在这一章中我们研究三种主要的系统架构:共享内存芯片多处理器(shared-memory chip multiprocessor, CMP)、消息传递系统、多处理器SoC(multiprocessor SoC, MPSoC)。
共享内存CMP
并行编程中,一个全局的地址空间通常比分区的地址空间设计起来更简单。在现代SMP设计中,分区全局地址空间(partitioned global address space, PGAS)很常见,也就是说地址的高位决定了内存位于哪个节点。相比之下,消息传递范式要求程序员明确地在节点和地址空间之间移动数据。在大规模并行架构中,同时利用这两种方法的混合方法很常见。在这一节,我们主要讨论共享内存CMP。
和SMP一样,CMP通常也有一个共享的全局地址空间,但和SMP不同的是,CMP可能有不一致的内存访问延迟。在共享内存模型中,通信是通过load、store指令产生的,对程序员并不可见。逻辑上来说所有处理器都访问相同的共享内存,但物理上来说,需要使用缓存来提升性能,但在这种设计下缓存一致性的设计就变得复杂,缓存一致性协议决定了哪些通信是必要的。
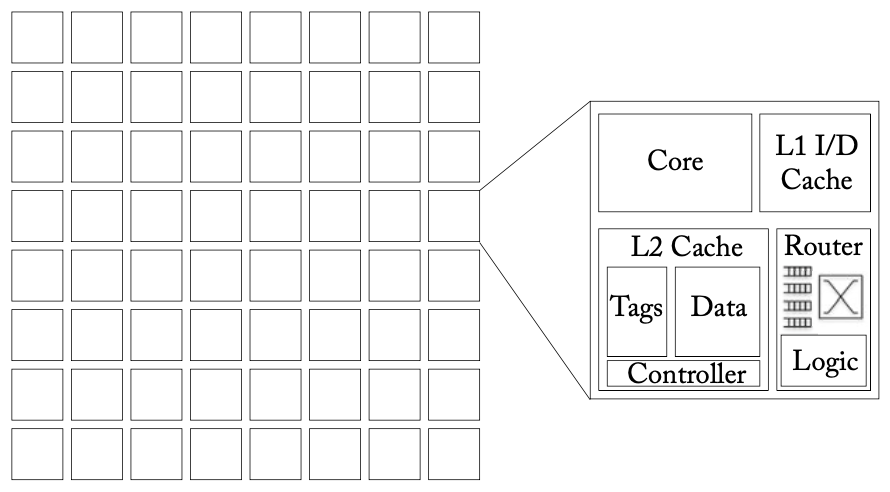 共享内存CMP架构
共享内存CMP架构
上图是一个典型的有64节点的共享内存CMP架构,每个节点都包括一个处理器、私有的L1缓存、以及一个可能是私有或共享的L2缓存,同时可能存在一个所有处理器共享的L3缓存。
一致性协议对网络性能的影响
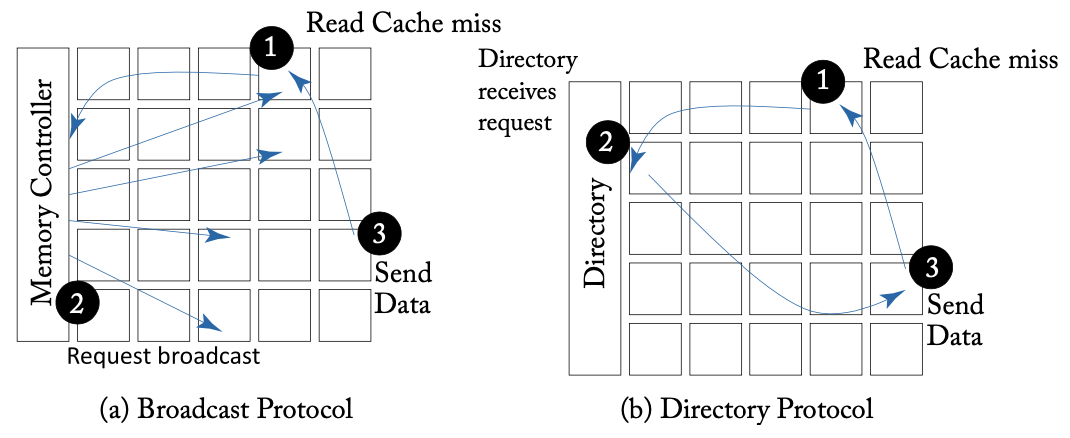 一致性协议对网络发出的请求
一致性协议对网络发出的请求
多处理器系统通常依靠广播或目录来实现一致性协议,两种类型会导致不同的网络传输特性。广播协议中,一致性请求被发送到芯片上所有节点,对带宽要求高,可以依靠两个物理网络:一个用于排序,以及另一个高带宽但无序的用于数据传输。目录协议则依赖于点对点的通信,通过维护一个共享列表,避免了向整个系统广播无效请求。
NoC一致性协议的要求
一致性协议需要几种类型的信息:单播(unicast)、多播(multicast)和广播(broadcast)。目录协议中,大多数请求都是单播的,而广播协议则更复杂。
一致性协议通常也需要两种消息大小。第一种用于不传输数据的一致性请求和响应,包括一个内存地址和一个一致性命令。第二种用于数据传输,包括一个完整的缓存行和内存地址。
协议级网络死锁
 协议级死锁
协议级死锁
共享内存系统要求网络不存在协议级死锁,上图就展示了一种协议级死锁。协议可能需要几个不同的消息类别,一个类别中的请求消息不会导致同一类别中另一个请求消息的产生,但可以触发一个不同类别的消息。当不同类的消息之间存在资源依赖时,就会出现死锁。这里我们描述了三个类别:请求、干预、响应。请求消息包括load、store、更新和写回。干预是由目录发送的消息,请求将修改后的数据传输到新的节点。响应包括无效确认、否定确认(表明请求失败)和数据消息。
可以使用多个虚拟通道来避免协议级死锁,如Alpha 21364为每个消息类别分配了一个虚拟通道,可以打破请求和响应之间的循环依赖。
缓存层次结构对网络性能的影响
节点的设计会对网络的带宽要求有很大影响,在本节中我们着重研究缓存层次结构的影响,包括多个层次的缓存、目录一致性缓存和内存控制器。
在先前展示的共享内存CMP架构一图中,L2缓存是私有的,可以减少L2缓存命中的延迟,但缺点也很明显,几个L2缓存需要复制共享数据,导致缓存利用率降低。由于每个内核都有一个私有L2缓存,只有L2缓存Miss的请求才会进入网络,缓存之间的互联流量减少。在这种设计中,NoC只与每个内核的L2缓存连接,如下图(a)所示。
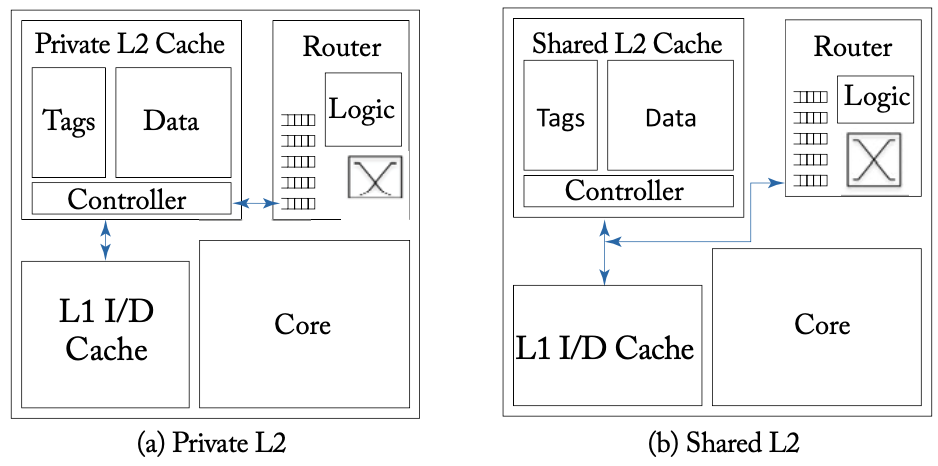 私有/共享L2缓存
私有/共享L2缓存
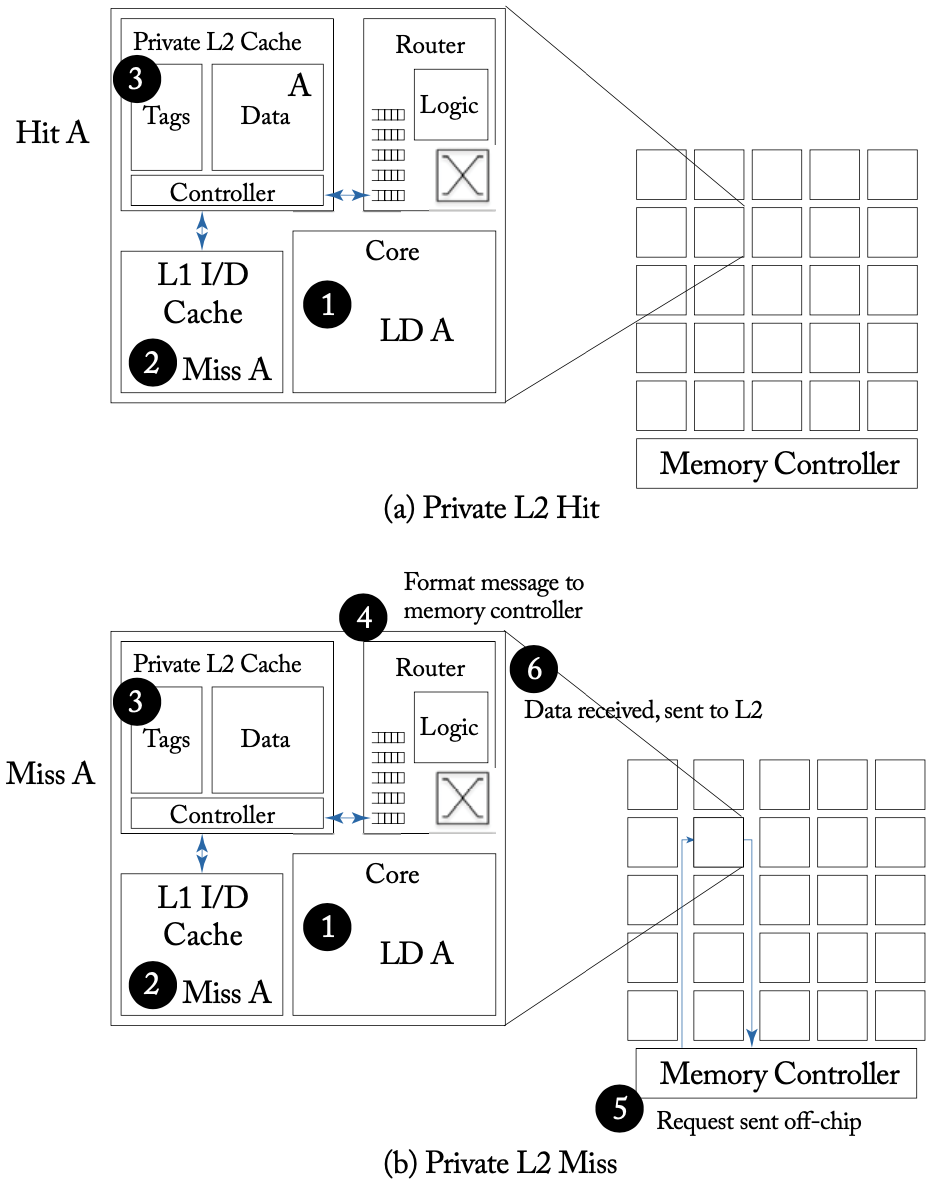 私有L2缓存命中/未命中的网络访问流程
私有L2缓存命中/未命中的网络访问流程
上图展示了私有L2缓存在命中和未命中情况下的例子。私有L2缓存未命中的情况下会产生两次网络访问和一次片外的内存访问。相比之下,共享L2缓存可以更有效地利用存储空间,减少对内存的访问带宽的压力。下图展示了共享L2缓存在命中和未命中情况下的例子。共享L2缓存未命中的情况下会产生最多四次网络访问的请求。
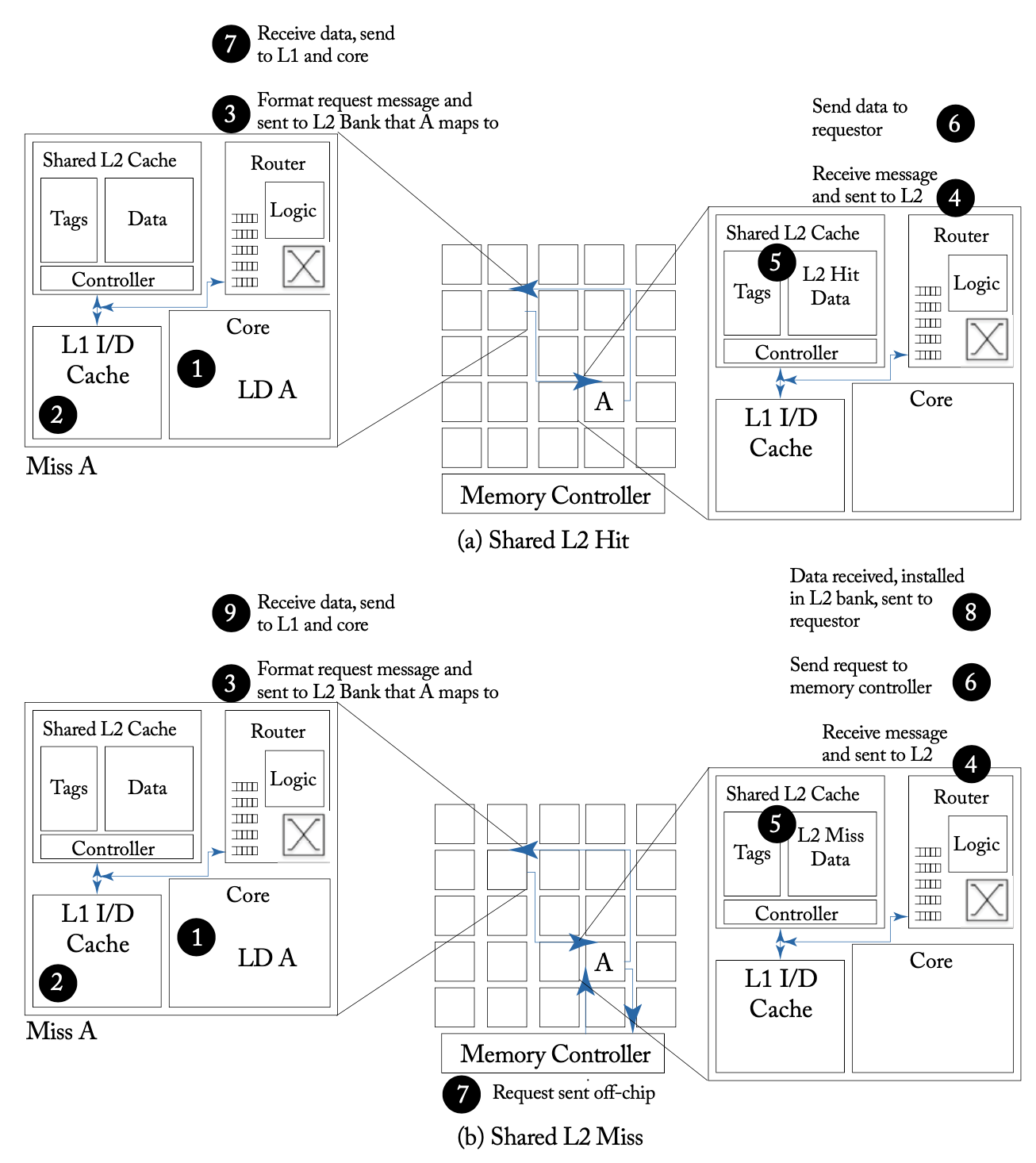 共享L2缓存命中/未命中的网络访问流程
共享L2缓存命中/未命中的网络访问流程
Home节点与内存控制器的设计问题
在目录协议中,每个地址都会静态映射到一个Home节点,存储目录信息,并负责向所有映射到该节点的地址发出一致性请求。在之前提到的两级的缓存层次结构中,L2缓存缺失需要通过内存控制器访问内存,内存控制器也会成为网络传输的热点。如下图所示,内存控制器可以与缓存共享一个网络端口,也可以作为独立的节点放置于网络之中。
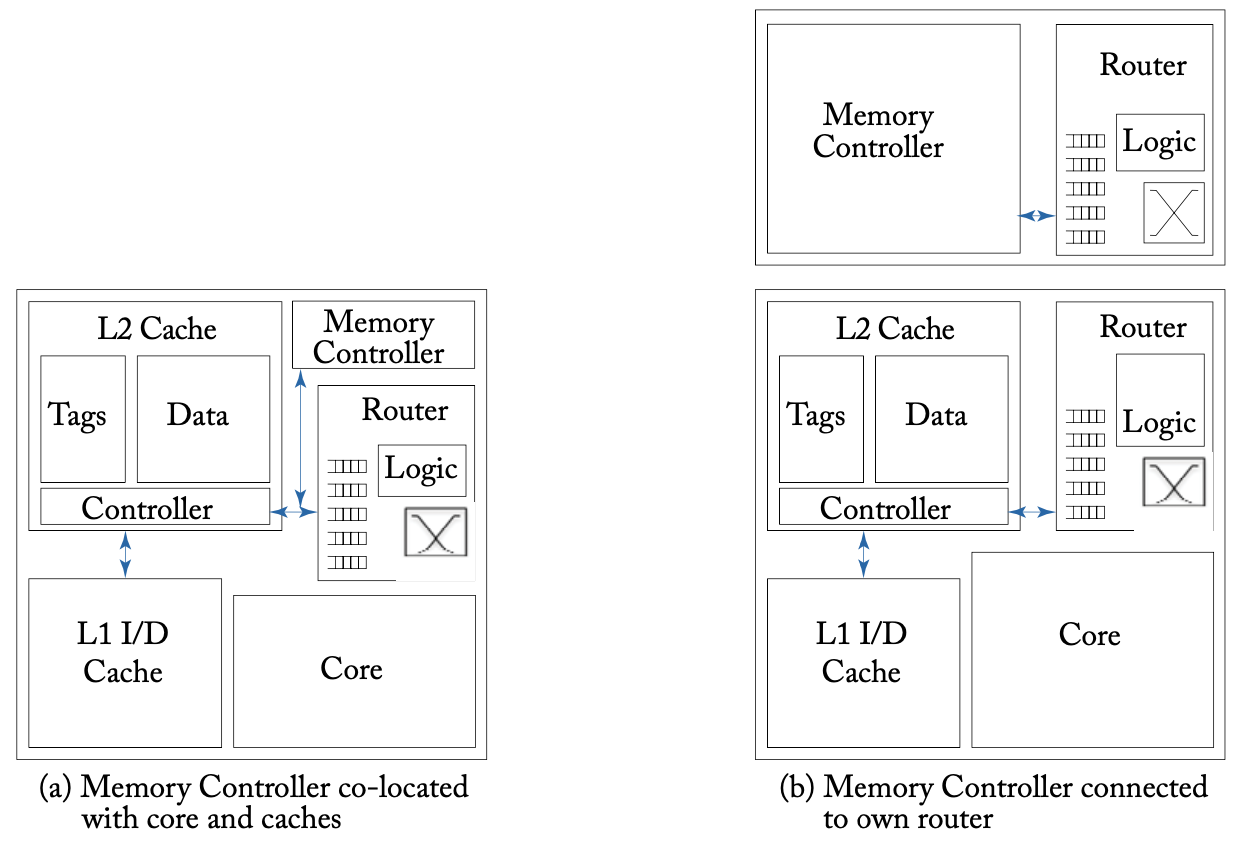 内存控制器
内存控制器
MSHR & TSHR
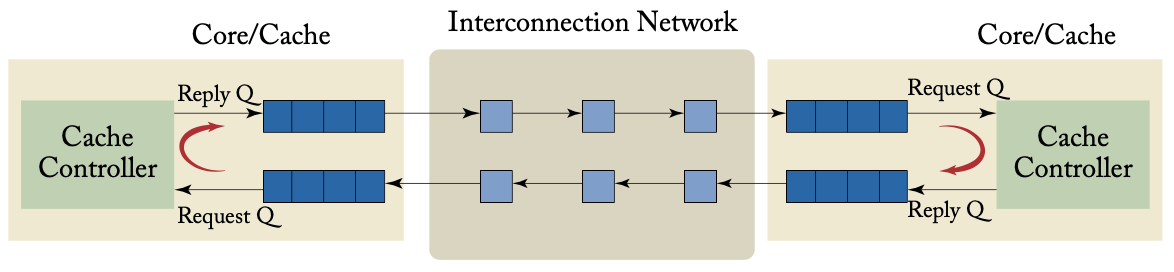
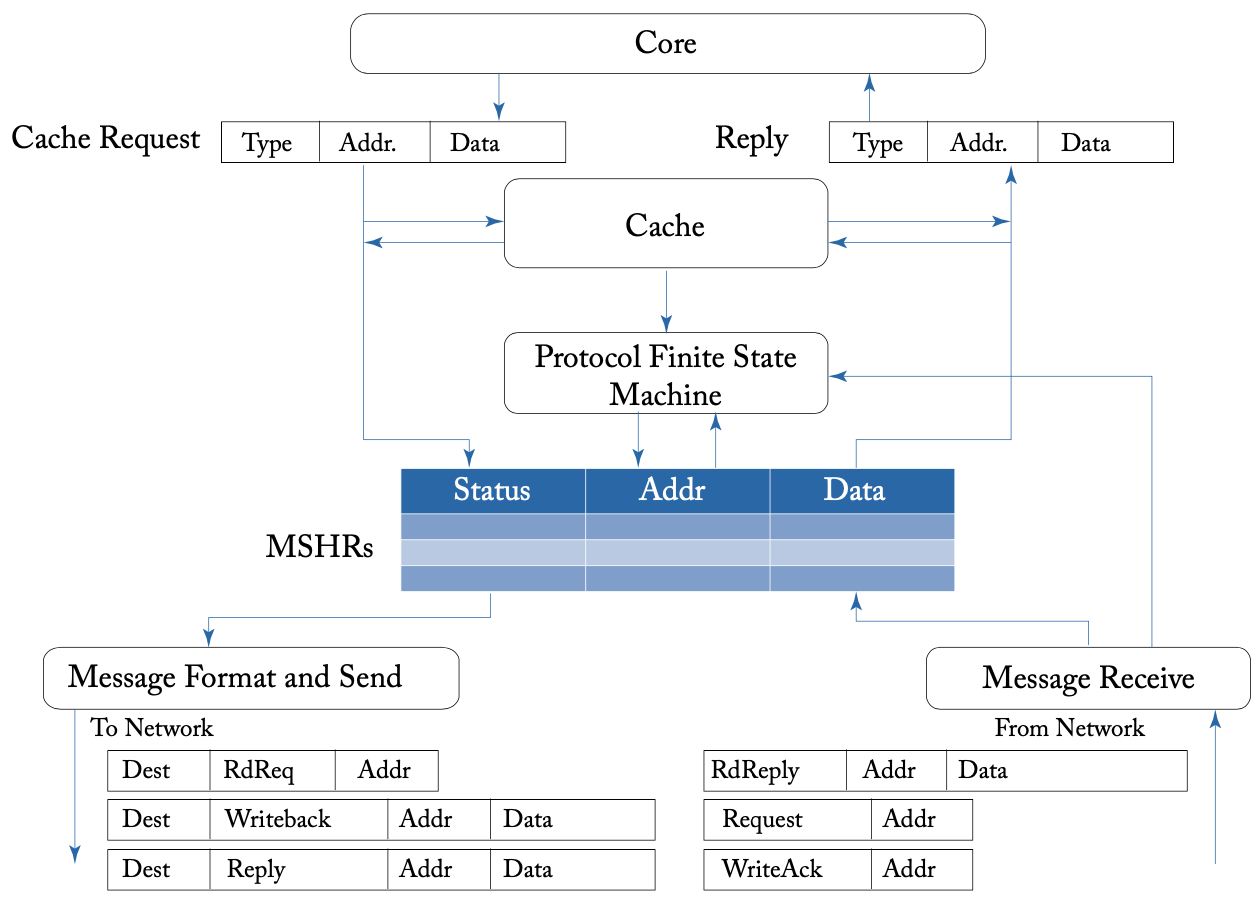 处理器到网络的接口
处理器到网络的接口
对非阻塞缓存而言,上图展示了处理器MSHR到网络的接口。例如,在一个读请求中,MSHR初始为读等待状态,并向网络发出一个消息,消息内容包括目标地址、请求的缓存行地址、消息请求类型。之后MSHR将回复的消息与未完成的请求进行匹配。
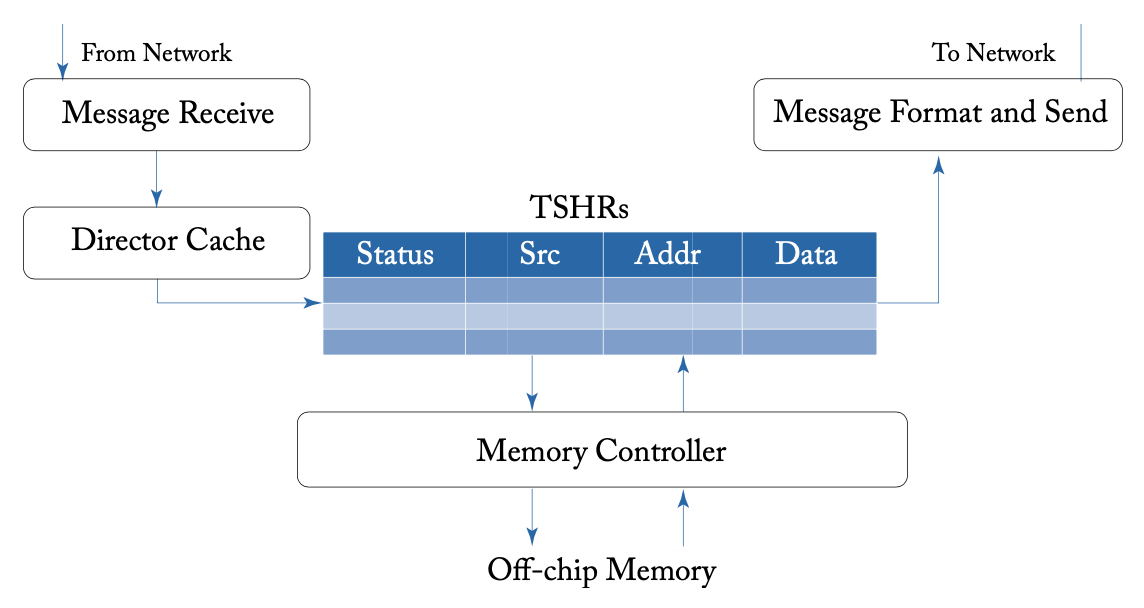 内存到网络的接口
内存到网络的接口
内存到网络的接口则负责接收来自处理器的内存请求并进行恢复,在内存端,由TSHR处理器未完成的内存请求。如果内存控制器可以保证按顺序为请求提供服务,TSHR可以简化为一个FIFO队列。当内存请求完成时,内存到网络的接口将消息发送到网络,发回原始请求者。
消息传递
在消息传递范式中,用户需要调用相关函数来进行消息的发送和接收,把数据从一个进程转移到另一个进程,实现进程之间的通信和同步。
这里我们重点讨论消息传递和网络设计之间的关系。在共享内存范式中,访问共享数据很容易通过一个全局共享的地址空间实现。在消息传递范式中,则需要明确识别数据的拥有者。消息类型和大小是非常灵活的,由软件来承担解码和处理消息的工作,但也会带来较大的开销。在共享内存中,整个网络和消息的存储对程序员是透明的,完全由硬件管理,但消息传递通过减少不必要的通信和大块数据的高效通信来分摊通信相关的额外开销和延迟,其硬件成本和设计复杂性通常低于共享内存,但也在系统的其他地方引入了额外的复杂性。
消息传递分为阻塞式和非阻塞式。阻塞或同步消息传递需要发送者等待,直到接收者确认消息,虽然概念上很简单,但可能导致死锁问题,例如,两个进程同时发出发送命令并等待,两个进程都无法继续执行接收命令,并将一直等待。非阻塞或异步的消息传递允许发送者在发送消息后立即进行之后的工作,消除了与死锁有关的问题,但也带来了存储未完成消息的额外复杂性。
关于消息的存储,有几种不同的策略。消息可以直接写入专用的缓冲或寄存器,也可以通过MMIO存储在内存中。接收者可以通过中断或对内存映射的位置进行轮询来访问消息。
NoC接口标准
NoC需要遵循标准化的协议,才可以和其他具有相同标准接口的IP块互相通信、即插即用。目前SoC中广泛使用的片上通信标准有ARM的AMBA、意法半导体的STBus、Sonics的OCP、OpenCores的Wishbone等。在此我们以ARM的AMBA AXI为例,讨论这些标准的一些共同特征。更详细的内容可以参考 On-Chip Communication Architectures: System on Chip Interconnect,其中详细介绍了现有的片上总线的协议。
总线事务的语义
连接到网络的节点被定义为主设备和从设备,通过事务进行通信。主设备发出请求开始事务,从设备接收并随后处理事务,当从设备对原始请求做出响应时,事务就完成了。例如,处理器内核是主设备,通过向内存模块发出写请求来启动一个新的事务,内存模块是从设备,执行写请求并回复写确认响应。
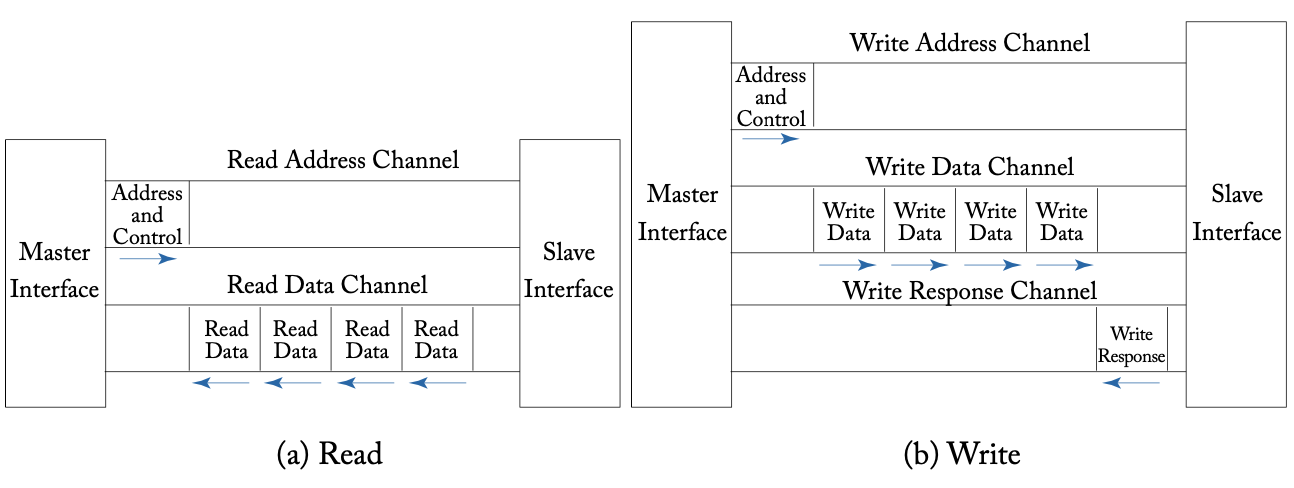 AXI读通道与写通道
AXI读通道与写通道
AMBA AXI协议中的每个事务都在地址通道上发送地址和控制信息,而数据则在数据通道上以突发方式发送,写入有一个额外的响应通道,如上图所示。这些通道的宽度可以从8位到1024位不等。主设备发起写请求时,网络接口在写地址通道封装并翻译地址为从设备的目标地址,作为消息的header,而写数据通道中的数据作为消息的主体。随后消息被分解为包,发送到网络中,在目的地重新组装为完整的消息,地址放入AXI写地址通道,数据放入AXI写数据通道。在收到消息的最后一个flit后,网络接口将生成一个写响应消息,并将其送回主设备,送入主设备的AXI写响应通道。
乱序事务
之前提到的标准中大多在最新版本放宽了总线事务的排序,例如AXI放款了请求和响应之间的顺序,即响应不需要按照与请求相同的顺序返回,如下图所示,允许多个未完成的请求同时存在,从设备以不同速度运行。
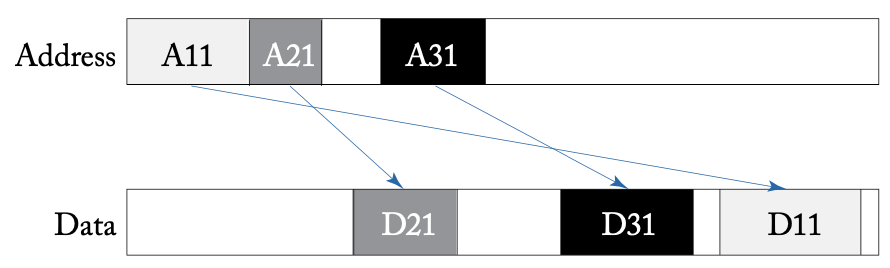 AXI协议允许乱序事务
AXI协议允许乱序事务
一致性
AMBA 4 ACE (AXI Coherency Extensions) 以及更新的 AMBA 5 CHI (Coherent Hub Interface) 提供了全系统的一致性支持,以额外通道的形式来支持各种一致性信息、snoop回复控制器、barrier的支持等,使ARM大小核之类的架构可以很方便地共享内存。