之前我们讨论了宽松内存一致性模型的一些基本概念,并介绍了XC内存模型,在这一节中我们继续深入讨论宽松内存模型。
宽松内存模型案例研究:RISC-V弱内存一致性模型(RVWMO)
RVWMO可以理解为RC和XC的混合体。和XC一样,RVWMO是根据全局内存顺序来定义的,并且有几种FENCE指令的变体。和RC一样,load和store可以携带一些属性:load指令可以携带ACQUIRE,存储指令可以携带RELEASE,RMW指令可以携带RELEASE、ACQURE或两者同时。
RELEASE/ACQUIRE顺序
ACQUIRE分为ACQUIRE-RC_PC和ACQUIRE-RC_SC,RELEASE分为RELEASE-RC_PC和RELEASE-RC_SC。load/store可以携带任意一种ACQURE/RELEASE,而RMW智能携带RC_SC。我们保证以下顺序:
ACQUIRE -> Load, StoreLoad, Store -> RELEASERELEASE-RC_SC -> ACQUIRE-RC_SC
FENCE顺序
有一个强FENCE指令,即FENCE RW, RW,和XC中的FENCE一样。还有其他五种组合,包括:
FENCE RW, WFENCE R, RWFENCE R, RFENCE W, WFENCE.TSO
 RVWMO:FENCE和RELEASE-ACQUIRE顺序保证了r1和r2不会同时为0
RVWMO:FENCE和RELEASE-ACQUIRE顺序保证了r1和r2不会同时为0
语法依赖引起的顺序
RVWMO在某些方面的约束比XC强,如地址、数据和控制依赖可以约束RVWMO中的内存顺序。
 地址依赖引起的顺序:是否可能
地址依赖引起的顺序:是否可能r1=%data2且同时r2=0?
 数据依赖引起的顺序:是否可能
数据依赖引起的顺序:是否可能r1=42且同时r2=42(42是load推测值)?
 控制依赖引起的顺序:是否可能
控制依赖引起的顺序:是否可能r1=42,导致S1间接影响自己是否执行?
在RVWMO中,以上三个问题的答案都是不可能。需要注意的是,上述所有依赖关系都是指语法上的依赖关系,而非语义上的依赖关系,也就是说是否存在依赖关系由寄存器决定,而非具体的值决定。
 流水线依赖
流水线依赖
除此以外,RVWMO还有流水线依赖关系,上图与以下内容摘自gitee上的一篇blog。
这四段特殊的代码范例都是前两条指令构成语法依赖,第三条指令进行相关的load或不知是否相关的store。RISC-V根据“几乎所有真实CPU流水线执行机构的行为”,将指令a和c的关系称为流水线依赖,并明确规定不能乱序。
约束代码1和2的出发点是“在store地址或值未知时,不能(无法)load这个store的值”:b的地址或值未确定时,不能执行c,又因为b的地址或数据依赖a,因此c在全局内存顺序上不能在a之前。
约束代码3和4的出发点是“前面load或store地址未知时不能store”:b地址未确定时c不能执行,以防止地址冲突,又因为b的地址依赖a,因此c在全局内存顺序上也不能在a之前。
同一地址顺序
在XC中,对同一地址的内存访问遵循TSO顺序。类似于XC,RVWMO对同一地址的访问同样要求Load -> Store和Store -> Store,不过在任何情况下都不要求Load -> Load顺序。不过关于Load -> Load顺序,同样引用自之前的blog,有以下需要注意的点。
对于同一地址的两个load,只要后一个load不会读到更旧的值,就不约束两者的内存顺序,这个特性称为Coherence for Read-Read pairs。反过来说,当且仅当两个load中间没有对这一地址的store,且两个load返回不同的值时(实际上是返回不同的store,不一定值不相同),要保证两个load不乱序。
RMW
RISC-V支持两种类型的RMW操作:原子内存指令(AMO)和lr/sc(保留读和条件写)。不同的是,前者只是一条指令,而后者两条指令通常组合使用。
比较不同的内存模型
我们先前讨论过如何比较不同的内存模型。我们发现,RVWMO比TSO宽松,而TSO又比SC宽松。不过不同的宽松内存模型可能无法比较,如Alpha、ARM、RVWMO之间无法进行比较。
宽松内存模型怎么样?
可编程性:我们引入了DRF for SC的概念,宽松内存模型的可编程性还是可以接受的,不过深入理解可能比较困难(如对于编译器工程师而言)。
性能:宽松的内存模型可以比TSO有更好的性能,但是对于有许多核心的处理器来说,两者之间的差异比较小。
可移植性:在保证DRF for SC的前提下,可以比较容易地进行移植,但在一般情况下,尤其是在无法比较的内存模型之间进行移植可能是比较困难的。
精确:很多宽松内存模型没有被正式精确定义,或者定义很模糊。
高级语言模型
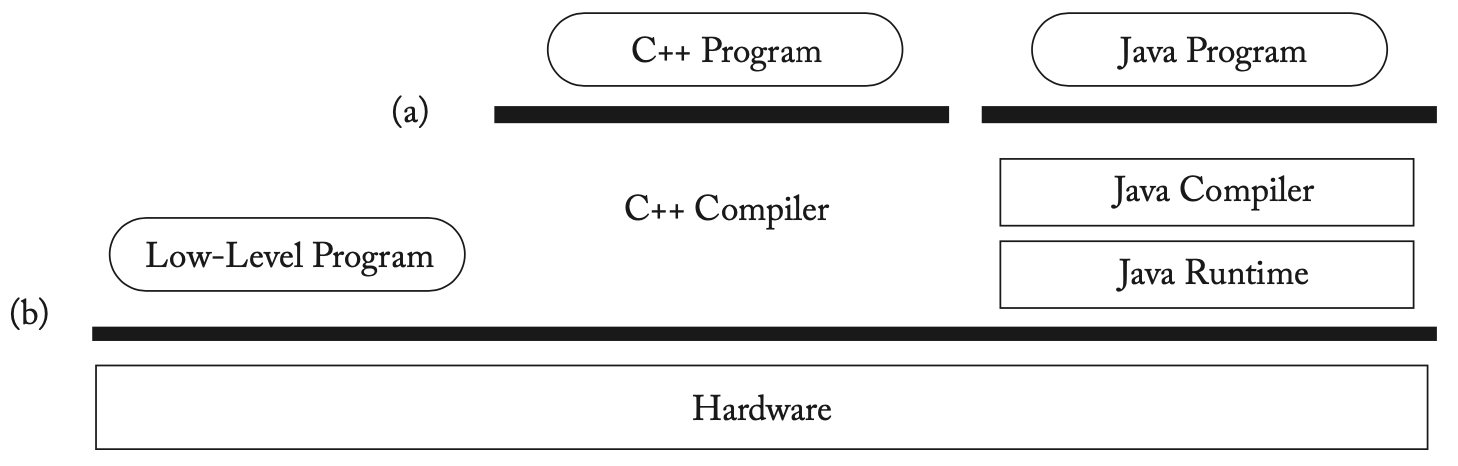 高级语言与硬件的内存模型
高级语言与硬件的内存模型
为高级语言定义一套内存模型也同样重要,我们需要规定:
使用高级语言的程序员应该期望得到什么样的结果
编译器、运行时系统与硬件应该怎样实现
Java可能是第一个包含了内存模型的主流高级语言,程序员可以使用一些高级语言的特性来避免数据竞争。
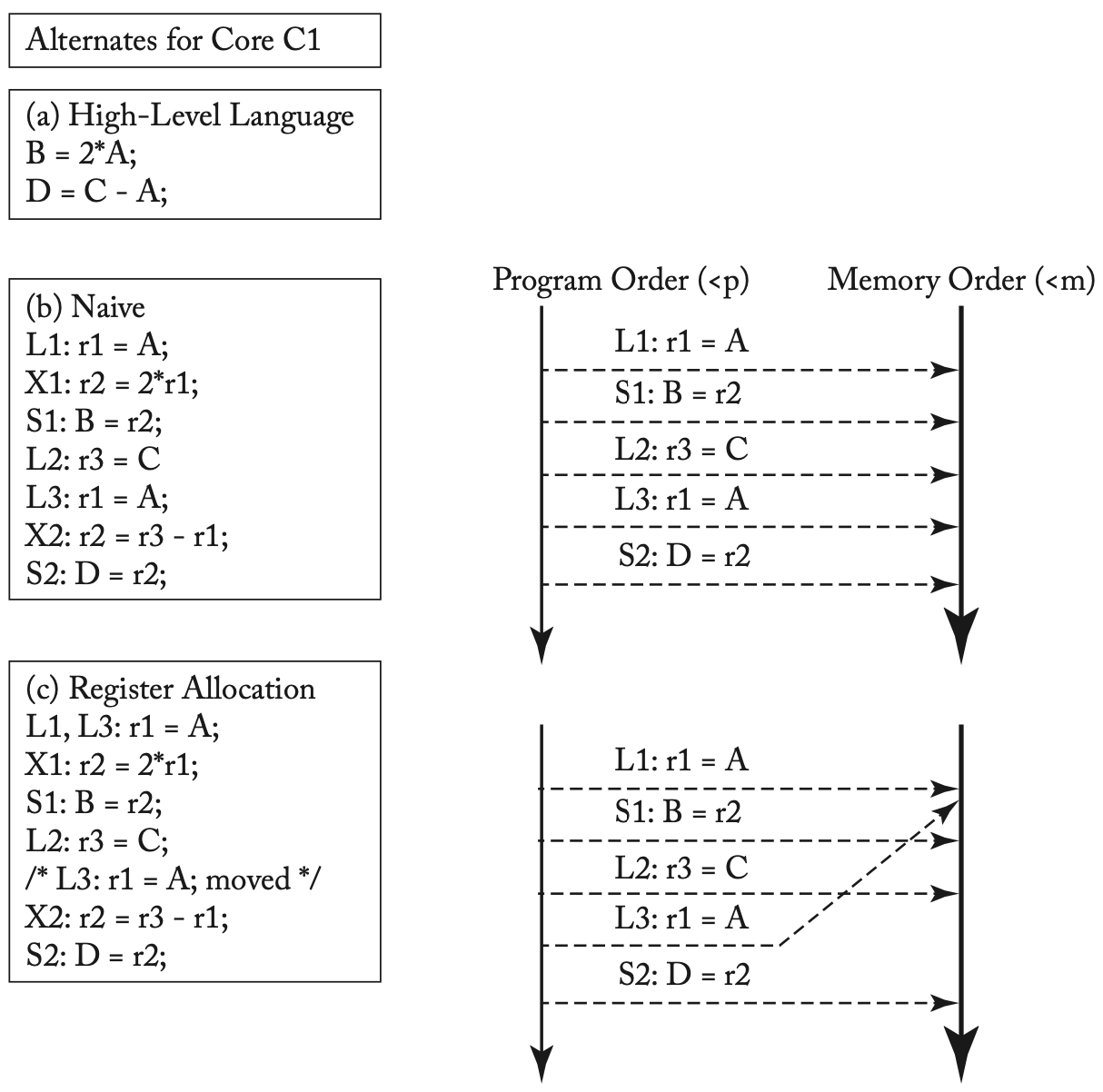 寄存器分配会影响内存顺序
寄存器分配会影响内存顺序
编译器可能会对内存指令进行重新排序,或消除一些内存访问,如上图中的例子所示。但是,假设由另一个核心C2可以更新A和C的值,C1只能观测到C的更新,这种执行方式在高级语言级别违反了SC。
更一般地来说,一个线程可以观测到数据竞争或者非SC操作的条件是什么?Java要求所有程序都有安全保证,但C++出于性能的考虑,支持各种比SC更弱的同步操作。Java和C++必须按照以下目标对所有情况规定具体的行为:
允许针对所有高性能DRF程序的优化
明确规定所有程序的允许行为
这种明确规定尽量简单
如何比较好地满足上述三个目标仍然是一个开放性的问题。
测验问题5:相对于高级语言的一致性模型(如Java),程序员编写适当的同步代码,不需要考虑架构的内存一致性模型。
答:不一定。对通常的应用程序来说,确实不需要考虑架构级别的内存模型,但对编译器或运行时系统的程序员来说,就需要仔细考虑了。