基于kernel的编程一开始是作为访问GPU的一种方式而流行的,但也慢慢普及到其他类型的加速器上,包括FPGA。为了更好地利用FPGA进行加速,我们需要回答一些问题,如我们应该什么时候使用FPGA、程序的哪些部分可以用FPGA加速、以及应该如何编写FPGA可以运行的高性能代码。在SYCL标准之上,DPC++额外支持FPGA选择器和管道(pipe)。
基本概念
对于传统的基于ISA的处理器,芯片在每个时钟周期内执行程序的指令,硬件被不同的指令复用,如下图所示。
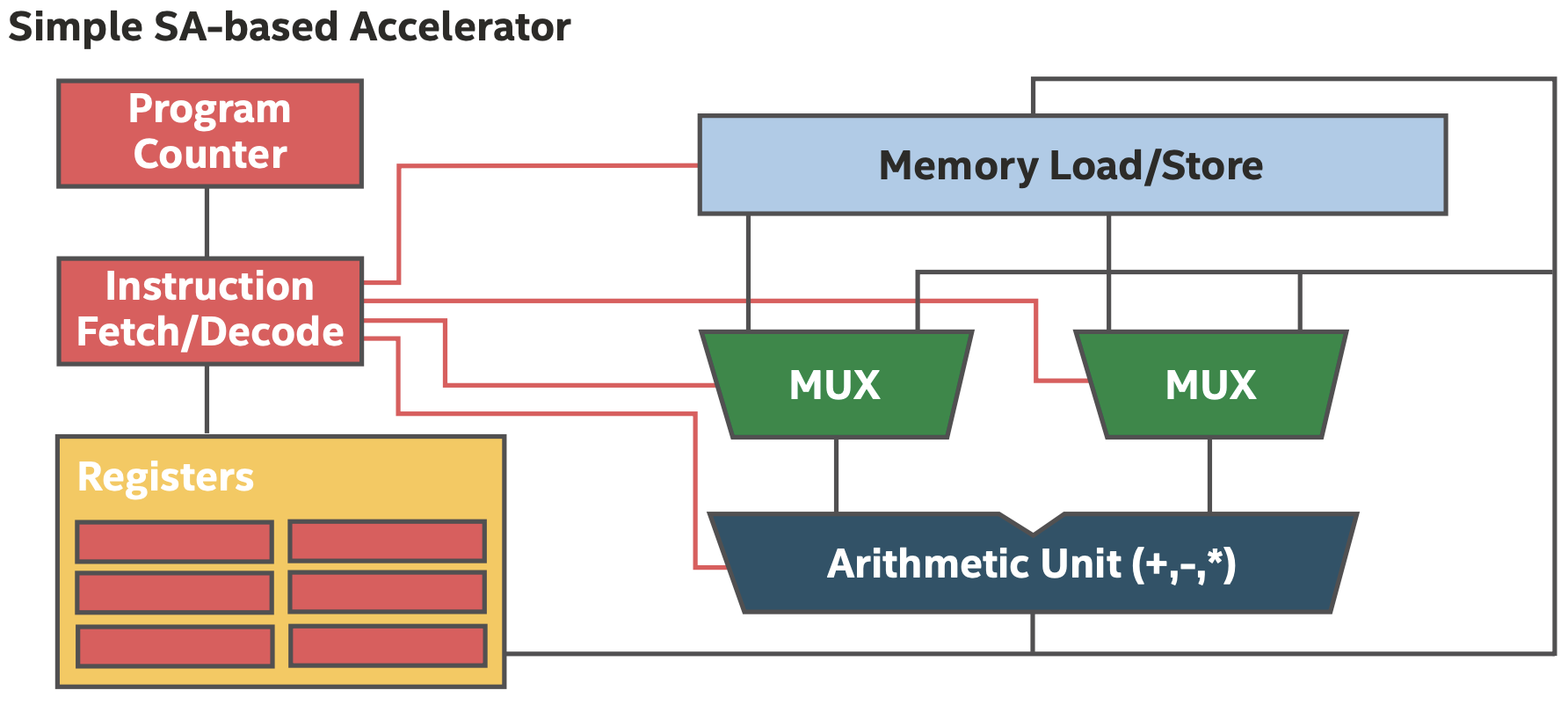 基于ISA的架构
基于ISA的架构
空间架构则不同,整个程序是一个整体,硬件的不同区域实现程序中的不同指令,每条指令都有自己的专用硬件,如下图所示。
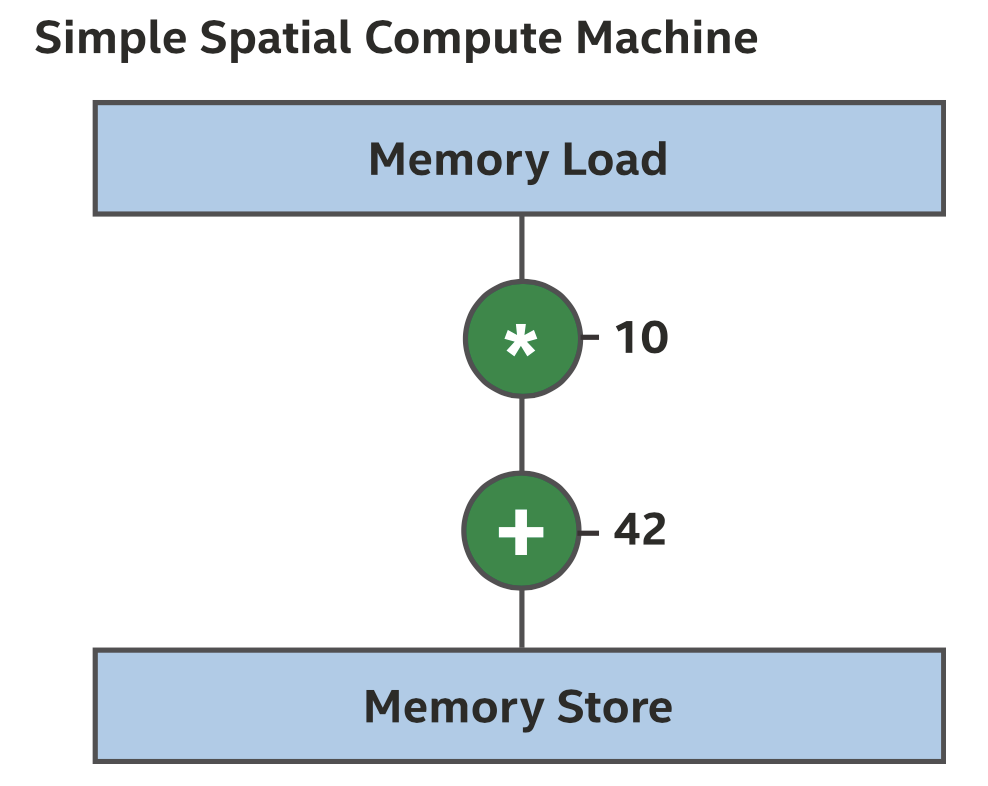 基于空间的架构
基于空间的架构
注意在这种结构中,我们不再需要取指、解码、程序计数器或寄存器堆,也不需要存储未来指令需要用到的数据,而是直接把一条指令的输出与下一条指令的输入连接起来,这也是为什么空间架构经常被称为数据流架构(dataflow architecture)。
流水线并行
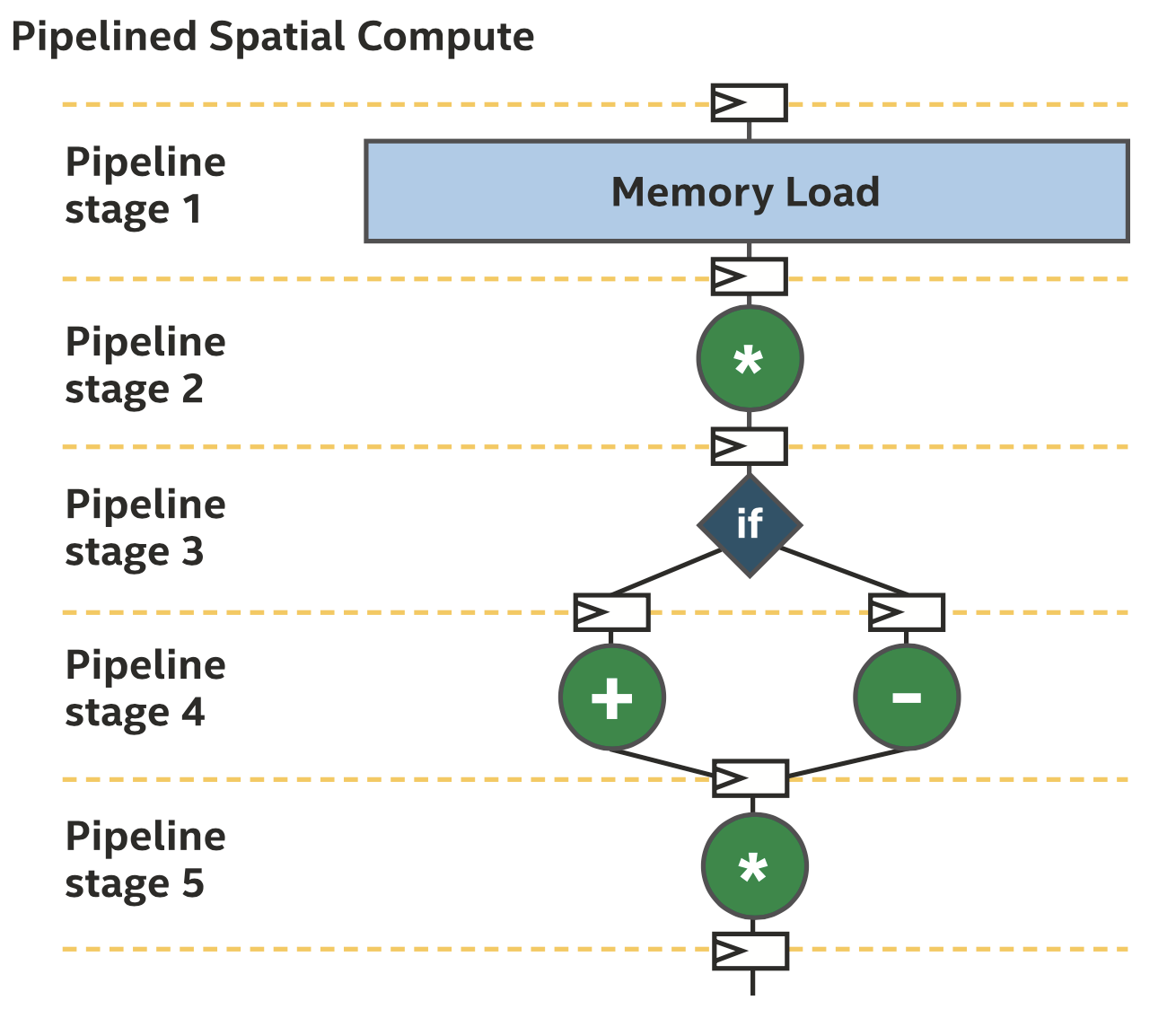
上面的图中经常出现的问题是程序的空间实现和时钟频率的关系,如果关键路径过长,不仅时钟频率低,而且大多数硬件只在一小部分时间内做有用的工作。大多数编译器可以通过流水线来解决这种问题,在一些操作之间插入寄存器,如下图所示。
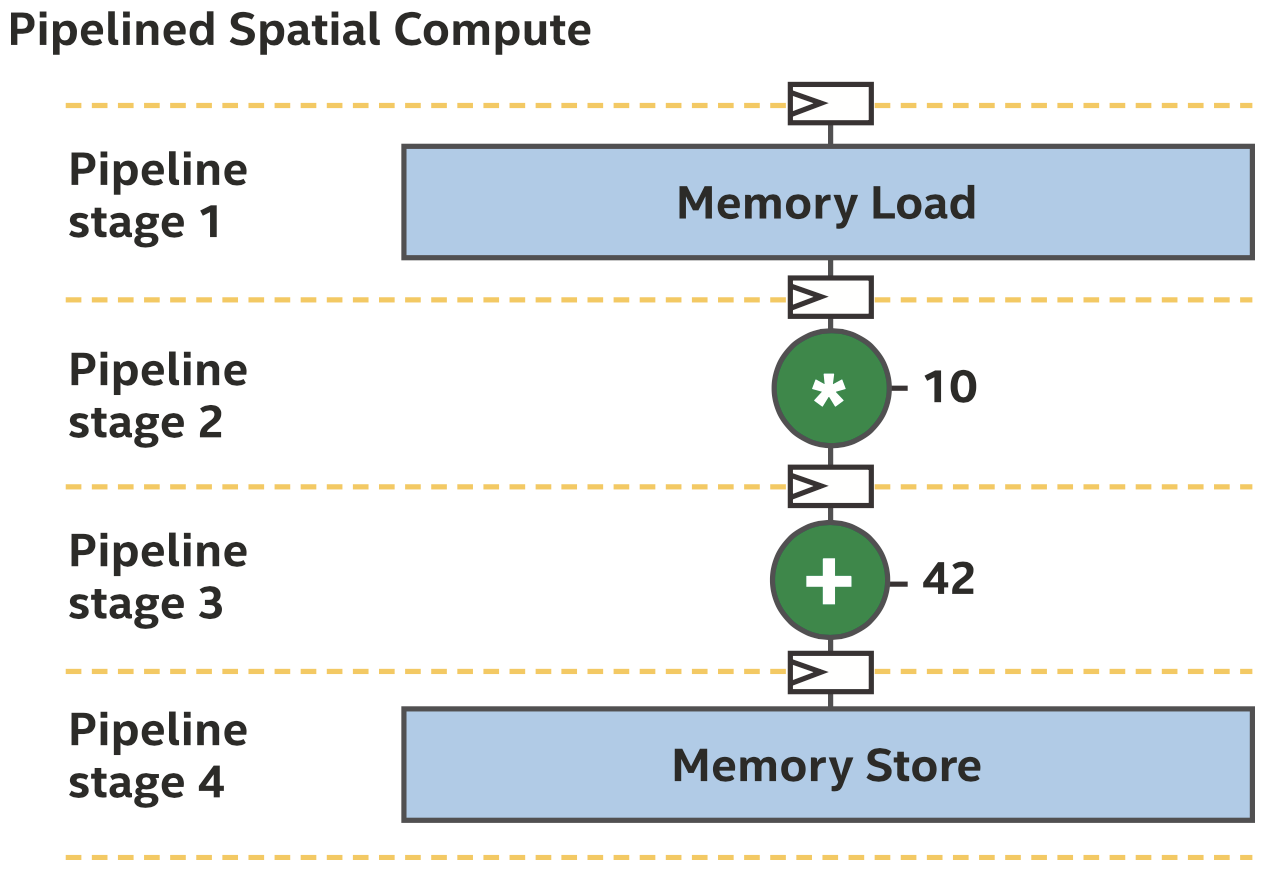 流水线化的计算
流水线化的计算
消耗面积的Kernel
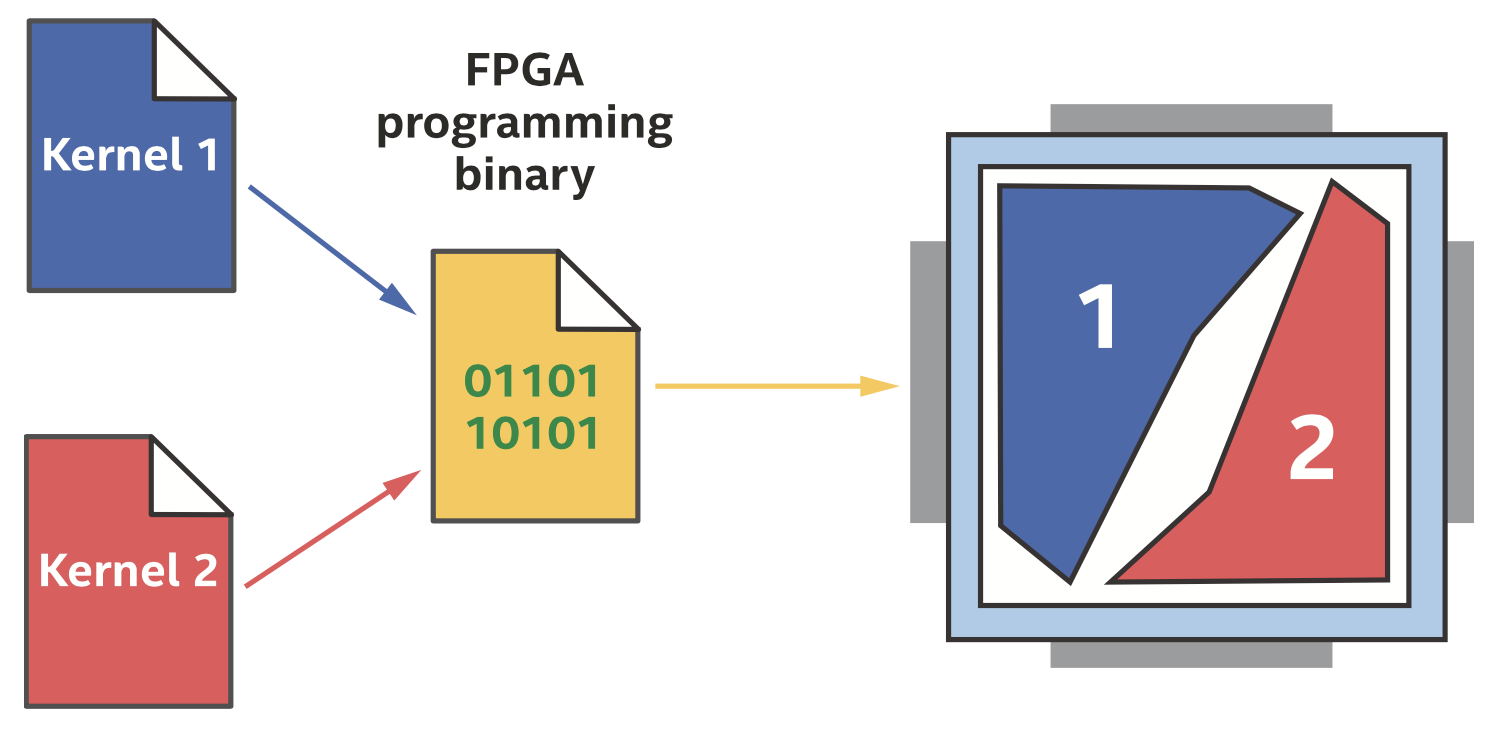 FPGA上的多个kernel
FPGA上的多个kernel
DPC++程序中的每个kernel都会生成流水线,消耗一部分FPGA资源,如上图所示。不同的kernel可以同时执行,如果一个kernel被阻塞(例如等待内存访问),其他kernel可以继续执行。
什么时候使用FPGA
大量工作可以利用FPGA流水线并行,可能流水线有数千级,我们把流水线级的平均利用率称为流水线占用率(occupancy),有多种方法可以在FPGA上尽可能往流水线中填充工作。
FPGA最初的设计是为了执行高效的整数和位运算,可以有效实现任意数据类型,比如定制化一个33位的整数乘法器等,很容易应用于机器学习等领域。
FPGA也提供了丰富的低延时接口,可以充分利用网络接口,而不经过操作系统,如下图所示。
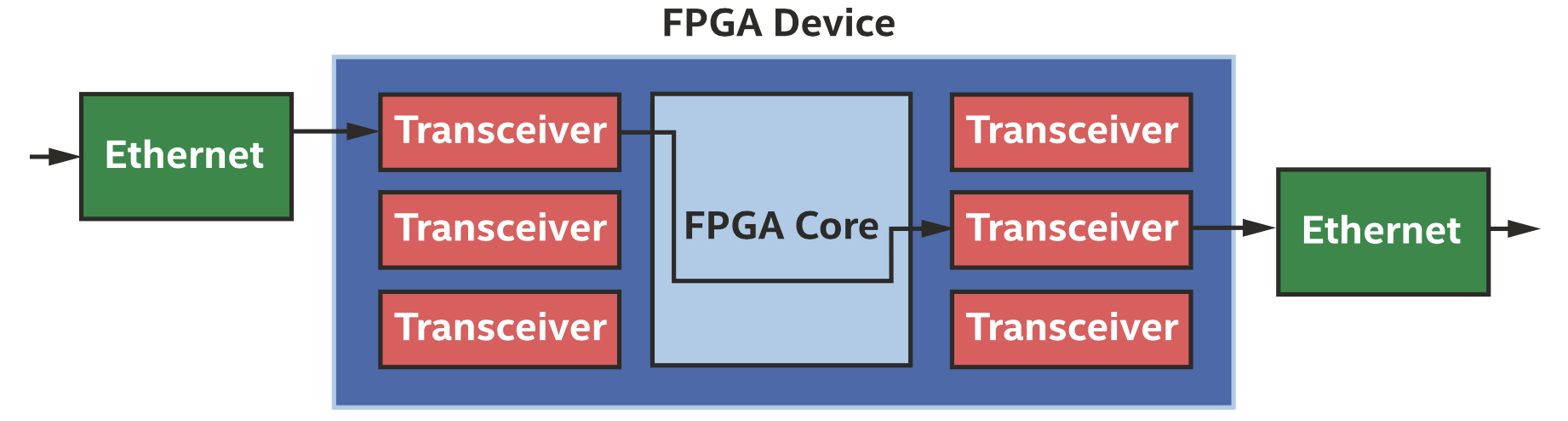 低延时IO串流
低延时IO串流
FPGA上的存储系统也是高度定制的,有小块的片上存储器,且带宽很大,编译器可以基于这一点进行优化,如下图所示。
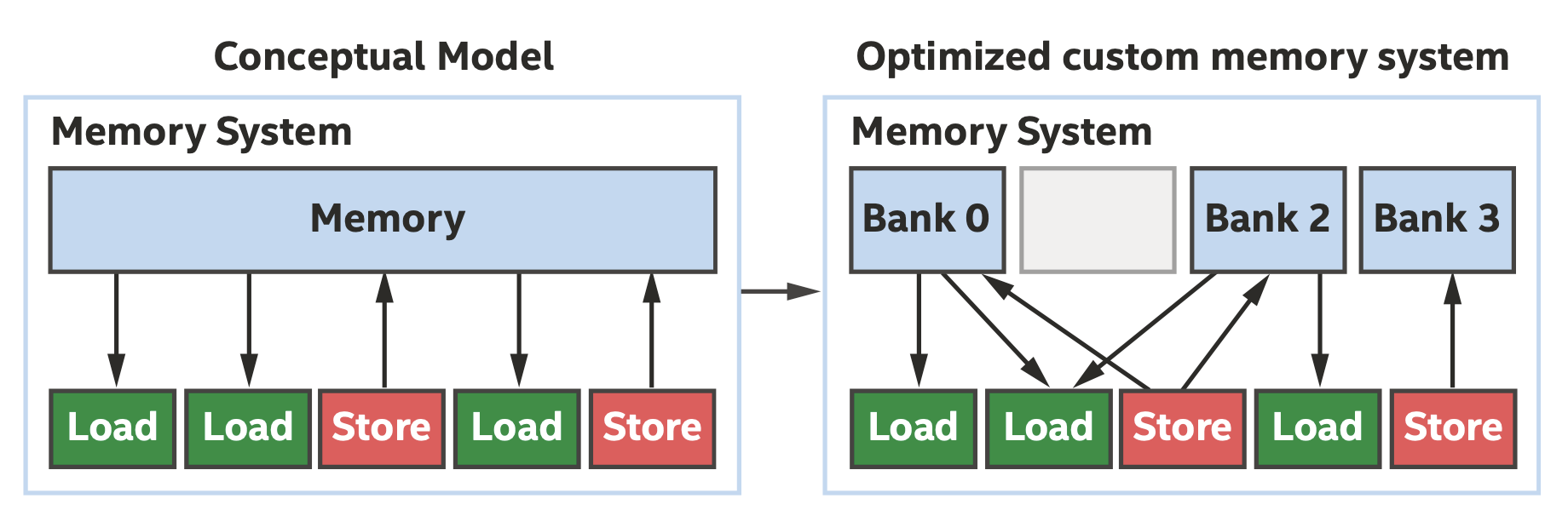 编译器基于FPGA定制的内存系统进行优化
编译器基于FPGA定制的内存系统进行优化
在FPGA上运行程序
在FPGA上运行kernel有两个步骤:
将源代码编译成二进制文件
在运行时选择需要的加速器
可以使用以下命令将kernel编译到FPGA硬件:
1
dpcpp -fintelfpga my_source_code.cpp -Xshardware
编译与运行时的流程如下图所示。
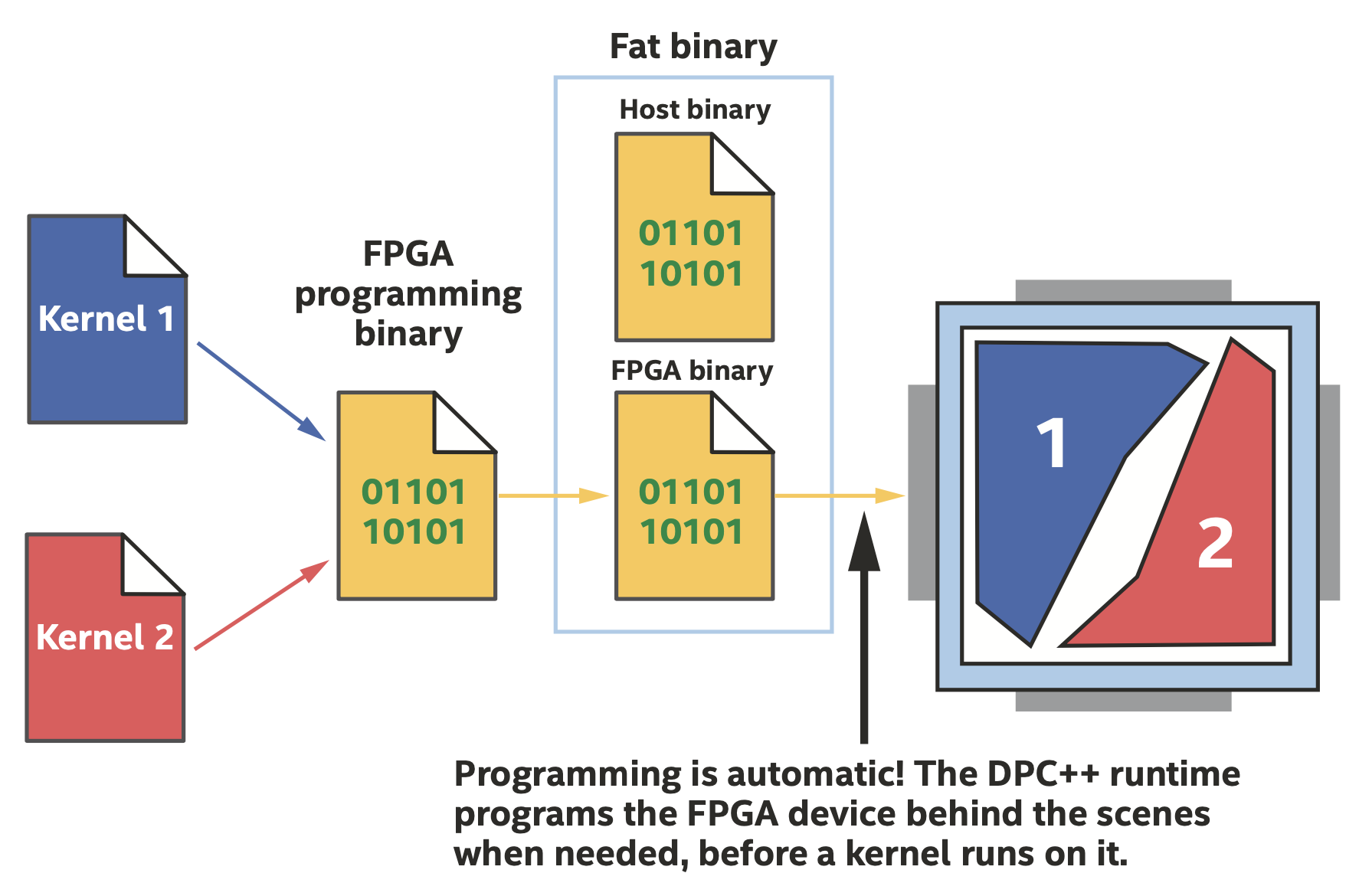 在运行时自动对FPGA编程
在运行时自动对FPGA编程
编译期
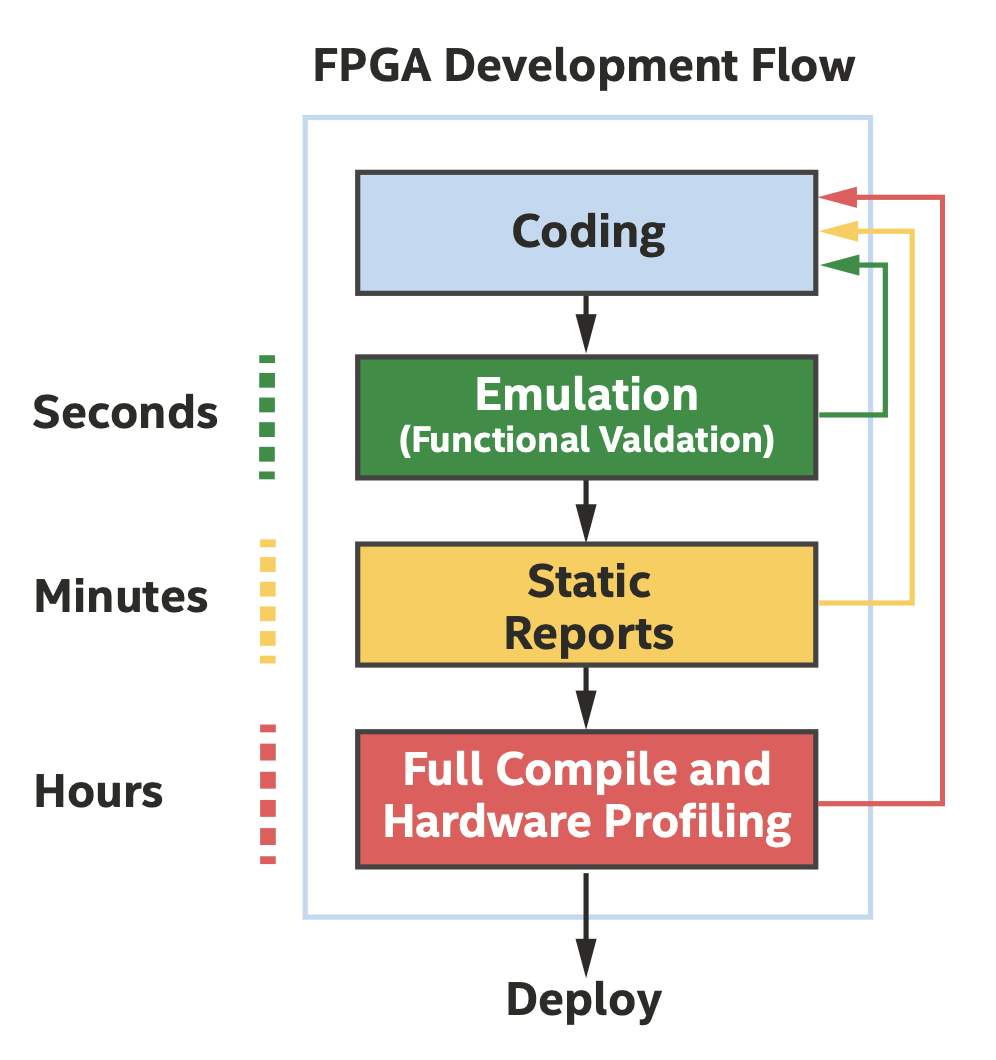 在冗长的硬件编译之前还有大多数验证和优化过程
在冗长的硬件编译之前还有大多数验证和优化过程
FPGA仿真器
在代码中使用INTEL::fpga_emulator_selector选择器,并使用以下命令编译:
1
dpcpp -fintelfpga my_source_code.cpp
FPGA硬件编译提前完成
上图中Full Compile和Hardware Profiling是SYCL术语中的提前编译(ahead-of-time compile),在编译阶段就把kernel编译为设备二进制文件,这是因为编译需要一定时间,且DPC++程序在部署的性能较弱的主机上同样可以执行。
为FPGA编写Kernel
利用FPGA并行性
 五级简单流水线,需要6个周期来处理一个元素的数据
五级简单流水线,需要6个周期来处理一个元素的数据
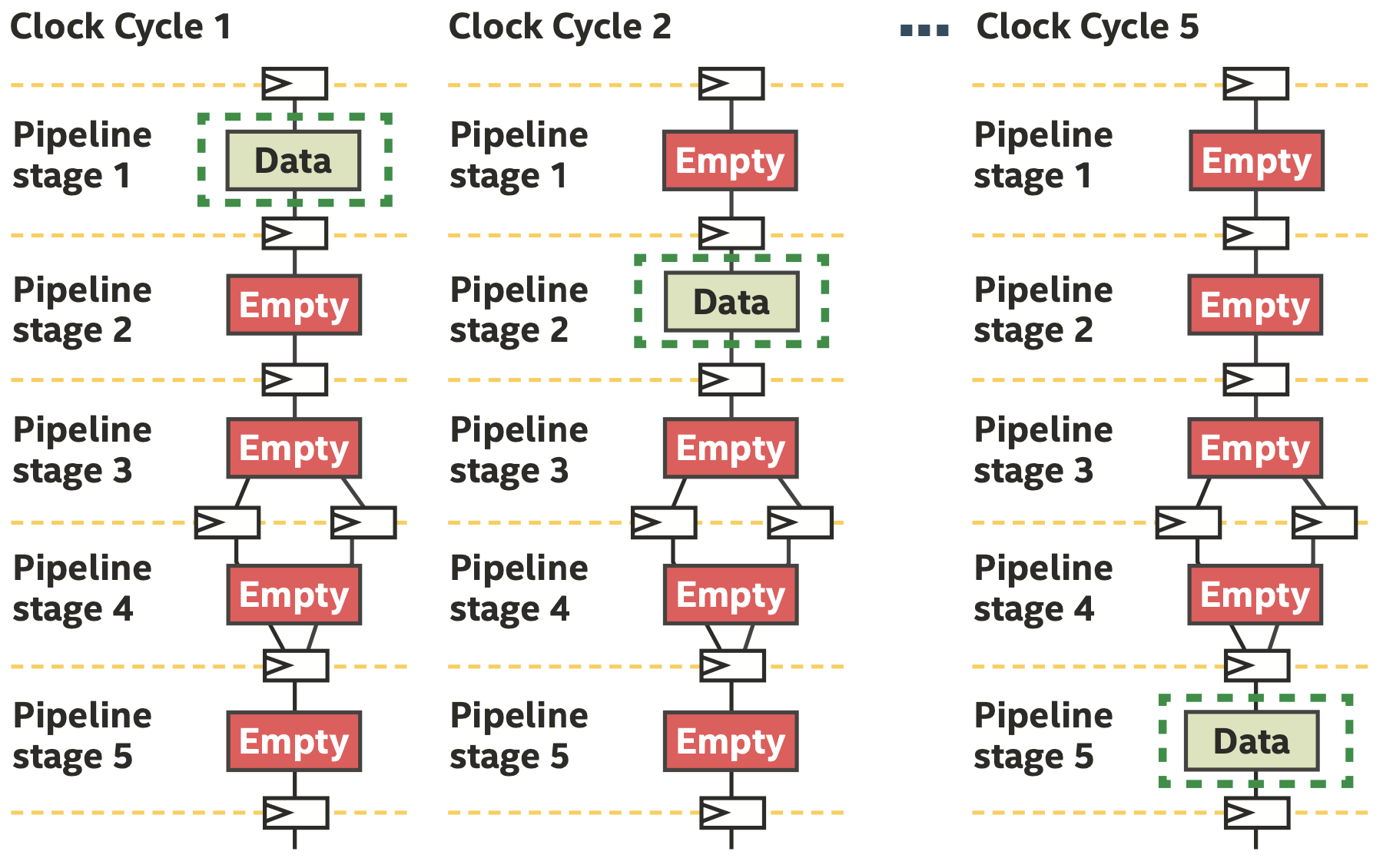 如果一次只处理一个元素,流水线大部分都是闲置的
如果一次只处理一个元素,流水线大部分都是闲置的
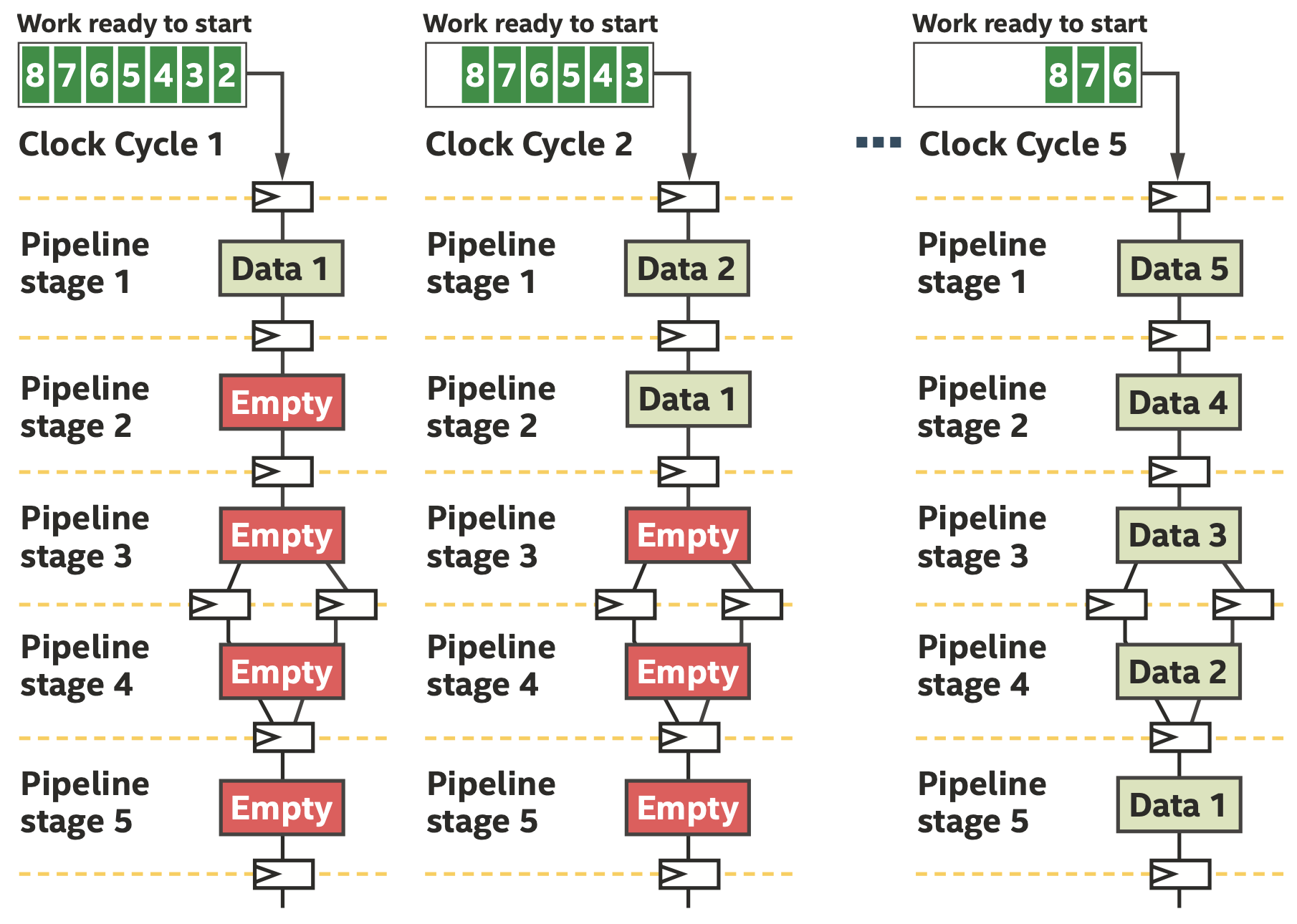 流水线被有效利用
流水线被有效利用
上面三张图很好地展示了如何高效利用FPGA流水线,我们接下来介绍如何充分利用流水线,主要研究ND-range kernel和循环。
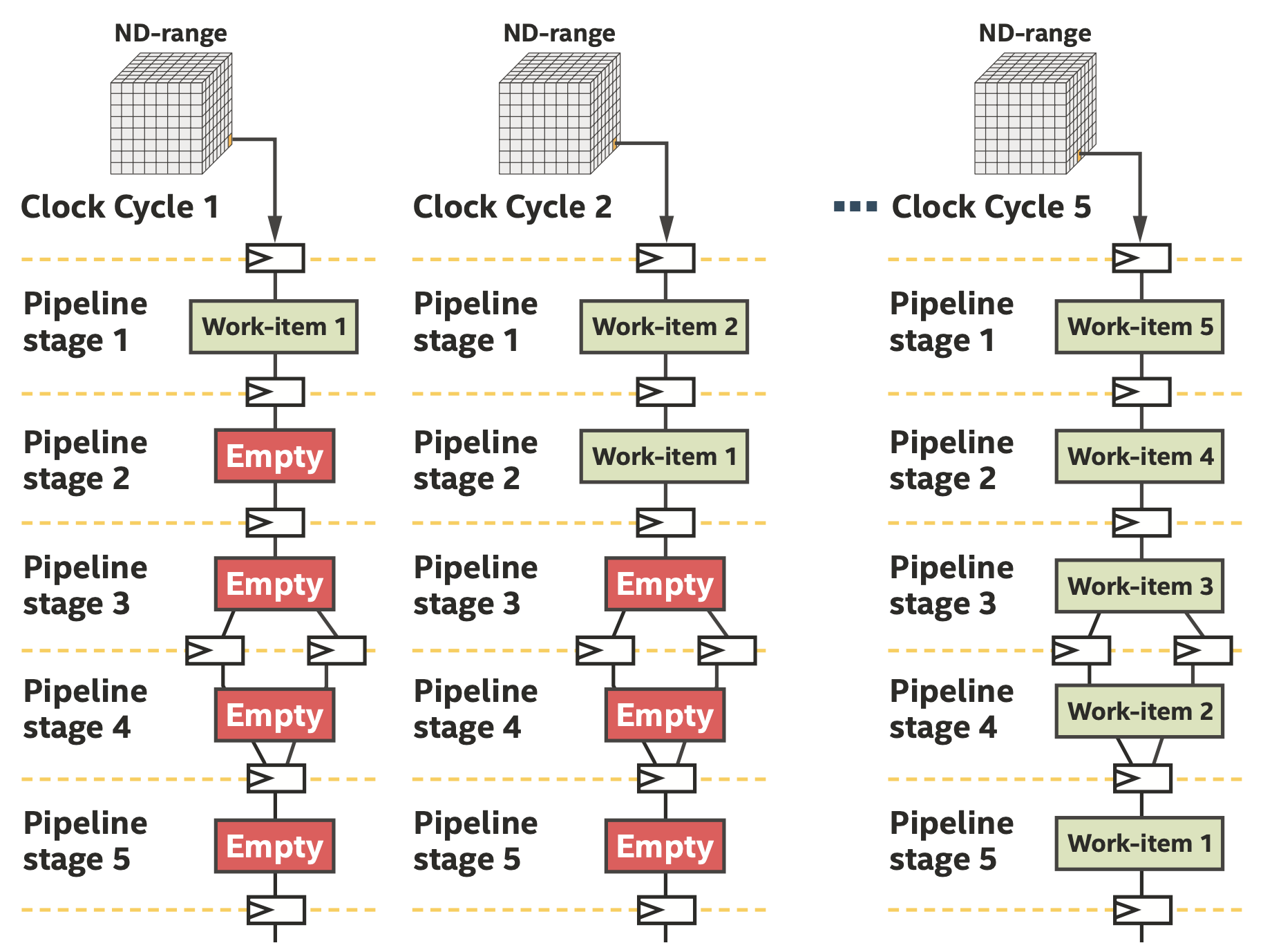 通过ND-range为流水线提供数据
通过ND-range为流水线提供数据
FPGA可以非常有效地使用ND-range来填充流水线,如上图所示,在每个时钟周期都有一个work-item进入流水线。只要我们可以将算法或程序结构化为独立的work-item,不需要经常通信或根本不需要通信,就可以使用ND-range。
FPGA流水线上也可以实现数据依赖,可以实现work-item之间的细粒度通信(甚至不同work-grouop的work-item也可以),比如下面的例子以及下图。
1
2
3
4
5
int state = 0;
for (int i = 0; i < size; i++) {
state = generate_random_number(state);
output[i] = state;
}
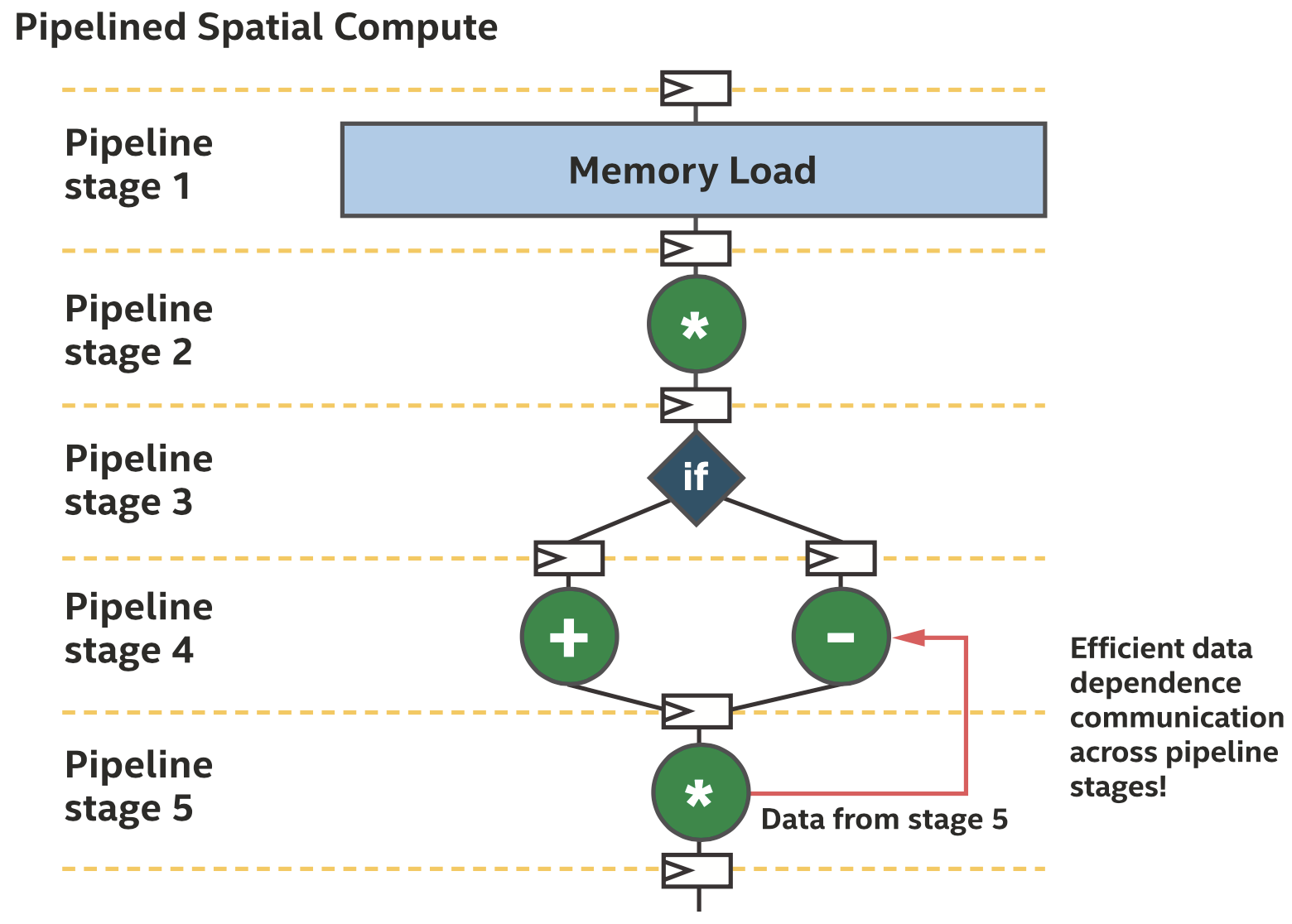 后向通信(传输数据到流水线的之前阶段)可以帮助实现有效的数据依赖通信
后向通信(传输数据到流水线的之前阶段)可以帮助实现有效的数据依赖通信
后向通信能力是空间架构的关键,但如何编写这样的代码并不显而易见,两种常见方法可以实现这一点,分别是循环和ND-range kernel的kernel内管道,我们在此暂时只讨论循环。在下面的例子中,不同循环间有数据依赖关系,注意这里使用single_task而非parallel_for,因为在代码中已经有循环了。
1
2
3
4
5
6
7
h.single_task([=]() {
int state = seed;
for (int i = 0; i < size; i++) {
state = generate_incremental_random_number(state);
output[i] = state;
}
});
从程序员的角度来说,每一次iteration应该是一个接一个执行的,但流水线化之后每一次iteration执行在时间上是重叠的,如下图所示。
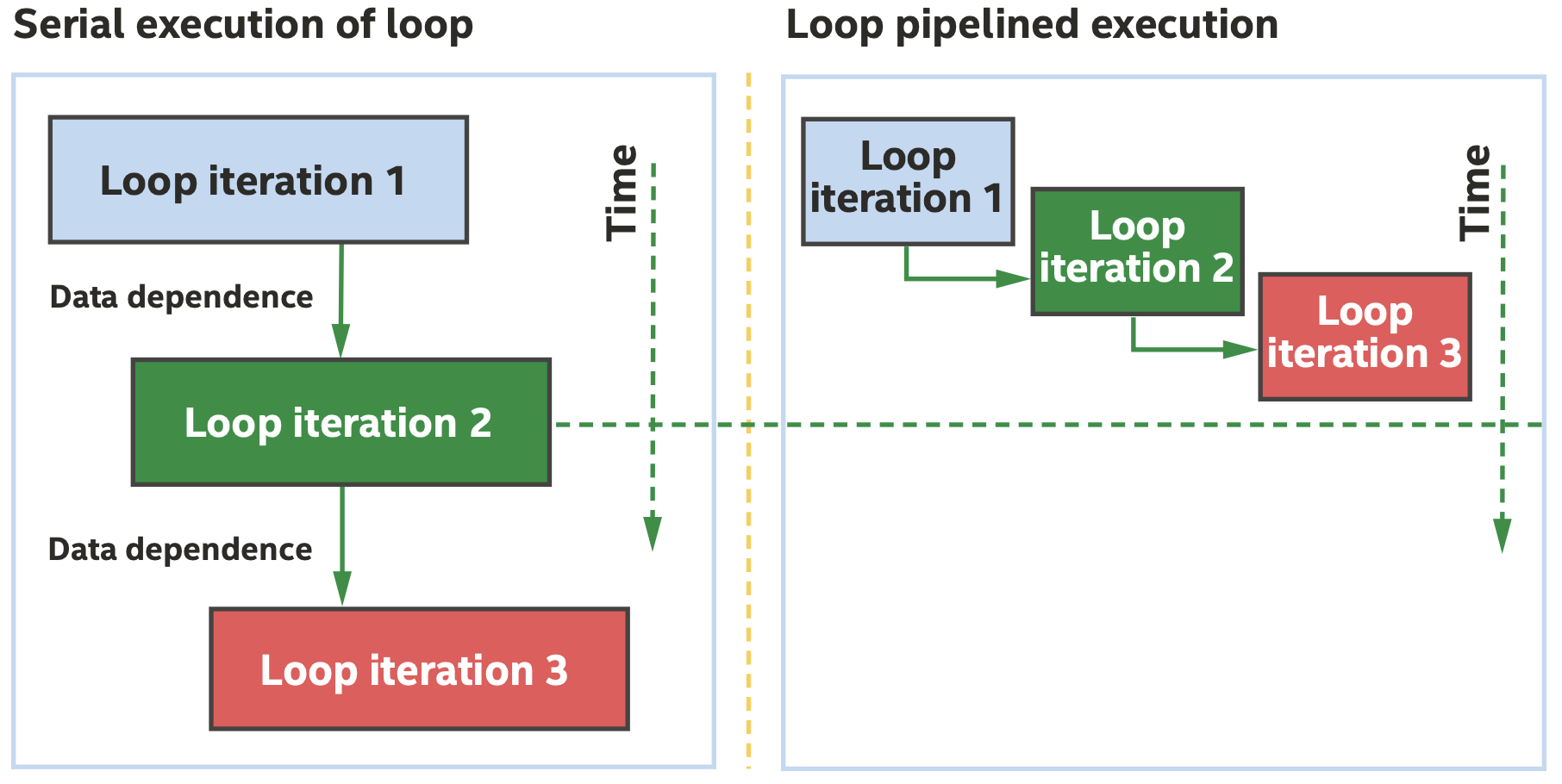 循环流水线化允许iteration在时间上重叠
循环流水线化允许iteration在时间上重叠
即使有数据依赖,仍然可以有效利用流水线,如下图所示。
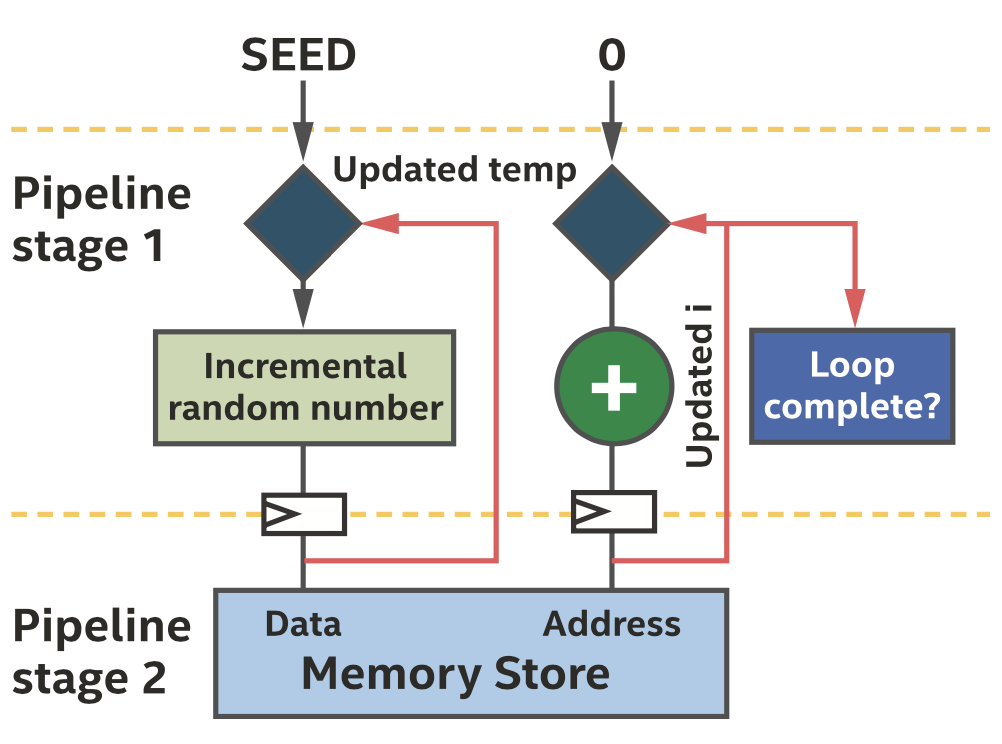 随机数生成器的流水线实现
随机数生成器的流水线实现
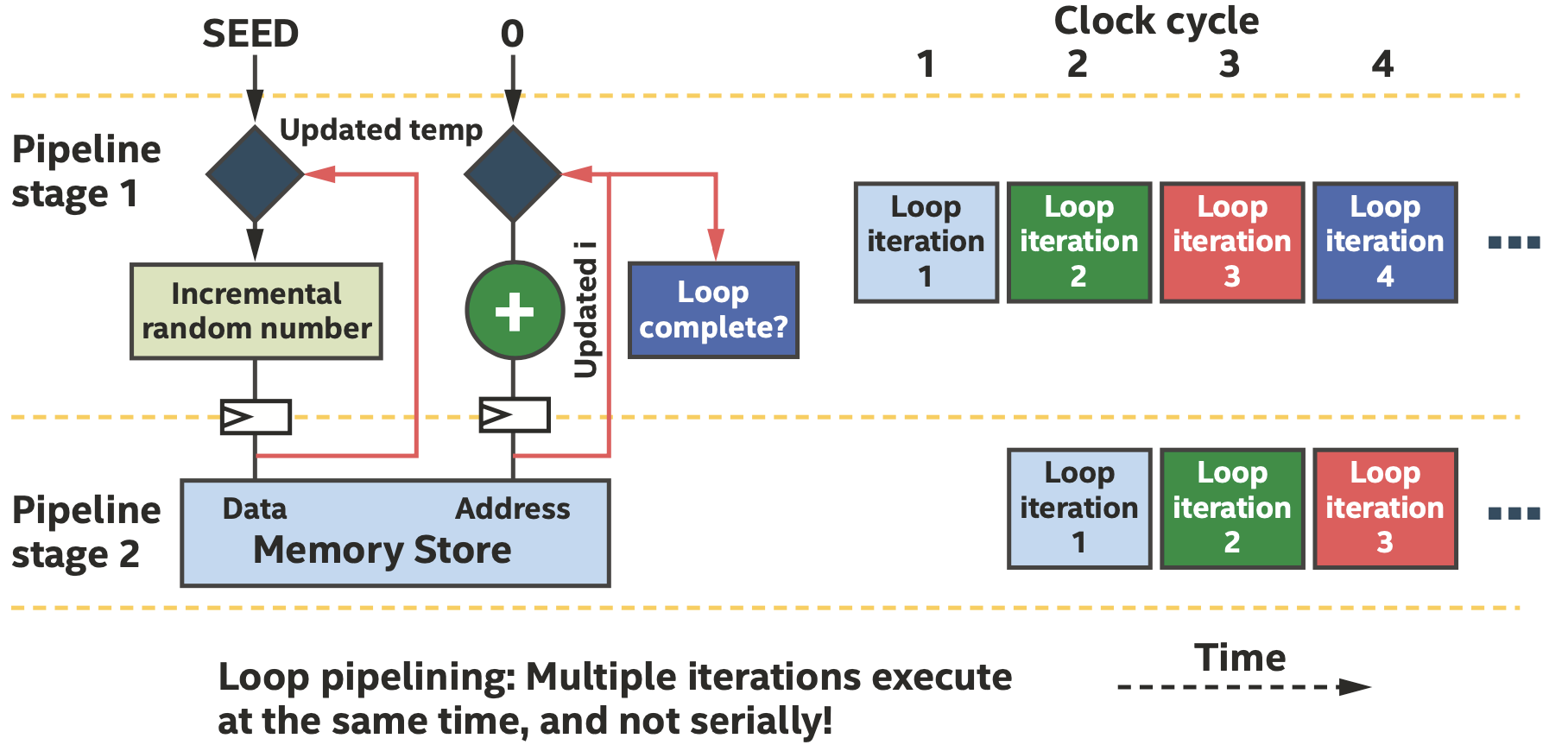 流水线同时处理多个iteration的不同阶段
流水线同时处理多个iteration的不同阶段
然而在实际算法中,往往不可能每一个时钟周期都启动一次新的iteration,可能是因为数据依赖可能需要多个时钟周期来计算。我们把每隔多少个时钟周期启动一次新的iteration的时钟周期称为initiation interval,即II,如下图所示。
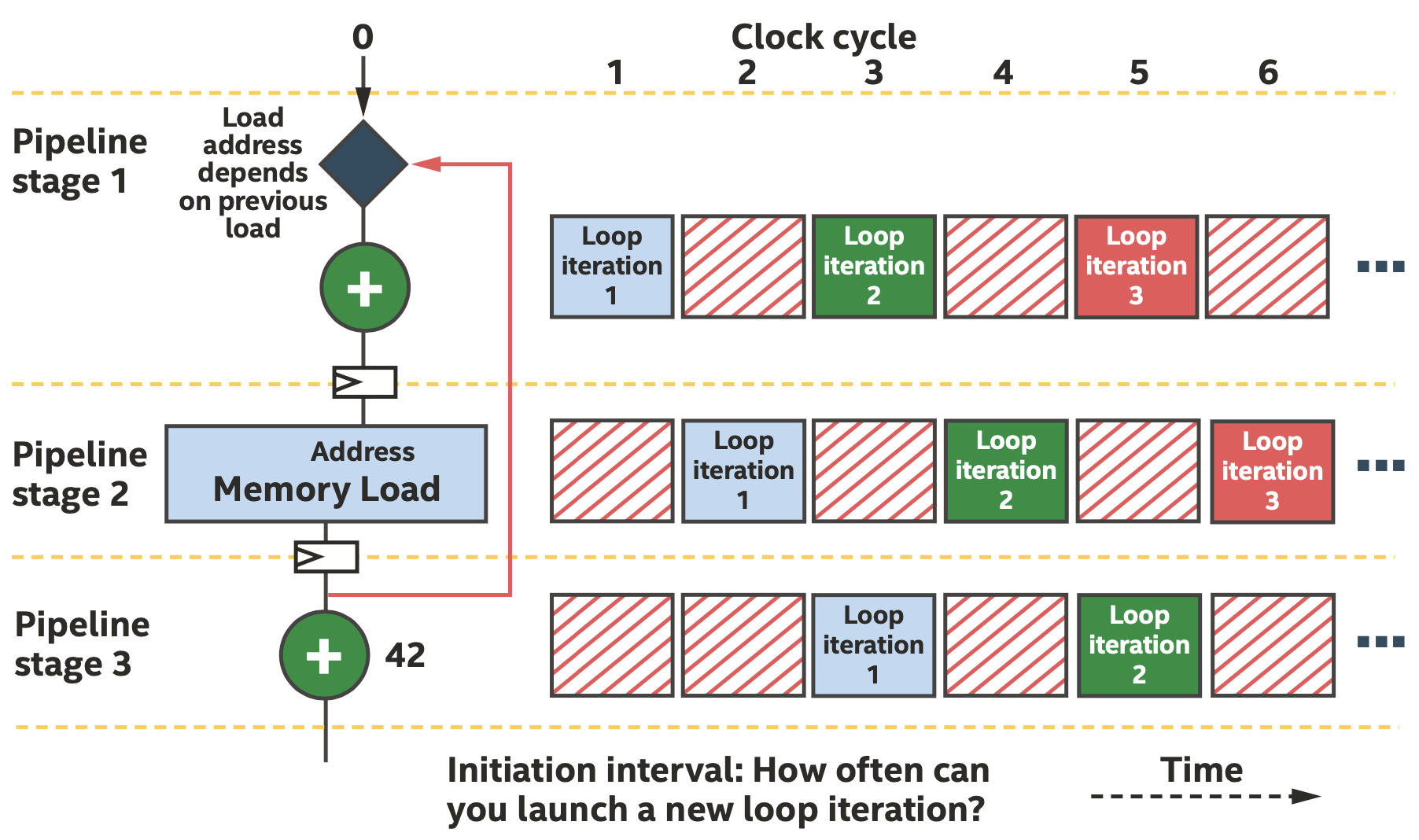 II=2的情况
II=2的情况
管道
空间架构的一个重要概念是FIFO缓冲区,有两个重要性质:
FIFO有隐含的控制信息,即empty和full信号
FIFO有存储能力,存在动态行为的情况下更容易提升性能(如控制访问内存的延迟)
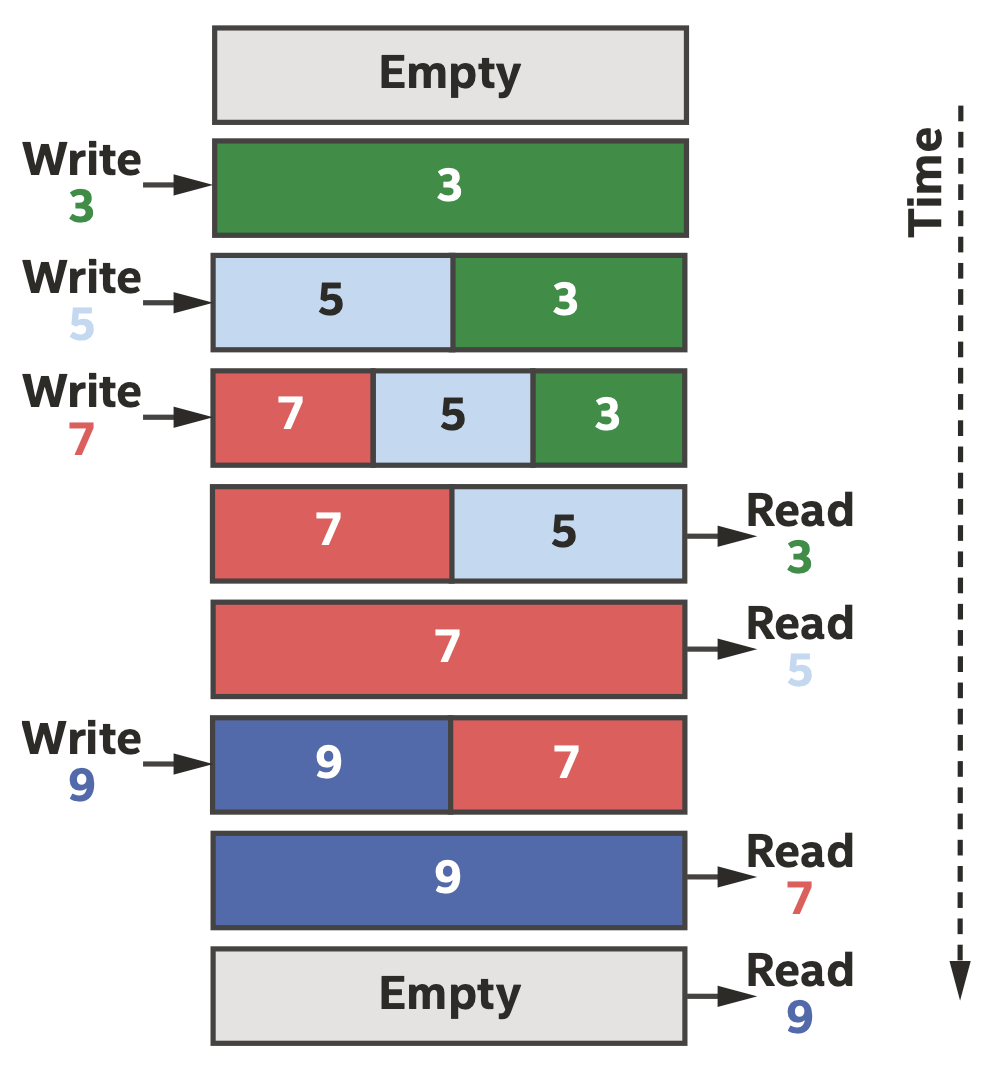 FIFO
FIFO
在DPC++中,我们通过管道来访问FIFO,FIFO可以让我们把问题分解为更小的部分,以模块化的方法来专注于开发和优化,并利用FPGA丰富的通信功能,如下图所示。
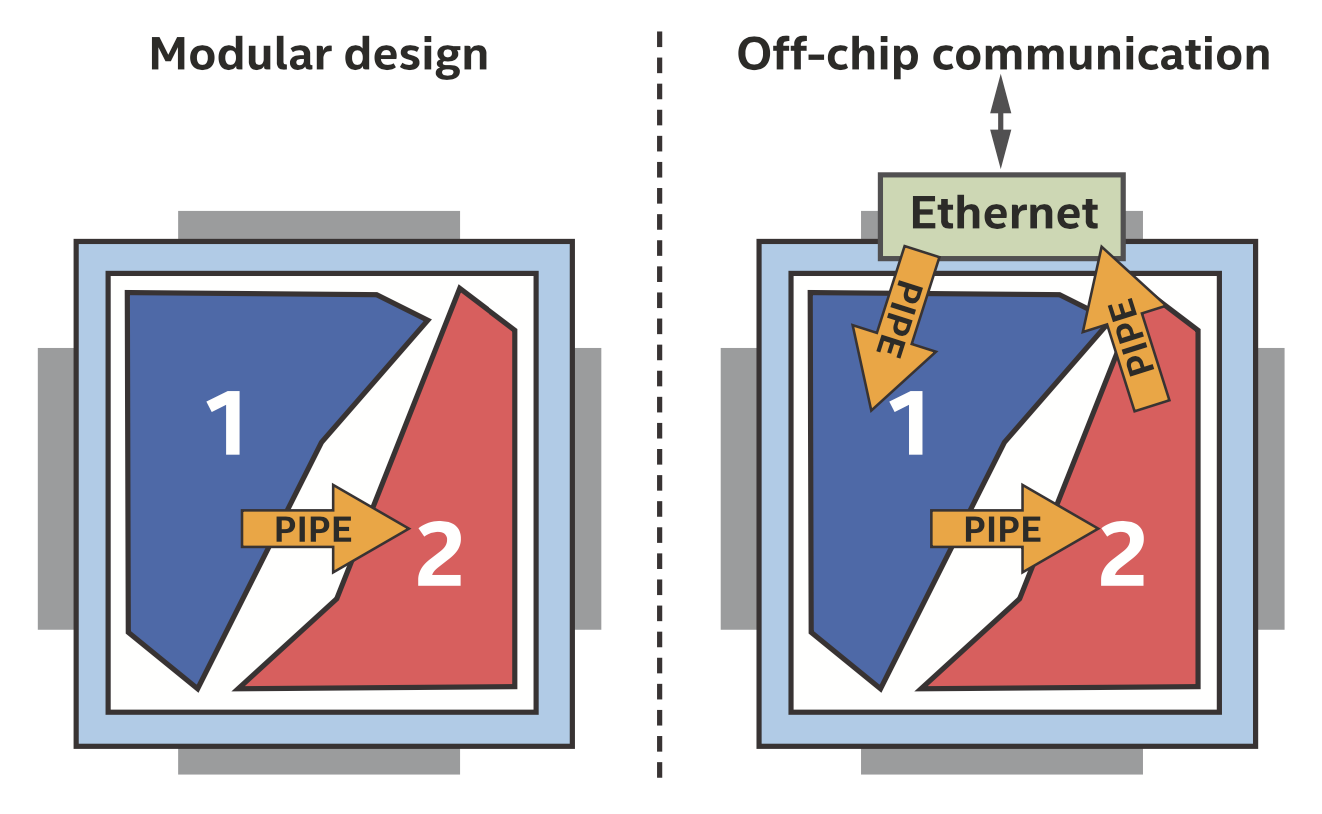 管道简化了模块化设计和外围硬件的访问
管道简化了模块化设计和外围硬件的访问
如下图所示,一般有四种类型的管道可以使用,我们主要介绍第一种。
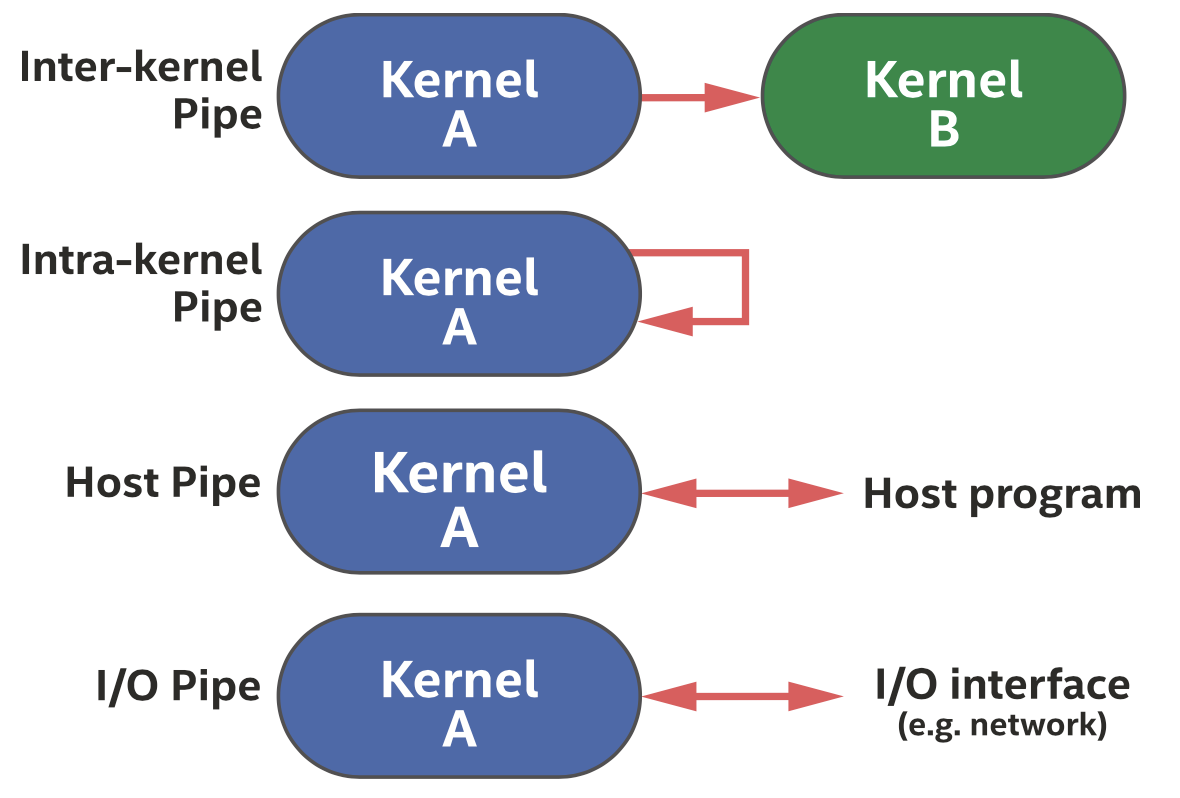 DPC++的四种管道类型
DPC++的四种管道类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// Create alias for pipe type so that consistent across uses
using my_pipe = pipe<class some_pipe, int>;
// ND-range kernel
Q.submit([&](handler& h) {
auto A = accessor(B_in, h);
h.parallel_for(count, [=](auto idx) {
my_pipe::write( A[idx] );
});
});
// Single_task kernel
Q.submit([&](handler& h) {
auto A = accessor(B_out, h);
h.single_task([=]() {
for (int i=0; i < count; i++) {
A[i] = my_pipe::read();
}
});
});
上面的例子展示了如何在ND-range的parallel_for和包含了一个循环的single_task两个kernel之间通信,如果kernel之间没有accessor或事件的依赖,DPC++可以同时执行两个kernel。下面的代码是管道类的模板类型定义,三个模板参数共同定义了管道类型。
1
2
3
4
template <typename name,
typename dataT,
size_t min_capacity = 0>
class pipe;
管道有两种风格的接口:阻塞和非阻塞。前者等待操作成功,后者则立即返回,并设置一个布尔值表示操作是否成功。下面的代码是访问管道类成员函数的两种形式。
1
2
3
4
5
6
7
// Blocking
T read();
void write( const T &data );
// Non-blocking
T read( bool &success_code );
void write( const T &data, bool &success_code );
优化访存
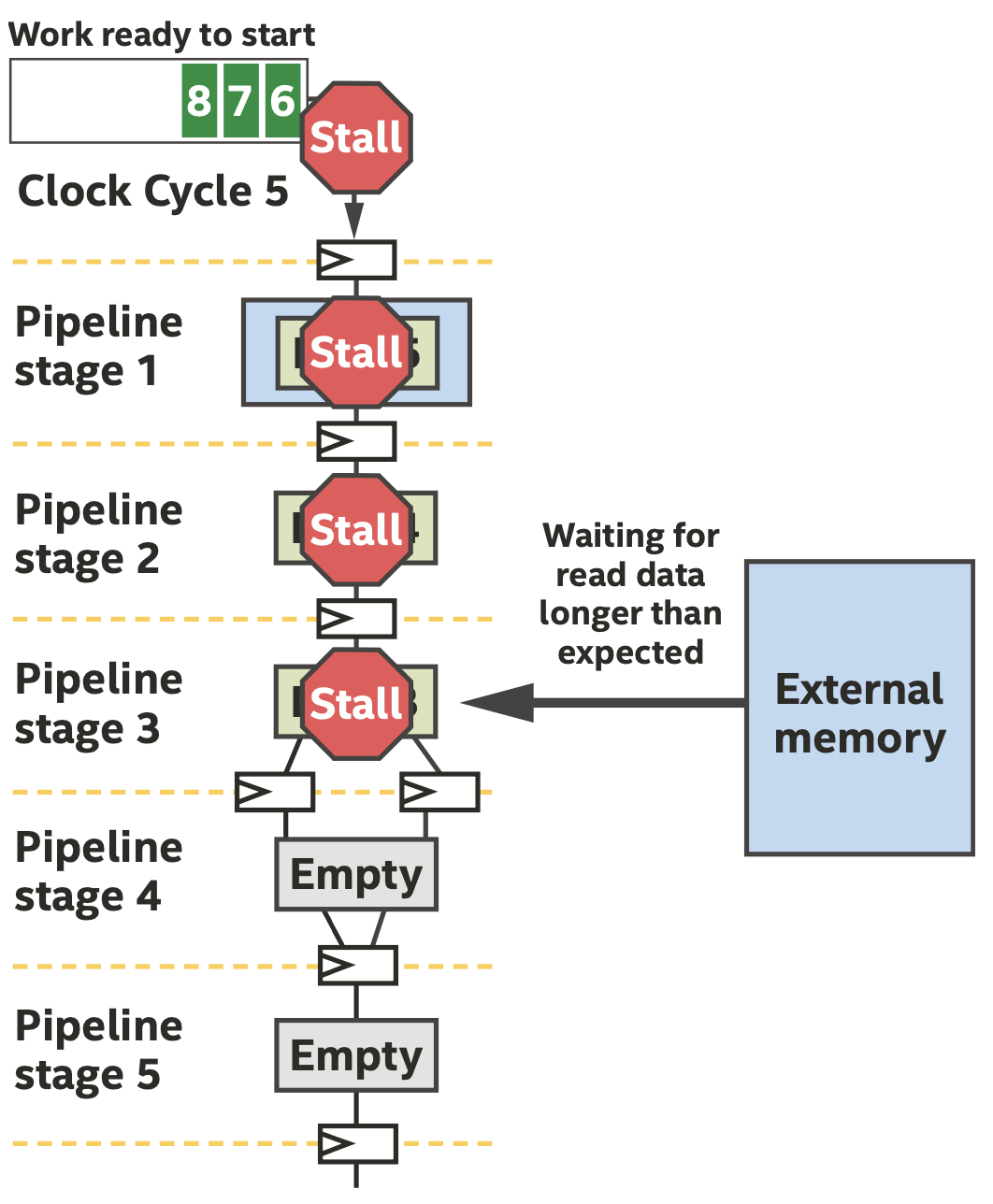 访存延迟导致流水线停顿
访存延迟导致流水线停顿
访存延迟可能导致流水线停顿,我们可以通过下面一些优化来提升性能,优化可以通过显式控制和修改代码,让编译器推断出我们想要的结构,常见的优化包括:
静态合并:编译器回尽量将一些访存请求合并,减少load或store单元数量、内存系统端口、仲裁网络的大小和复杂性等硬件。
内存访问方式:编译器会为访存创建load或store单元,这些单元会根据访问的内存(如片上存储器、DDR、HBM等)以及源代码推断出的访问模式(流式、动态合并等)来进行定制。
内存系统结构:片上或片外内存系统可以由编译器实现bank结构或其他优化。