共享内存行为的问题
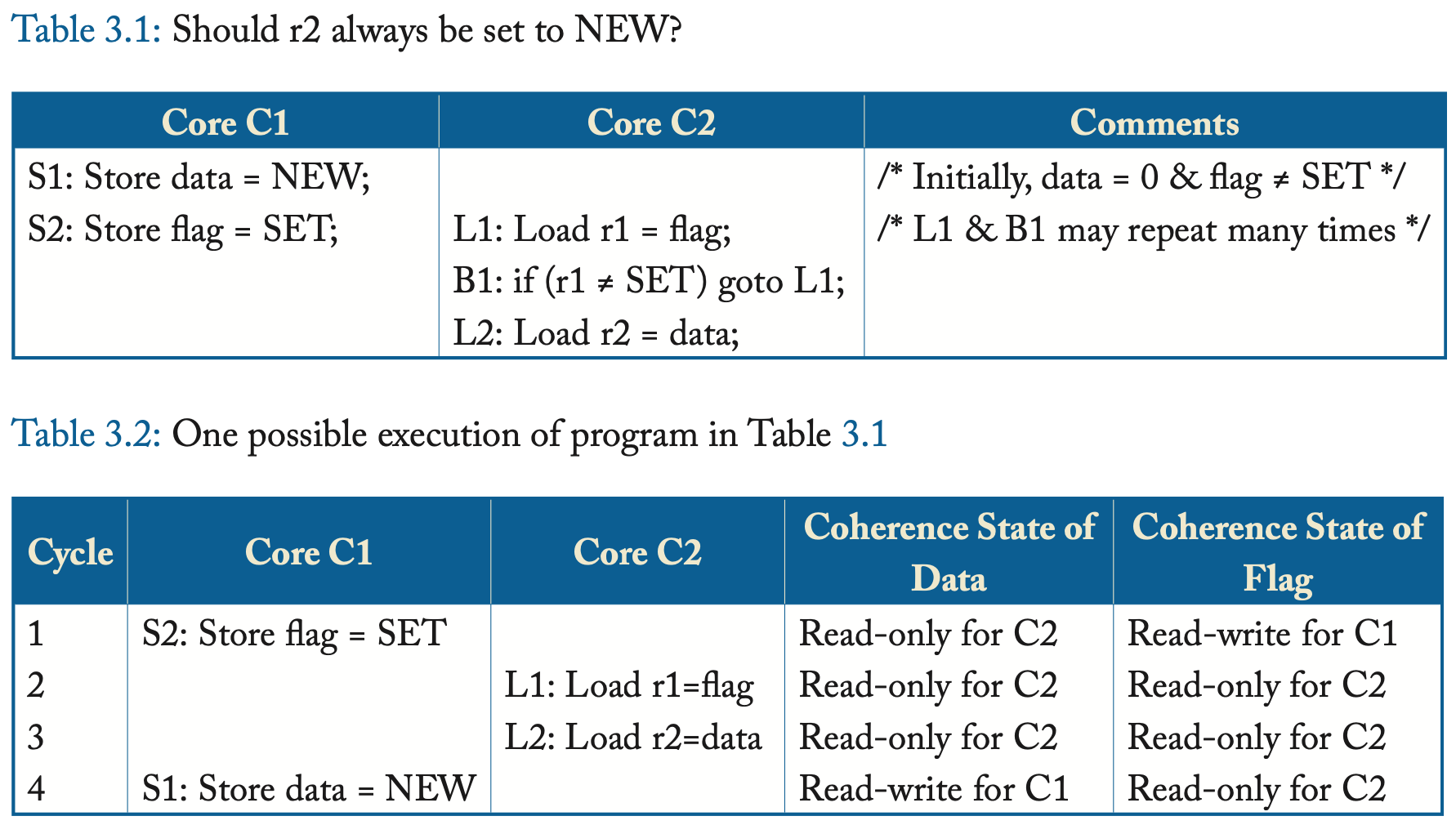 访问共享内存时的问题
访问共享内存时的问题
上面的例子很直观地说明了共享内存访问行为的问题,C1有可能先执行S2然后再执行S1。从硬件的视角来看,处理器有以下三种方式对内存访问进行重新排序:
Store-store重排:也就是上面的例子中出现的情况。
Load-load重排:这种重排似乎是安全的,但其实在上面的例子中,重排C2的load顺序和重排C1的store顺序其实导致的结果是一样的。
Load-store与store-load重排:这种重排可能会导致很多出乎意料的行为,如下图所示。
 r1和r2可以同时是0吗?
r1和r2可以同时是0吗?
顺序一致性的基本概念
顺序一致性(sequential consistency,SC)是最直观的内存一致性模型,具体来说就是顺序一致性表示执行的结果与操作按照程序规定的顺序执行是一样的,也就是说从单个处理器的视角来看,内存访问的顺序和程序顺序是一致的。
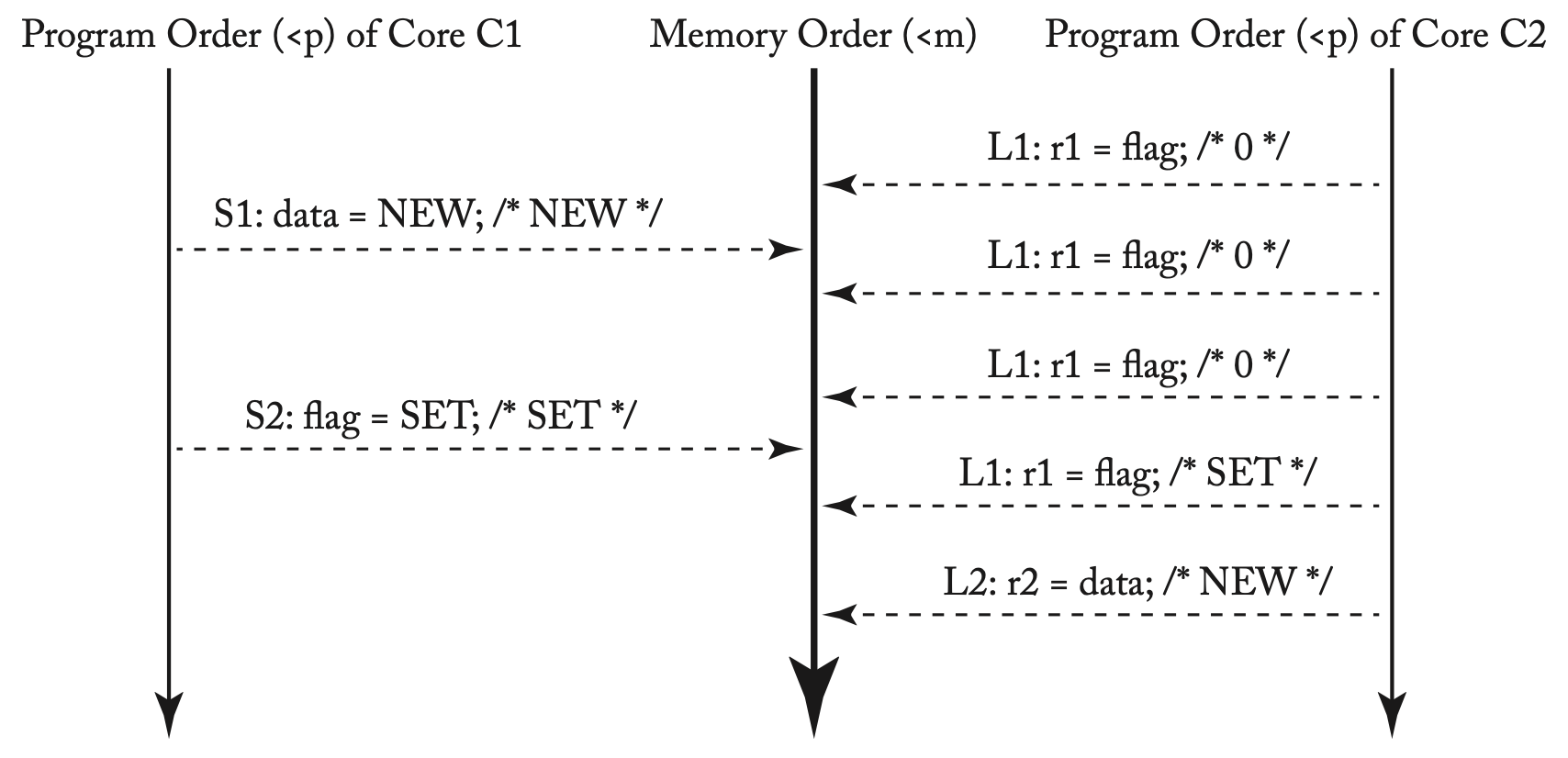 Table 3.1中的例子在SC模型下的执行顺序
Table 3.1中的例子在SC模型下的执行顺序
我们用<m表示内存顺序,<p表示程序顺序,如op1 <m op2表示内存顺序中op1出现在op2之前,op1 <p op2表示=程序顺序中op1出现在op2之前。在SC中,op1 <p op2可以推出op1 <m op2。下图进一步说明了上面例子的执行情况。
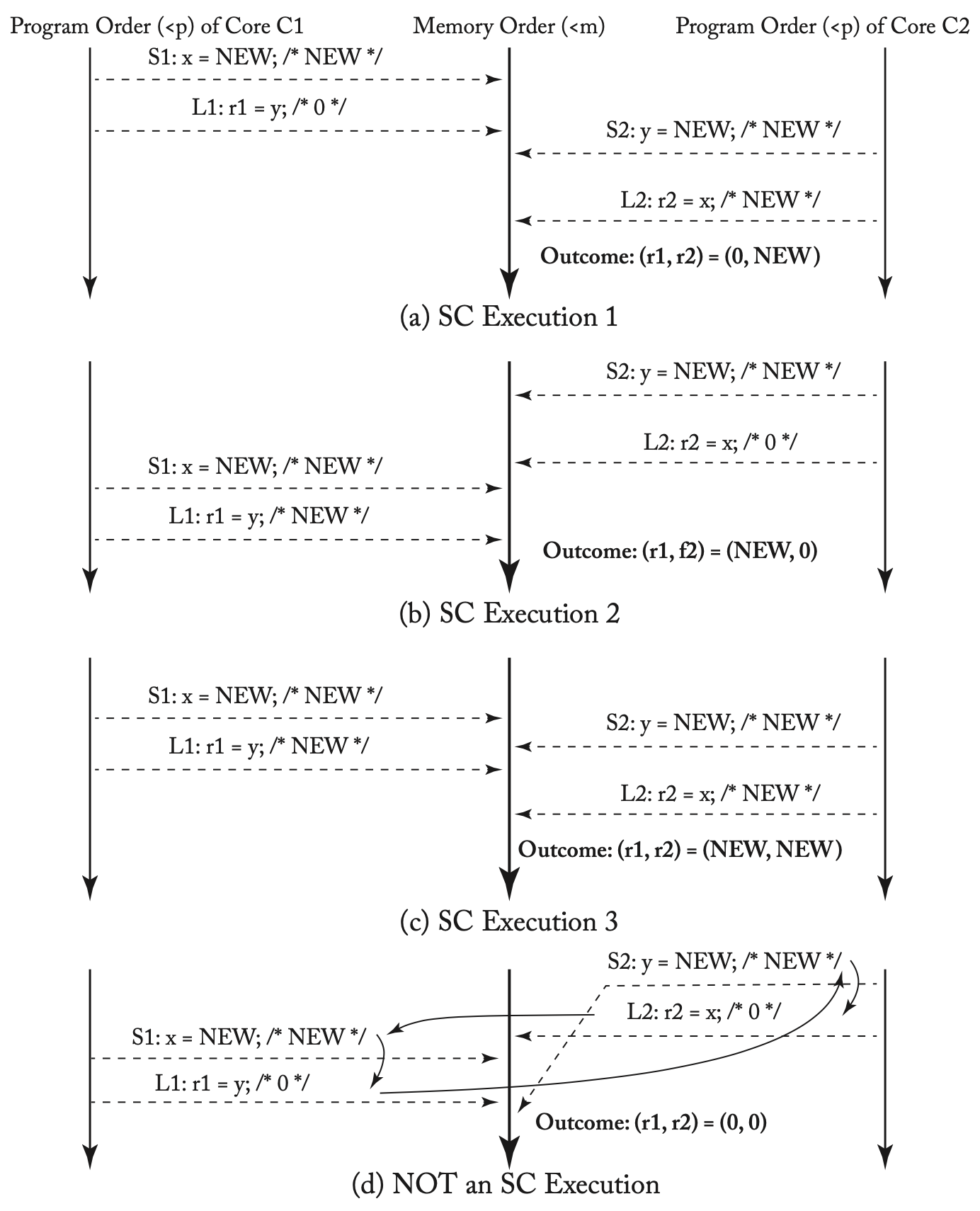 上述例子中4种不同的执行情况
上述例子中4种不同的执行情况
形式语言的定义
我们尝试用形式语言来更精确地定义SC。L(a)和S(a)分别代表对地址a的load和store,<p和<m分别表示程序顺序和内存顺序,且程序顺序是对于单个处理器核的,而内存顺序是全局的。
一次SC的执行需要满足以下条件:
所有的核按照程序顺序来把load和store指令插入
<m顺序,且顺序与内存地址无关,可能有以下四种情况:若
L(a) <p L(b),则L(a) <m L(b)若
L(a) <p S(b),则L(a) <m S(b)若
S(a) <p S(b),则S(a) <m S(b)若
S(a) <p L(b),则S(a) <m L(b)
每一次load都会从之前最后一次相同地址的store中获取值,即
L(a)的值为MAX_<m {S(a) | S(a) <m L(a)},其中MAX_<m表示内存顺序中最后出现的那一项。
原子RMW(read-modify-write)指令会在之后深入讨论,这种指令进一步限制了可能的执行情况。我们在下图中总结了SC的排序要求,这张表规定了哪些程序顺序是由一致性模型强制执行的。
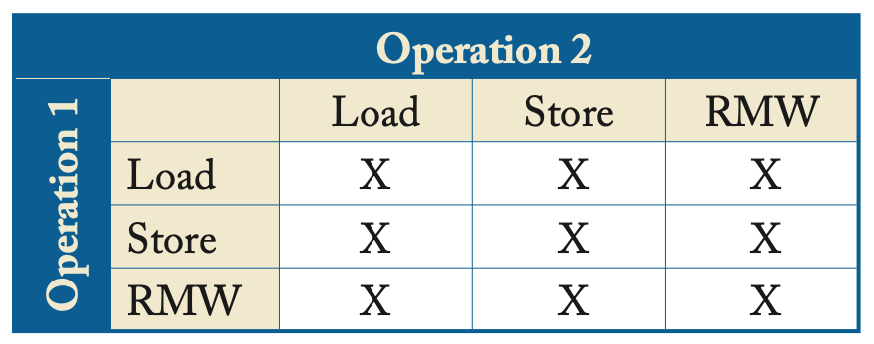 SC顺序规则
SC顺序规则
一个SC的实现只允许SC的执行,这是SC实现的“安全”属性,同时SC的实现还应该有一定的“有效性”,例如应该保证让程序可以往下执行,而不会卡在一个地方。
简单的SC实现
SC有两种简单的实现方式,可以让我们更好的理解这种内存模型。
多任务单核处理器:在单个顺序核上执行所有线程来实现多线程的切换。线程T1执行一段时间后,进行上下文切换,开始执行T2,上下文切换时必须保证完成所有之前的内存访问指令,因此保证了所有SC的规则。
Switch:如下图所示,每个核按程序顺序向switch提交内存操作,switch负责接收内存请求并访问内存。
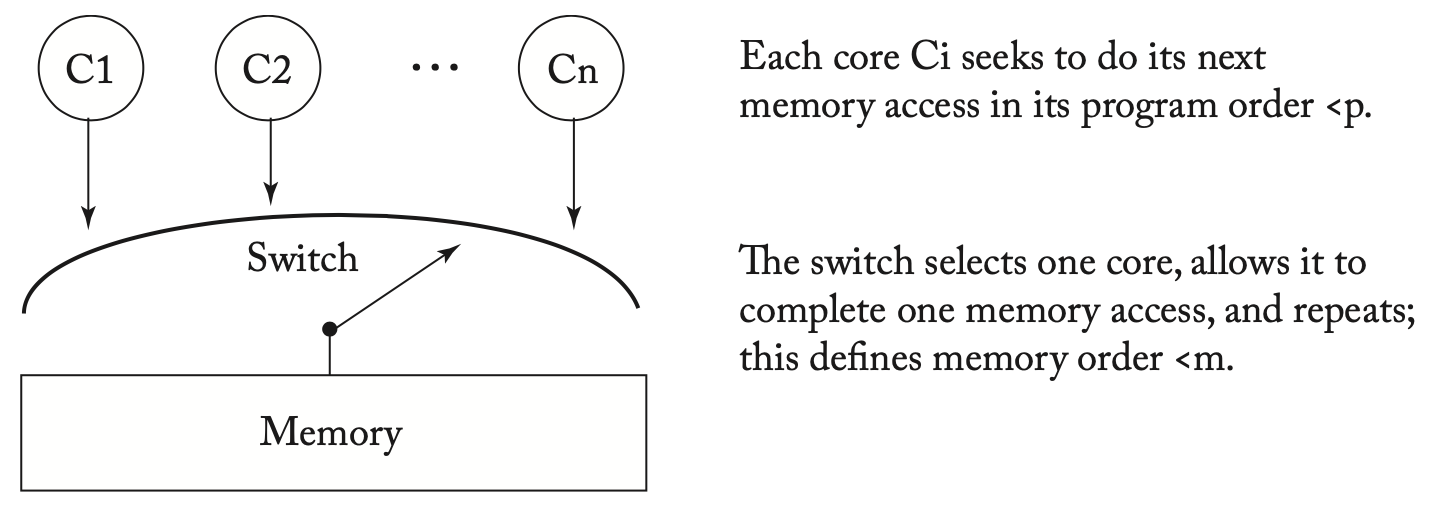 使用switch的简单SC实现
使用switch的简单SC实现
这两种实现证明了SC的可行性,但其实这样实现的性能并没有随着核数的增加而提升,性能瓶颈导致一些人错误地得出结论:SC并没有达到真正的并行执行,但其实不然,我们接下来就会看到这一点。
有缓存一致性的基本SC实现
缓存一致性有利于SC的实现,可以完全并行地执行不冲突的加载和存储。冲突的定义是,两个操作访问同一个地址,并且其中至少有一个是store。
我们实现下面的简单缓存一致性:
使用状态modified (M)来表示一个核可以写入和读取的L1块。
使用状态shared (S)来表示一个或多个核只能读取的L1块。
GetM和GetS分别表示获取M和S中块的一致性请求。
我们之前一直把缓存一致性当作黑盒,现在我们稍微打开内存系统的黑盒,每个核都连接到自己的L1缓存,根据内存访问指令来更新自己的缓存状态,如下图所示。
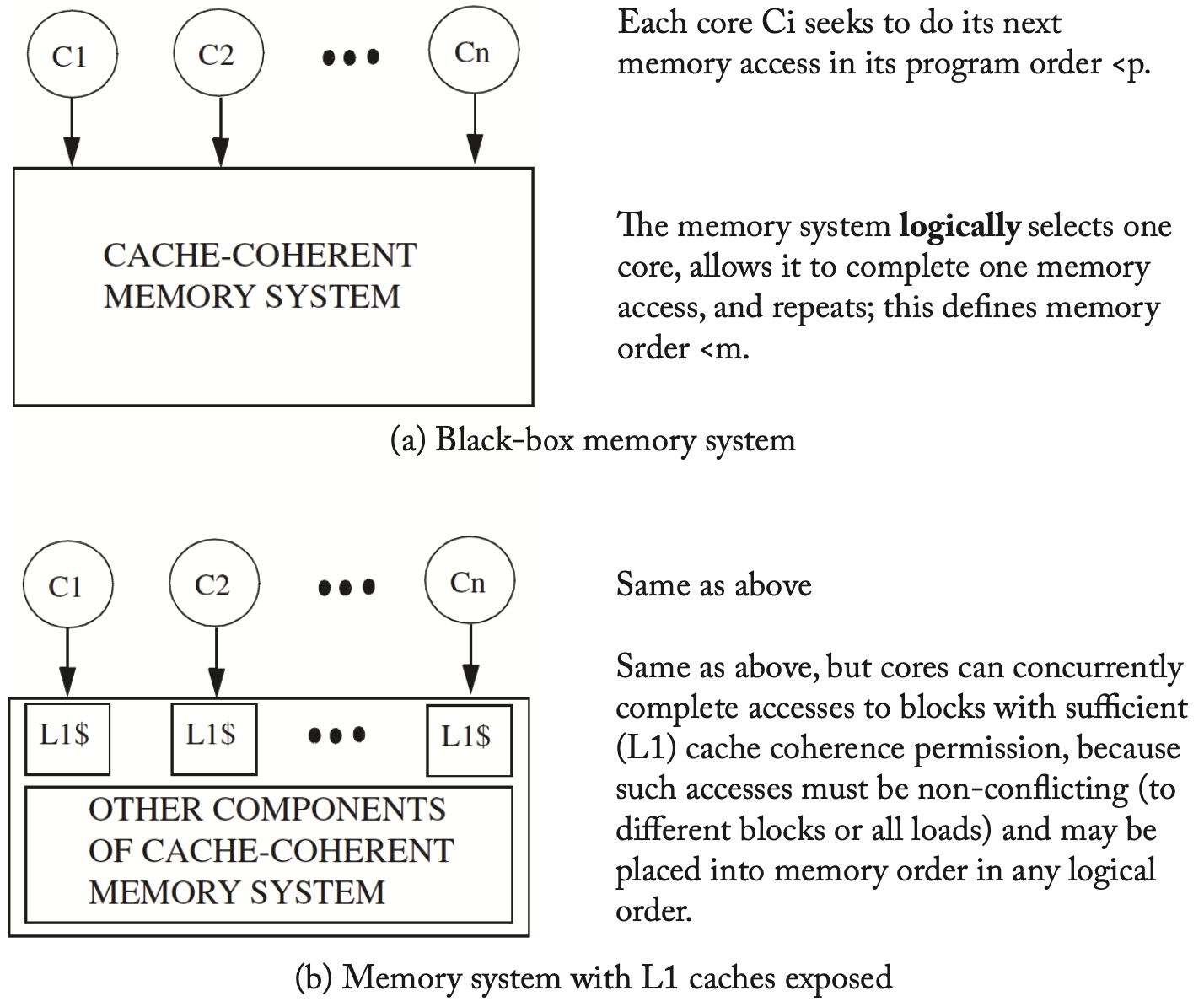 用缓存一致性实现SC
用缓存一致性实现SC
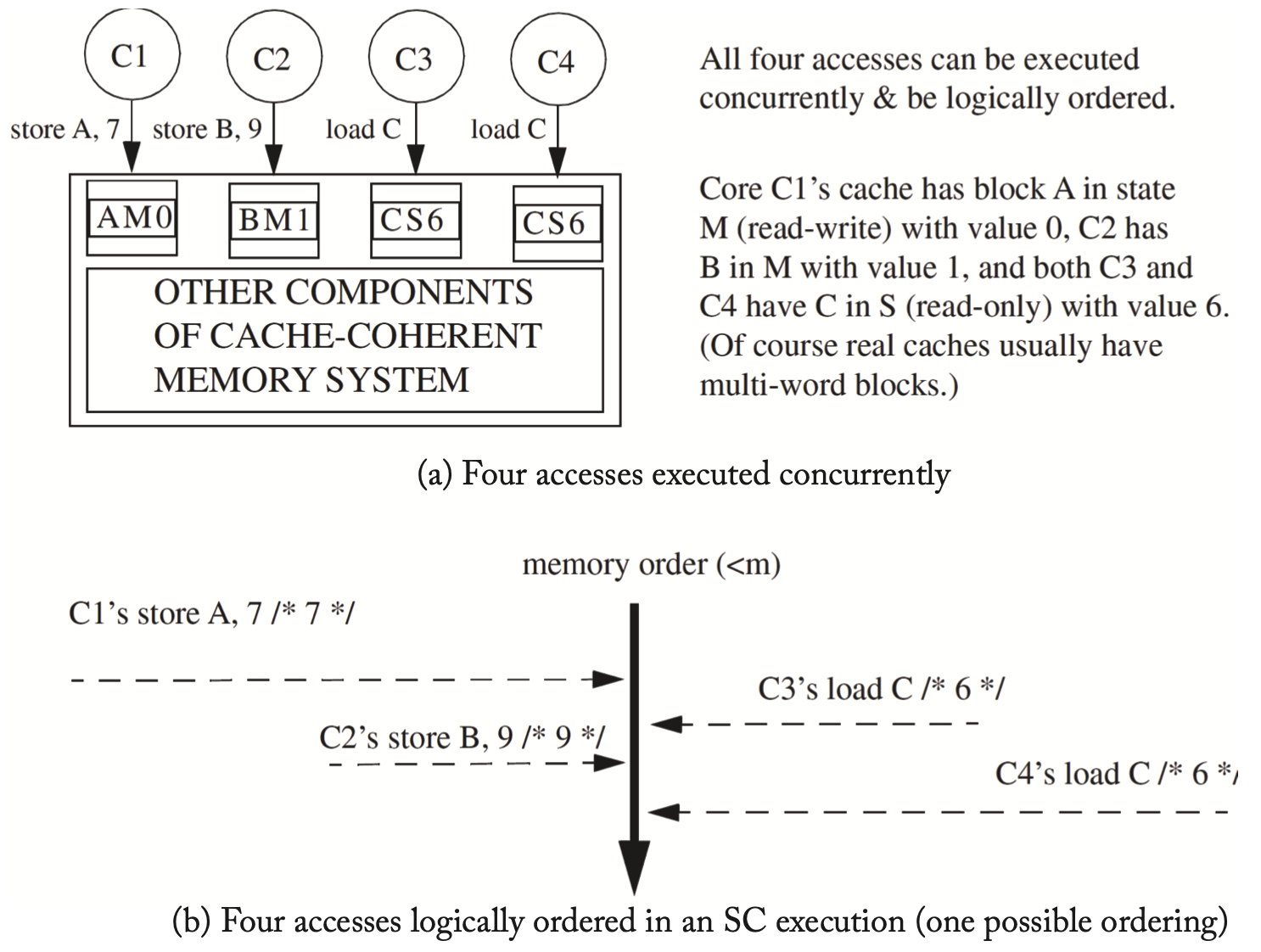 实现缓存一致性情况下的SC并发执行
实现缓存一致性情况下的SC并发执行
有缓存一致性的优化SC实现
大多数实际的内核实现都比我们的基本SC实现要复杂得多,且同时实现了缓存一致性。通常会采用预取、推测执行和多线程等技术以提高性能,优化内存访问延迟,我们现在讨论这些技术如何影响SC的实现。需要注意的是,只要不违反SC的最终结果,我们就可以进行任何形式的优化。
非绑定预取
对区块B的非绑定预取是对一致性内存系统的请求,以改变B在一个或多个cache中的一致性状态,这个请求通常可以是由软件、处理器核或者cache发出的,通过GetS或GetM等请求以允许M或S状态下的load以及M状态下的load或store。需要注意的是,非绑定预取仅限在缓存中进行,也就是说内存一致性仍然是可以保证的。
推测执行
load和store指令可能位于错误的分支预测路径上,这些load和store可以仿照非绑定预取的方式来执行,因而不会对SC的正确性产生影响。对于load指令来说,如果不成功,只会导致非绑定的GetS预取,而不会影响寄存器的状态,如果成功,就返回load的值到寄存器。对于store指令也是类似的,可能提前发出一个非绑定的GetM预取,但是在指令提交之前,不会更新缓存中的内容。
测验问题1:在一个保持顺序一致性的系统中,一个核心必须按程序顺序发出一致性请求。
答:错误,因为一个处理器核可能按照任意顺序发出缓存一致性请求。
动态调度
处理器核可以动态调度指令以实现乱序执行,实现更高的性能。在多核处理器的背景下,这可能导致内存一致性的问题。考虑两条load指令L1和L2,处理器核可能会在L1之前推测性地执行L2,尽管这种重排对其他内核是不可见的,但仍然违反了SC。有两种技术来检查这种情况。
第一种方法是在推测性地执行L2、但是提交L2之前,处理器检查推测访问的缓存块是否已经离开了缓存。只要缓存块仍然在缓存中,值就不会变化。为了执行这个检查,处理器跟踪L2 load的地址,并将evict的缓存块和传入的一致性请求进行对比,一个传入的GetM表明另一个处理器可以观察到L2的miss,而这个GetM表明推测性的load执行错误,需要冲刷推测路径。
第二种方法是在处理器准备提交load指令时replay每个推测性的load。如果提交时load的值不等于之前推测load的值,那么预测就不正确。
动态调度内核中的非绑定预取
一个动态调度的内核可能会遇到不按程序顺序load和store的情况,如程序顺序是load A,store B,store C,但可能不按照这个顺序进行非绑定预取,如GetM C,然后并行执行GetS A和GetM B,但这不会影响SC,SC只要求一个处理器的load和store从外界看上去按照程序顺序访问其L1缓存。简而言之,SC(或其他任何内存一致性模型)决定了load和store真正提交的顺序,但不决定缓存一致性活动的顺序。
测验问题2:内存一致性模型规定了缓存一致性请求的合法顺序。
答:错误。
SC内存模型下的原子操作
在微架构中实现原子指令本身不难,但是过于简化的设计可能会导致性能不佳,例如实现原子指令的一个正确但简单的方法是让处理器锁定内存系统(即防止其他内核发出内存访问)并对内存进行读取、修改和写入操作。这种实现虽然正确而直观,但却牺牲了性能。
更激进的实现是利用了SC可以保证所有请求按顺序发出。因此,一个原子RMW操作可以通过让一个核心在缓存中获得M状态的缓存块来实现,然后在缓存中进行load和store,不需要任何一致性消息或者总线锁定,只需要在此过程中阻塞其他处理器传来的一致性请求,并在store真正完成之后再响应其他处理器即可,这个过程不会有死锁的风险。
测验问题3:为了执行一个原子的read-modify-write(如test-and-set),一个核必须始终与其他核进行通信。
答:错误。
一个更加优化的实现可以在不违反原子性的情况下,允许在load和store之间有更多的时间。考虑这样的情况,一个缓存块当前处于S状态,RMW的load可以立即进行推测执行,与此同时缓存控制器发出一致性请求,将块的状态更新为M状态,更新完成后就可以执行store。这个过程不一定能保证原子性,因此为了检查原子性,处理器核必须检查load的缓存块是否在load和store之间从缓存中被evict,类似于前一节中检测错误的推测性load指令的过程。
案例研究:MIPS R10000
在执行过程中,处理器核按程序顺序向地址队列发出(推测性)load和store。load从上一个相同地址的store指令中获得推测性的值,如果没有,则从数据缓存中获得值。load和store按程序顺序提交,然后删除其地址队列条目。提交store时,缓存块必须在M状态下,并且缓存块与ROB必须被原子地更新。
重要的是,如果发生了缓存块eviction(可能是由于一致性请求或者仅仅是为其他的数据腾出空间),且evict的缓存块地址对应了地址队列中的某个load请求,那么这个load请求和后面所有的指令都要被冲刷,并重新执行。因此,当load最终提交时,load的缓存块在执行和提交之间一直在缓存中,因此这个期间load的值不会被改变。由于store在提交时实际写入缓存,R10000在逻辑上将load和store按程序顺序提交给内存系统,从而实现了SC。