TSO(Total Store Ordering)是一个被广泛使用的内存模型,在SPARC中首次提出,并在x86架构中使用,RISC-V也提供了TSO扩展,即RVTSO。
为什么需要TSO/X86
长期以来,处理器内核使用write buffer来保存已提交的store指令,直到内存系统可以处理这些store请求。当store指令提交时,store请求进入write buffer,而当需要写入的缓存行在内存系统中可以保证缓存一致性时,store请求就退出write buffer。对单核处理器来说,如果在write buffer中存在对地址A的store,那么碰到对地址A的load指令时,可以直接返回即将store的值,或者也可以选择停顿load指令。
问题发生在有多个这样的处理器的时候,如下图所示。
 r1和r2可以同时为0吗?
r1和r2可以同时为0吗?
两个处理器核可以按照如下顺序执行代码:
C1执行S1,但将store NEW的请求放入write buffer中。
C2执行S2,但将store NEW的请求放入write buffer中。
接下来,两个核心分别执行L1和L2,load的值都为0。
最后,两个核心的write buffer将NEW值写入内存。
执行完毕后,r1和r2同时为0,违反了SC。可能的解决方法有直接禁用write buffer,但会影响性能,或者使用更激进的、推测性的SC实现,但增加了复杂性,且可能浪费检查内存一致性违规与处理错误情况的功耗。SPARC和x86的选择时放弃SC,支持一种全新的内存模型,以更好地支持基于FIFO的write buffer。
TSO/X86的基本概念
SC要求在以下所有四种连续执行指令的组合中保留load和store的程序顺序:
Load –> Load
Load –> Store
Store –> Store
Store –> Load
TSO包含前三个约束,但不包括第四个。需要注意的是,上面的第三条约束要求write buffer必须是FIFO,以保证store-store的顺序。这种改动对大多数程序来说影响不大,如下图中在上一章中出现过的例子,在TSO模型中仍然可以正确执行。
 r2是否总是会被更新为NEW?
r2是否总是会被更新为NEW?
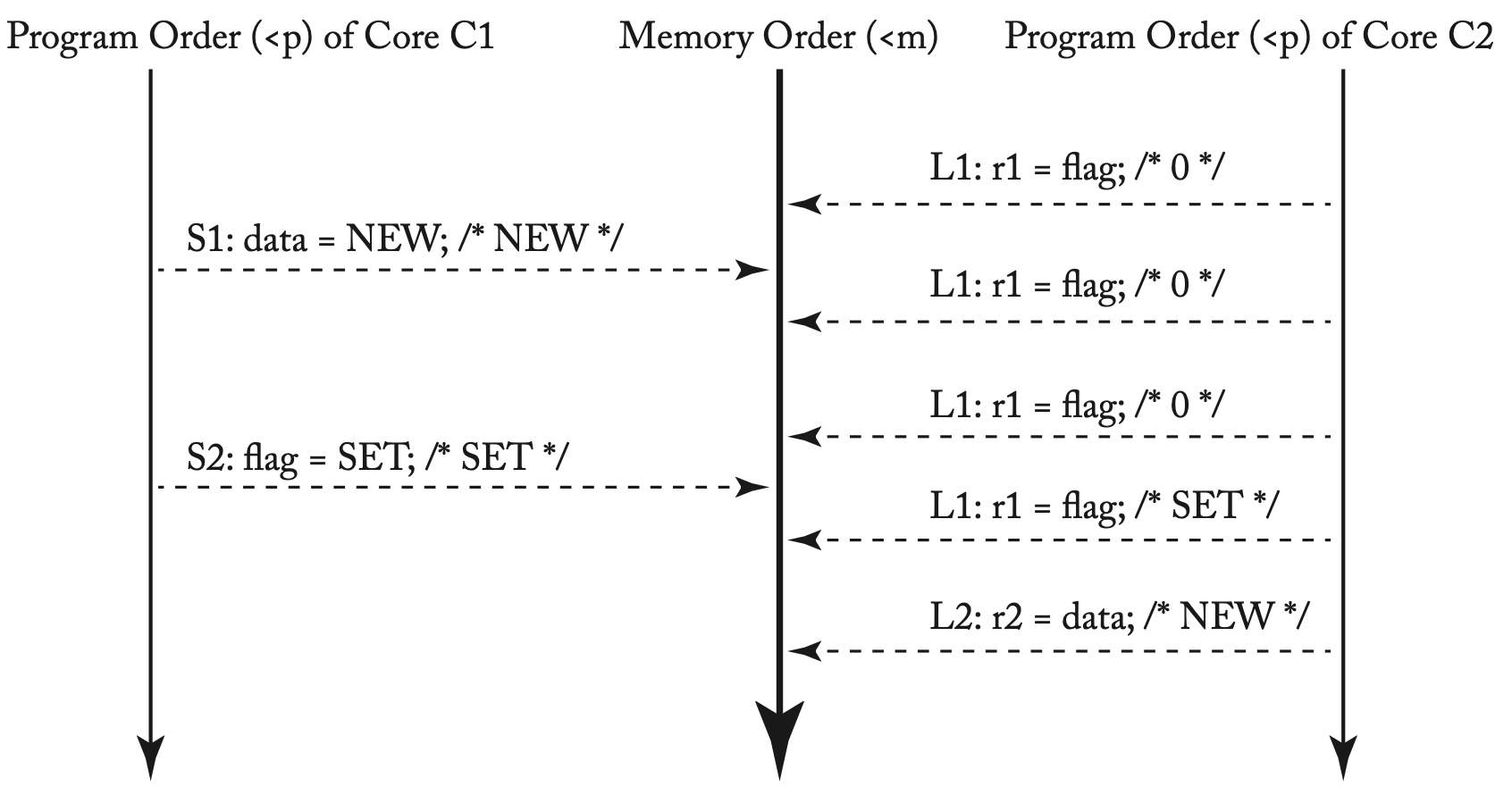 TSO模型下一种可能的执行情况
TSO模型下一种可能的执行情况
下面是另一个比较有意思的例子,注意每个处理器核仍必须按照程序顺序观察到自己所发出的store请求的效果,因此r1和r3都会被更新为NEW值。
 r1或r3是否可能为0?
r1或r3是否可能为0?
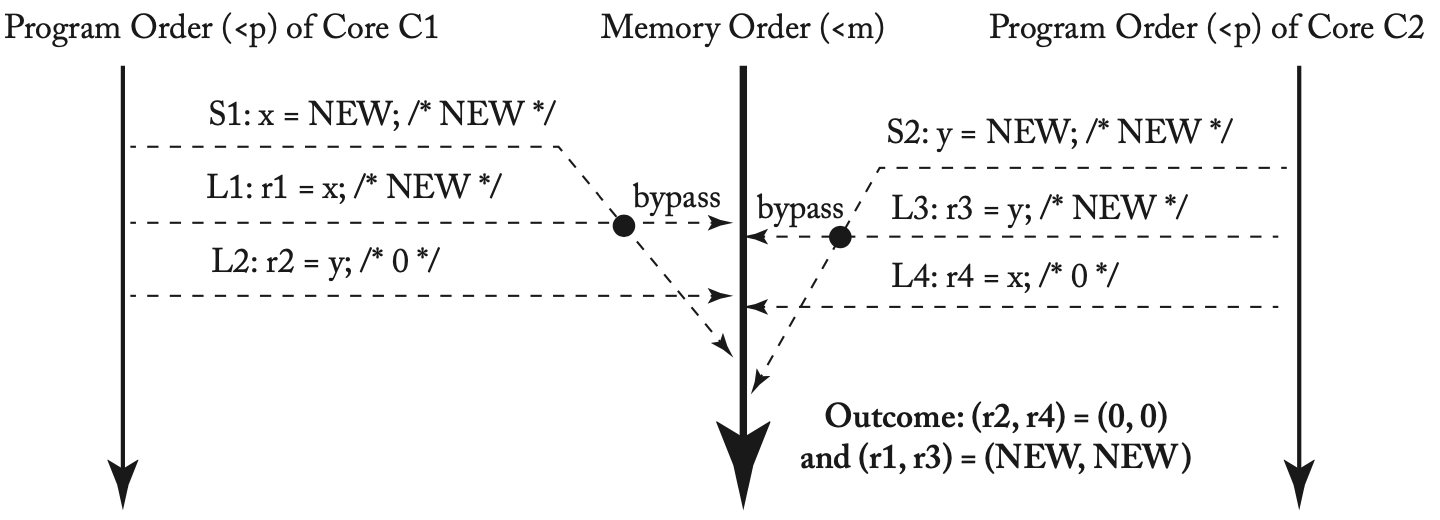 上面的例子在TSO模型下的执行情况
上面的例子在TSO模型下的执行情况
形式语言的定义
所有的核按照程序顺序来把load和store指令插入
<m顺序,且顺序与内存地址无关,可能有以下四种情况:若
L(a) <p L(b),则L(a) <m L(b)若
L(a) <p S(b),则L(a) <m S(b)若
S(a) <p S(b),则S(a) <m S(b)使用FIFO write buffer
每一次load都会从之前最后一次相同地址的store中获取值,或从write buffer中对相同地址的store请求通过旁路获取值,即
L(a)的值为MAX_<m {S(a) | S(a) <m L(a) or S(a) <p L(a)},其中MAX_<m/<p表示内存/程序顺序中最后出现的那一项,且程序顺序优先(即write buffer绕过了内存系统的其余部分)。定义FENCE:
若
L(a) <p FENCE,则L(a) <m FENCE若
S(a) <p FENCE,则S(a) <m FENCE若
FENCE <p FENCE,则FENCE <m FENCE若
FENCE <p L(a),则FENCE <m L(a)若
FENCE <p S(a),则FENCE <m S(a)
不过由于TSO只放宽了对store-load的顺序约束,FENCE相关的定义也可以是:
若
S(a) <p FENCE,则S(a) <m FENCE若
FENCE <p L(a),则FENCE <m L(a)
我们选择第一种,也就是让TSO的FENCE作为所有内存请求的分界,这样设计比较简单,不影响正确性,且和之后更宽松的内存模型中的FENCE保持一致。下表总结了TSO的顺序规则,和SC的表有两个最重要的区别:Op1是store、OP2是load的情况对应了B,表示bypassing;额外包含了FENCE,而在SC中不需要FENCE。
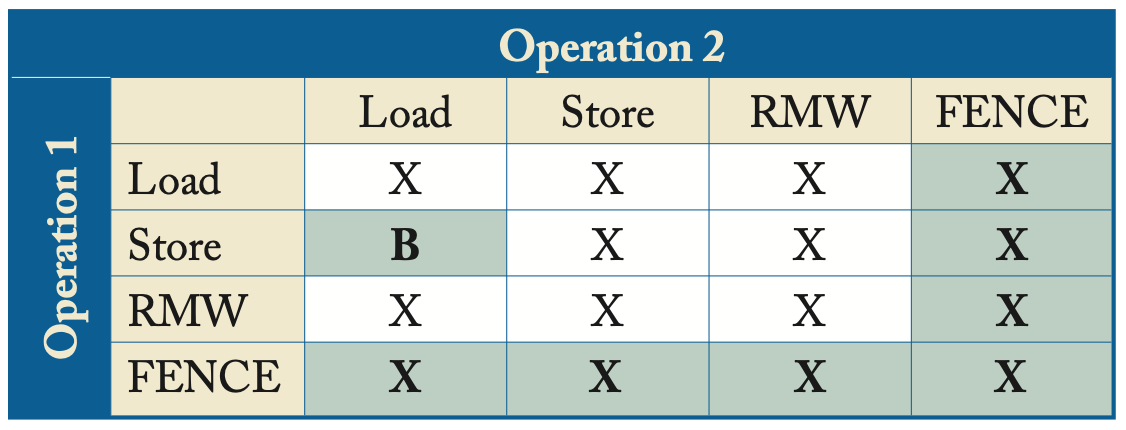 TSO顺序规则(X表示强制顺序,B则表示如果访问同一个地址,需要bypassing)
TSO顺序规则(X表示强制顺序,B则表示如果访问同一个地址,需要bypassing)
实现TSO/X86
有意思的是,人们普遍认为x86内存模型等同于TSO,然而Intel和AMD从来没有保证这一点,但是Sewell等人在x86-TSO: A rigorous and usable programmer’s model for x86 multiprocessors提出了x86-TSO模型,该模型有两种形式,如下图所示,作者证明两者是等价的。一方面,x86-TSO和x86的非官方的规则保持一致,且通过测试;另一方面,在Intel和AMD的平台上没有发现违反x86-TSO模型的情况。注意这仍然不能完全保证x86-TSO和x86的内存模型完全一致。
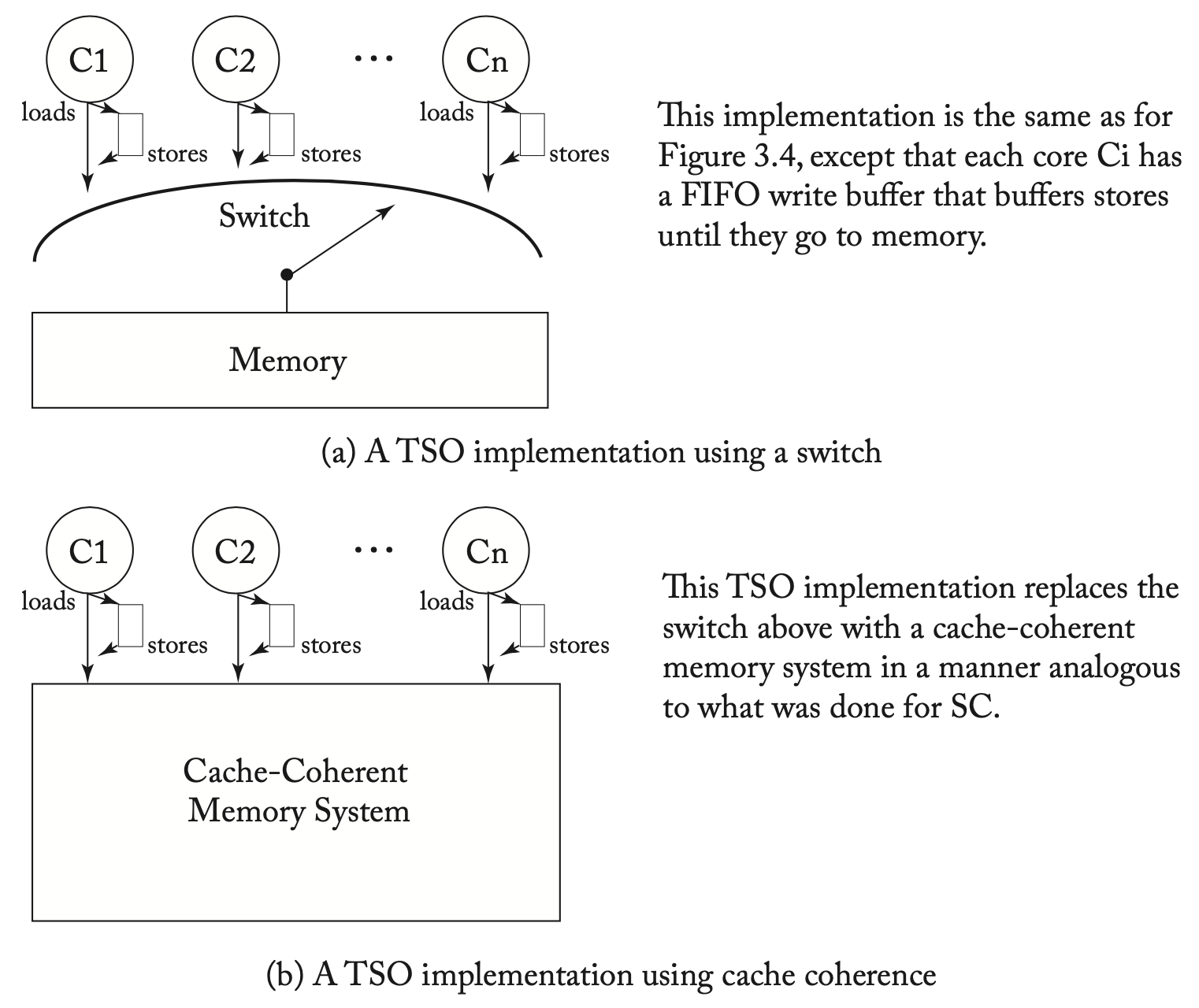 两种TSO的实现
两种TSO的实现
对于SC来说,上图a中利用开关的实现可以被b中一个缓存一致的内存系统替代,在TSO中也同理,唯一的区别就是相比SC在每个处理器核上多了一个基于FIFO的write buffer。另外,在多线程中,TSO的write buffer在逻辑上对每个线程都是私有的,因此在一个多线程内核中,一个线程上下文不应该从另一个线程的write buffer中通过旁路获取数据,这种逻辑上的分离可以通过每个线程实现单独的write buffer实现,或者更常见的是通过共享write buffer,但每个条目都由线程id进行标记,只有id匹配时才可以bypass。
测验问题4:在一个有多线程核心的TSO系统中,线程可以绕过write buffer的值,而不用管是哪个线程写入的值。
答:错误。一个线程可以bypass自己写入的数据,但是直到store请求被添加到内存顺序时才会被其他线程观测到。
实现原子指令
TSO中的原子RMW指令和SC的很相似,最关键的区别就是TSO允许load的bypass,且store可能被放入write buffer中。为了理解原子RMW的实现,我们认为RMW是load之后马上接着一个store。按照TSO的顺序规则,load不能bypass更早的load。我们可能会认为load可以bypass更早的store,但其实不行,因为RMW指令中load和store需要原子完成,那么store也需要bypass更早的store,但是这在TSO中是不允许的,因此对原子RMW来说load也不能bypass更早的store。
因此,从实现角度来看,原子RMW需要在之前的store退出write buffer之后才可以执行。同时,为了确保load之后可以马上store,load时需要将缓存一致性状态更新为读写状态(如M状态),而不是一般的只读状态(如S状态)。最后,为了保证原子性,在load和store之间不能更新缓存一致性状态。
我们也可以实现更激进的优化,比如说,如果实现了(a)write buffer中的每个请求都在缓存中有读写权限(如处于M状态),并且在RMW提交之前保持读写权限,或者(b)像MIPS R10000一样进行推测性load检查,就不需要在执行RMW前先清空write buffer(此处以及下文中的清空都是指完成write buffer中的所有请求,而非直接清空)。
实现FENCE
我们可以通过添加FENCE指令来保证store-load的顺序。由于TSO只允许store-load的重排,因此需要使用FENCE的场合不多,FENCE的实现方式也不是很重要。一种简单的实现是,当FENCE被执行时,清空write buffer,并在FENCE提交之前不再执行后面的load指令。
比较SC与TSO
我们可以发现,从执行和实现的角度来说,SC都是TSO的一个子集。更一般来说,如果所有符合X模型的执行顺序也符合Y模型的执行顺序,那么Y模型比X模型更宽松(更弱),或者X模型比Y模型更严格。不过也有可能两个内存模型时不可比的,X模型允许Y模型中不允许的顺序,同时Y模型也允许一些X模型中不允许的顺序。
好的内存一致性模型是什么样的?
可编程性:一个好的模型应该使编写多线程程序相对比较容易,对大多数用户都是直观的。
性能:一个好的模型应该有助于在功耗、成本等约束条件下实现高性能,并提供广泛的设计选择。
可移植性:一个好的模型应该被广泛使用,或至少提供向后兼容的能力,或提供模型之间转换的能力。
精确性:一个好的模型应该是被精确定义的,通常用数学来进行定义。
SC和TSO怎么样?
可编程性:SC是最直观的,TSO相对来说也比较直观。
性能:对简单的处理器内核来说,TSO可以比SC有更好的性能,但也可以进行各种优化以缩小两者之间的差距。
可移植性:SC被广泛理解,TSO被广泛采用。
精确:我们已经给出了SC和TSO的精确定义。