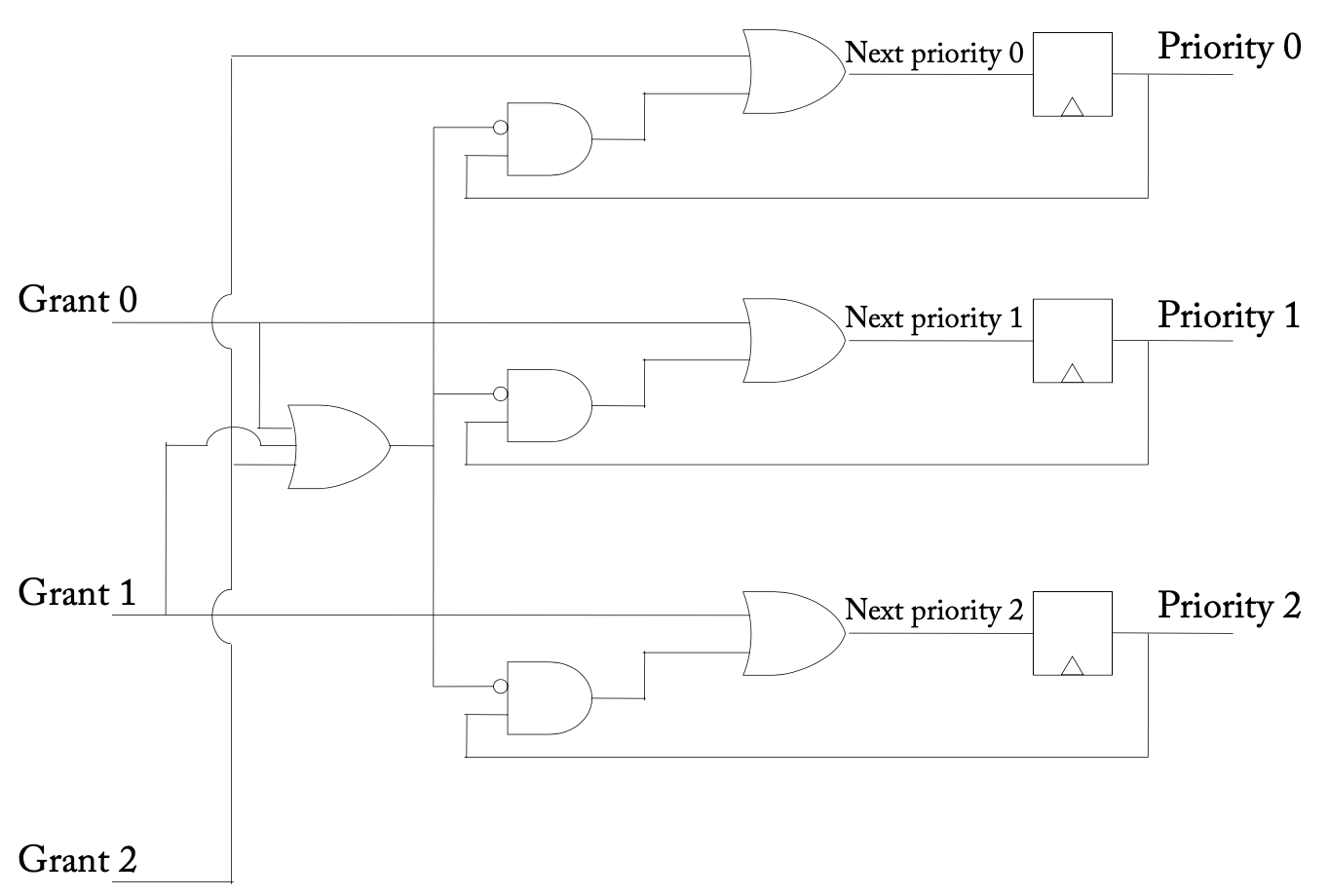 循环仲裁器
循环仲裁器
矩阵仲裁器
 矩阵仲裁器,其中wij表示优先位,当wij为1时,请求i的优先级比请求j更高
矩阵仲裁器,其中wij表示优先位,当wij为1时,请求i的优先级比请求j更高
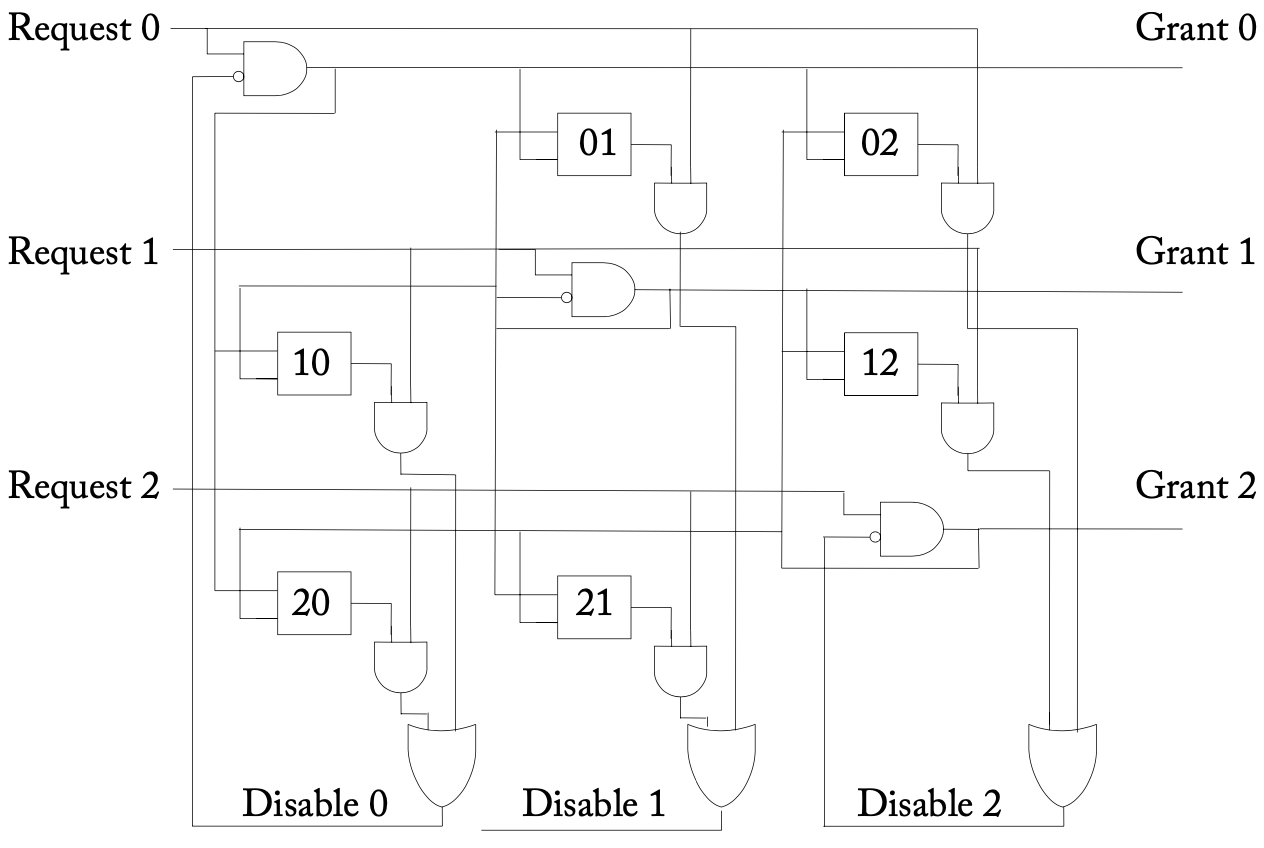
分离式分配器
为了降低分配器的复杂度,并使其流水化,分配器可以被构建为多个仲裁器的组合。在实践中尝试了不同的仲裁器,其中循环仲裁器由于其实现简单而最受欢迎。
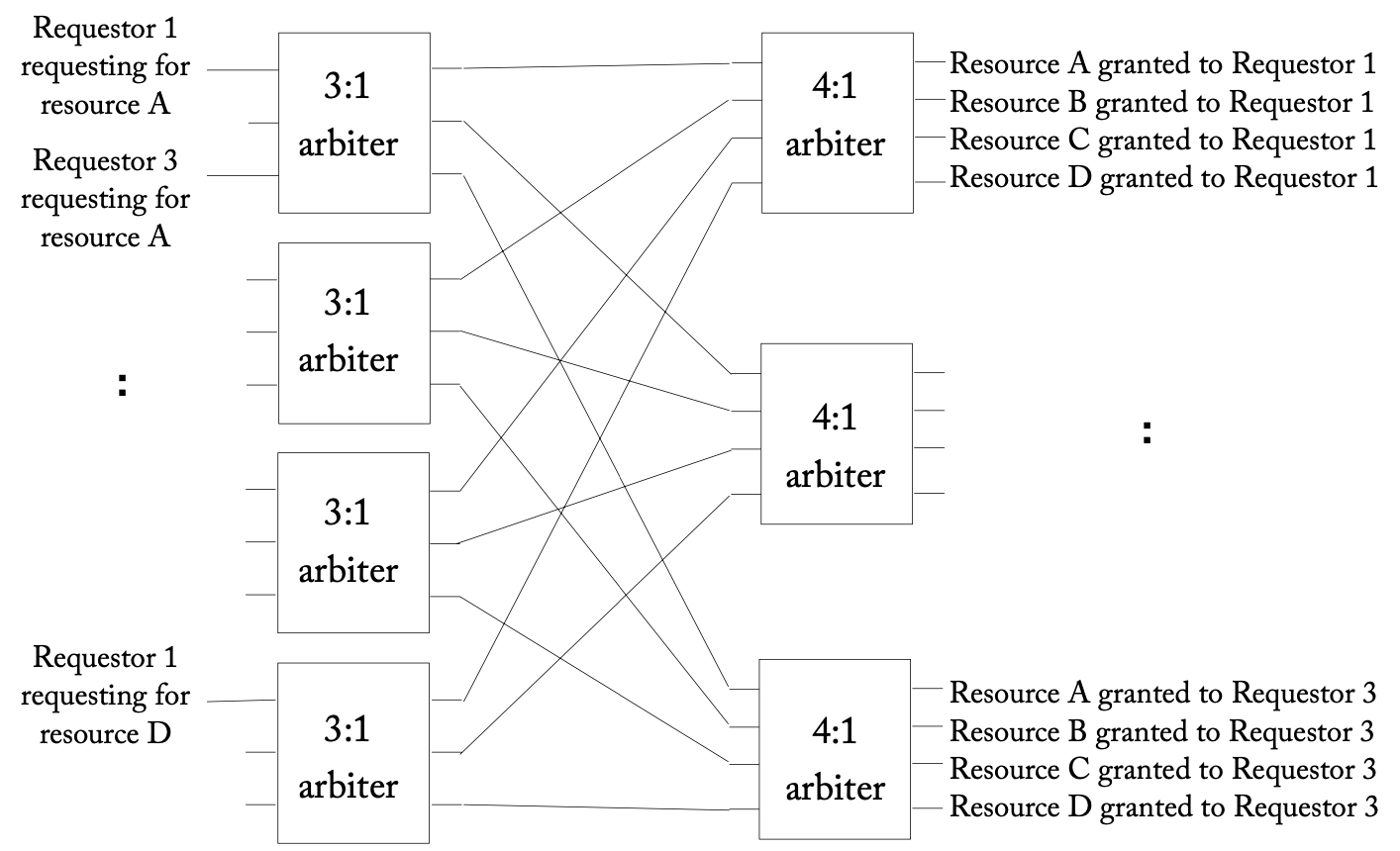 一个分离式的3:4分配器(3个请求者、4个资源)
一个分离式的3:4分配器(3个请求者、4个资源)
流水线
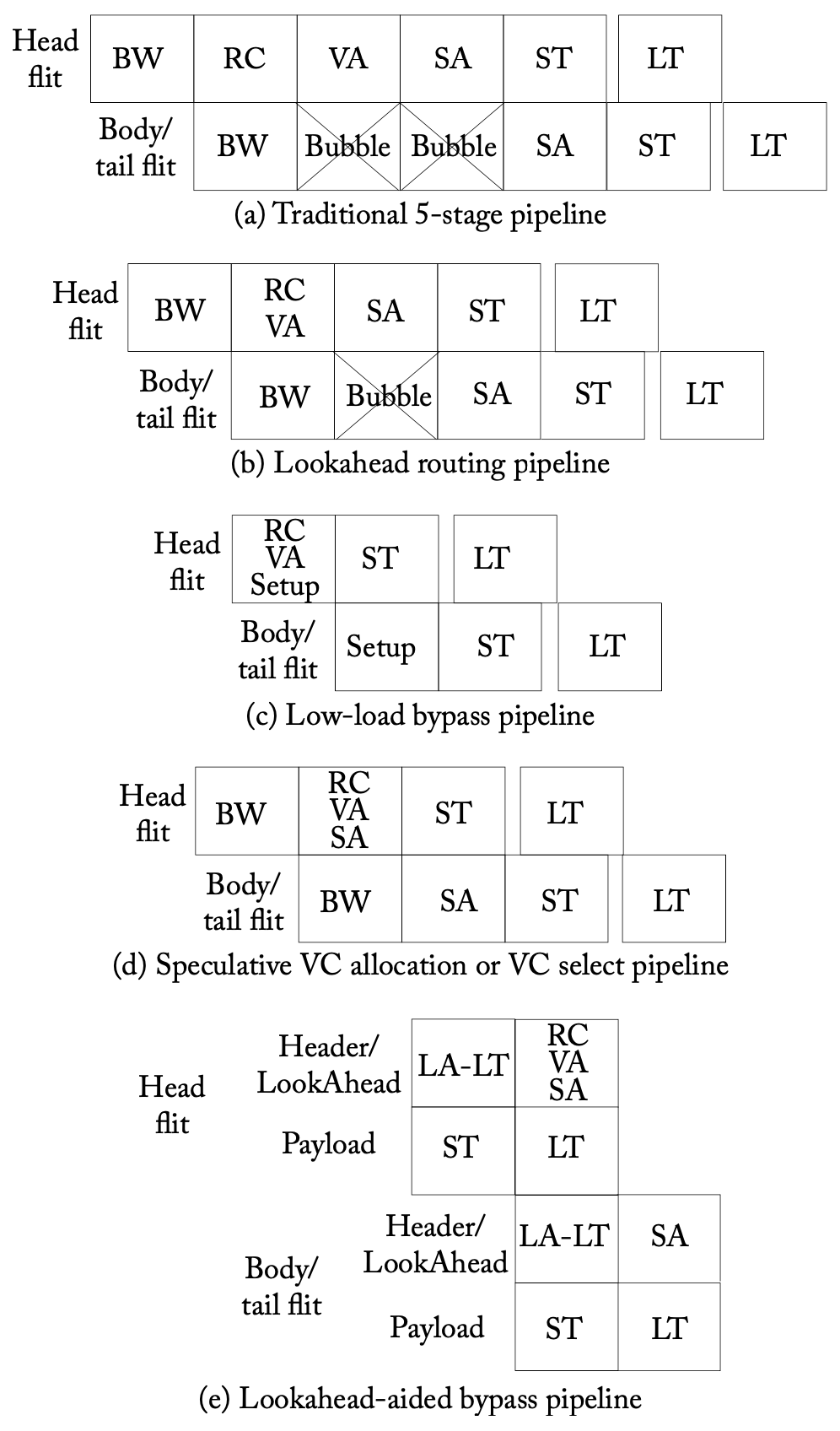 路由器流水线 (BW: Buffer Write, RC: Route Computation, VA: Virtual Channel Allocation, SA: Switch Allocation, ST: Switch Traversal, LT: Link Traversal)
路由器流水线 (BW: Buffer Write, RC: Route Computation, VA: Virtual Channel Allocation, SA: Switch Allocation, ST: Switch Traversal, LT: Link Traversal)
上图a显示了一个基本的VC路由器的逻辑流水线阶段。head flit到达一个输入端口时,首先根据其输入的VC在BW级进行解码并放入缓冲区,接下来在RC级路由逻辑进行计算以确定包的输出端口,然后head flit在VA级进行仲裁,找到输出端口的VC(即下一个路由器输入端口的VC),成功分配VC后,head flit进入SA级,对switch的输入和输出端口进行仲裁,随后进入ST级,遍历crossbar,最后在LT级,该flit被传送到下一个节点。body和tail flit遵循类似的流水线,但不会经过RC和VA级,而是直接继承header flit分配的路由和VC,tail flit在离开路由器时,会移除head flit保留的VC。
实现与优化
最长关键路径延迟的流水线级决定了时钟频率,通常当VC较多或crossbar较复杂时,VA或SA级的延迟最长。增加流水线级数会增加消息在每一跳的延迟,以及影响所需的最小缓冲区大小和吞吐量的缓冲区周转时间,因此有必要对其进行优化。
提前路由(lookahead routing)流水线移除了RC级,数据包的路由是由提前一跳确定的,并在head flit中编码,如上图b。低负载旁路(low-load bypass)流水线在轻度负载的路由器中移除了BW和SA级,如上图c。推测性VA移除了VA级,flit在BW之后推测性地进入SA级,对switch端口进行仲裁,并试图获得一个空闲的VC,如上图d。提前旁路(lookahead bypass)移除了BW和SA级,如上图e。具体的优化技巧相对而言比较复杂,可以参考原文。