在异构架构中,我们可以在CPU和加速器之间暴露一个全局的共享内存接口,我们假设CPU、GPU等设备共享相同的物理内存(如手机上的SoC这种情况),如下图所示。在这种系统中,共享内存会引发一些新的问题,如什么是内存一致性模型?内存一致性模型如何实现?加速器和处理器的私有缓存如何保持一致?我们接下来首先讨论加速器内的内存一致性和缓存一致性,重点是GPU,然后讨论跨加速器的内存一致性和缓存一致性。
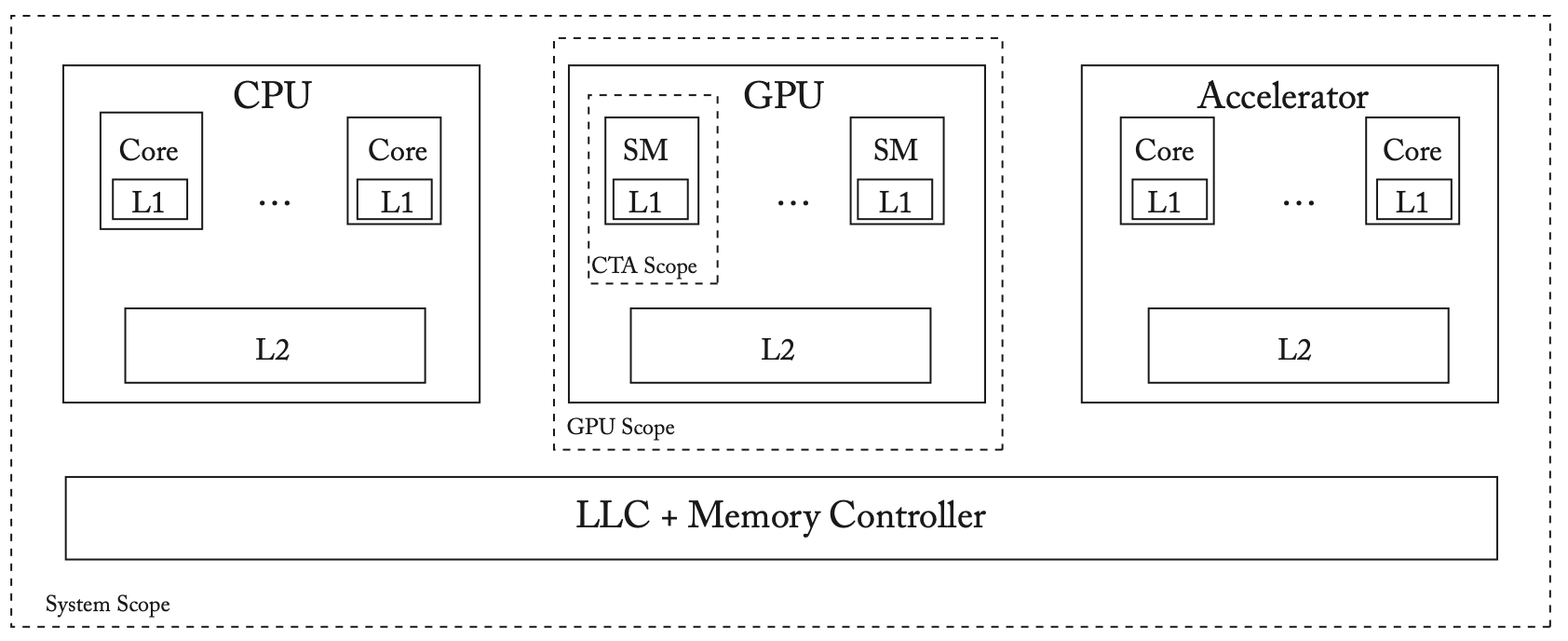 异构SoC系统模型
异构SoC系统模型
GPU的内存一致性和缓存一致性
早期GPU的架构与编程模型
早期GPU主要为并行图形工作负载设计,特点是数据并行度高,但数据共享、同步和通信程度低。
GPU架构
GPU通常有几十个内核,叫做流式多处理器(Streaming Multiprocessors,SM),每个SM都是高度多线程的,能够运行上千条线程,映射到SM上的线程共享L1缓存和本地scratchpad内存,所有的SM都共享一个L2缓存。GPU通常将线程分组执行,称为warps,一个warp中的所有线程共享PC和堆栈,可以使用掩码来执行独立的线程,表明哪些线程在执行,哪些线程没有在执行,这种并行方式就是我们常听说的SIMT。但是最近,GPU开始允许一个warp中的线程有独立的PC和堆栈,允许线程独立调度,我们接下来也假设线程是可以独立调度的。
由于图形工作负载并不经常共享数据或进行同步,早期GPU选择不在L1缓存实现硬件的缓存一致性。
GPU编程模型
和CPU类似,GPU也有一套虚拟ISA,同时也有一套更高级别的语言框架,如CUDA和OpenCL,框架中的高级语言被编译成虚拟的ISA,并被翻译为本地的二进制文件。GPU虚拟ISA和高级语言框架通过被称为作用域(scope)的线程结构,向程序员暴露GPU架构的层次结构。和CPU相比,GPU线程被分组为叫做Cooperative Thread Arrays(CTA)的集群。CTA作用域指来自同一个CTA的线程集合,保证映射到相同的SM,并共享同一个L1huancun。GPU作用域指的是来自同一个GPU的线程集合,可以来自相同或不同的CTA,并共享L2缓存。最后,系统作用域指整个系统所有线程的集合,共享LLC缓存或统一的共享内存。
这种方式可以在没有硬件缓存一致性的情况下,用软件的方式实现数据同步和通信。
GPU内存一致性
GPU支持宽松一致性模型,通过FENCE指令进行同步,但是由于没有硬件缓存一致性,GPU的FENCE只针对属于同一CTA的其他线程。GPU的store指令也不保证原子性。
因此,早期GPU明确禁止在CTA组之间进行数据同步,但实践中可以通过绕过L1,在L2上进行同步。这种方案也有一些问题,绕过L1会导致性能下降,且程序员需要仔细地编写程序。
测验问题8:GPU不支持硬件缓存一致性,因此无法实现内存一致性模型。
答:错误。早期的GPU不支持硬件缓存一致性,但是支持作用域内的宽松内存一致性模型。
GPGPU的内存一致性和缓存一致性
GPGPU最好满足以下特点:
严格而直观的内存一致性模型,允许在所有线程之间进行同步
一个能够实现内存一致性模型的缓存一致性协议,允许高效的数据共享和同步,且保持常规GPU架构的简单性,因为GPU的主要任务仍然是图形工作负载
我们可以使用类似多核CPU的方法来实现缓存一致性,使用一种与内存模型无关的协议。然而这种方法并不适用于GPU,主要有两个原因。首先,类似于CPU的缓存一致性协议在GPU环境下会产生很高的通信开销,因为L1缓存的总容量通常与L2相当,甚至更大,会产生很大的面积开销,设计也非常复杂;其次,由于GPU保持着数千个活跃的硬件线程,因此需要跟踪相应数量的一致性事务,需要大量的硬件开销。
具体的技术细节可以参考原书(埋坑,GPU的部分确实现在看来有些难理解,等之后学习了GPU的架构之后再回来填坑)。
其他异构系统
我们开始进一步讨论如何在多个设备的系统中暴露一个全局的共享内存接口,难点在于每个设备都可能通过不同的一致性协议来实现不同的内存模型,当多个内存模型不同的设备被集成在一起时,异构系统的内存模型是什么样的?如何对这种系统进行编程?如何整合多个设备的缓存一致性协议?我们接下来简单讨论这些问题,并概述设计空间。
异构系统的内存模型
如果两个设备A和B连接在一起并共享内存,这种情况下的内存模型是什么样的?一个符合直觉的答案是选择其中较弱的一个作为整体的内存模型,但如果两个内存模型无法比较,这种答案就不可行了。即使两者可以比较,可能也会有更好的答案。
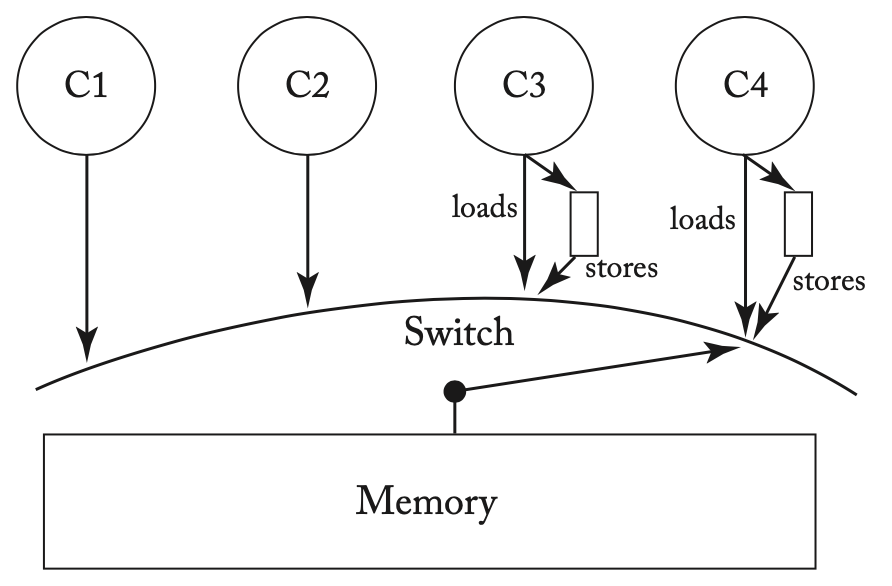 四个设备组成的异构系统
四个设备组成的异构系统
在如上所示的异构系统中,C1和C2内存模型为SC,C3和C4内存模型为TSO。考虑下面的例子,在第一个例子中,有可能r1和r2同时读到0,但在第二个例子中插入了FENCE后,r1和r2就不能同时读到0了,但需要注意的是在SC的线程上仍然不需要插入FENCE,这种系统实际上产生了一个不同于SC和TSO的复合内存模型。
 Dekker算法的例子
Dekker算法的例子
在这种系统中变成也是比较困难的,很难直接精确定义复合内存模型,更好的办法可能是使用HSA或OpenCL等进行编程。
异构系统的缓存一致性协议
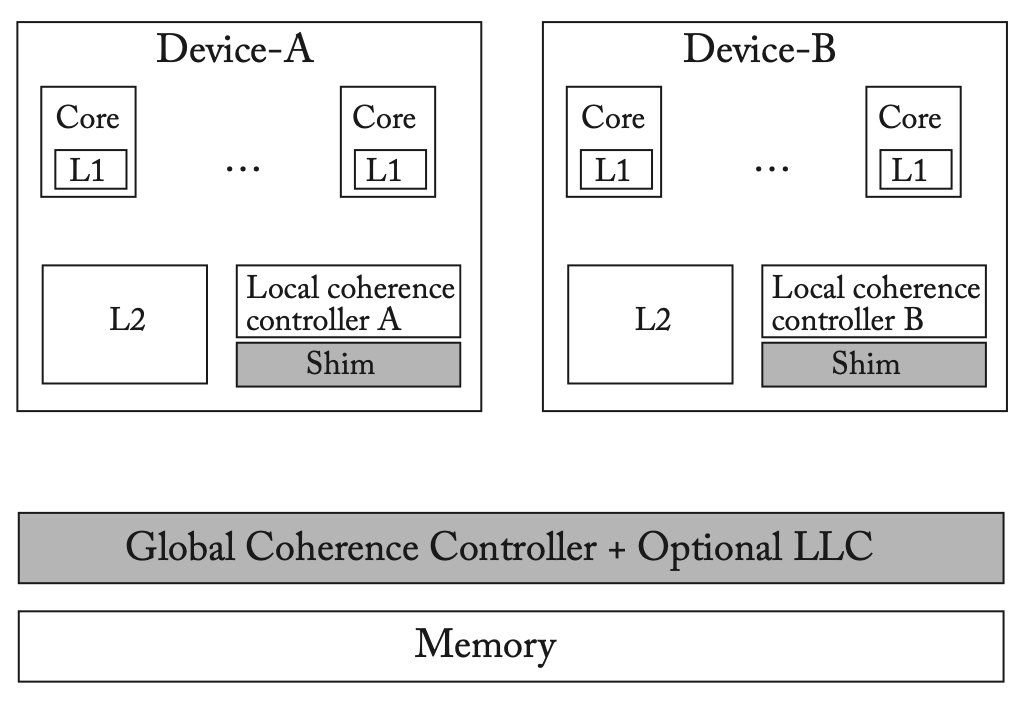 通过分层缓存一致性来集成多个设备
通过分层缓存一致性来集成多个设备
考虑两个多核设备A和B,每个设备都有自己的内存模型,并通过不同的缓存一致性协议来实现内存模型,如上图所示。我们应该如何将两个设备集成到一个共享内存异构系统中,并将两个缓存一致性协议正确连接在一起?答案取决于每个设备的内存操作是否满足自己的内存排序规则。
分层缓存一致性
在分层缓存一致性系统中,本地缓存一致性控制器收到请求后,首先试图在本地满足该请求,如果无法满足就转发到全局一致性控制器,再转发到另一个设备的本地缓存一致性控制器。在这种设计中,全局控制器必须有足够丰富的接口来满足各个设备本地控制器发起的请求,且每个本地控制器必须用shim来扩展,作为两个控制器之间的接口转换。相关的一些例子可以参考原文。
减少异构系统缓存一致性的带宽需求
在异构系统中,内核之间的缓存一致性通信带宽可能成为性能瓶颈。一种解决思路是采用粗粒度的缓存一致性,比如在GPU本地以page大小的粒度进行跟踪,如果缓存未命中且已知该位置对应的page对GPU来说是私有的或只读的,就不需要访问全局的目录,而是可以从高带宽的总线从内存直接访问。
CPU-GPU系统中缓存一致性的一个低复杂度解决方案
我们可以采用选择性的GPU缓存,任何被映射到CPU内存的数据都不会缓存在GPU中,任何来自GPU内存的数据,如果目前被缓存在CPU中,也不会被缓存在GPU中。这个简单的策略可以很好地实现缓存一致性。为了实现这种方法,GPU维护一个粗粒度的目录,维护当前由CPU缓存的数据,当CPU访问GPU内存中的一个缓存块时,这个缓存块所在的区域就被插入到目录中,目录中所有的位置都不会被缓存到GPU中。不过这种方法也有坏处,即任何被CPU缓存的数据都必须从CPU中取回,为了解决这个问题需要进行进一步的优化,如GPU对CPU的请求进行合并、在GPU上加入一个特殊的CPU侧的缓存等。