我们继续深入讨论DPC++并行编程,首先我们从任务图开始研究kernel调度的机制以及数据移动的机制,接下来讨论如何将一个大任务分解成一些小任务,用并行的思维去看待问题,最后我们讨论如何有多种方法定义kernel。
Kernel调度与数据移动
图调度
我们之前讨论过依赖关系的概念,包括RAW、WAR与WAW。我们之前讨论过,一个命令组可以包含一个动作、依赖关系以及其他主机代码,其中动作是不可或缺的,命令组通常被表达为传递给submit方法的lambda表达式,也可以通过队列的快捷方法来表达。
一个命令组可以执行两种类型的动作:kernel和显式内存操作,且一个命令组只能执行一个动作。kernel是通过调用parallel_for或single_task方法来定义的;显式数据移动的操作包括USM的memcpy、memset、fill操作以及缓冲区的copy、fill、update_host操作。
命令组有几种方式指定依赖关系。首先可以使用顺序队列;可以使用基于事件的依赖关系,可以通过两种方式指定,第一种是通过depends_on函数传递一个事件作为参数,第二种是在队列上直接调用parallel_for或single_task传递事件;最后也可以通过accessor对象来指定数据依赖关系。
我们知道,一旦kernel的依赖关系被满足,kernel就会被执行。同时,当一个命令组被提交到队列时,命令组的代码将立即在主机上执行(在submit函数返回之前),且只执行一次。
数据移动
我们之前已经讨论过一部分数据移动的内容,数据移动也会影响DPC++中的任务图调度。对显式数据移动而言,优点在于数据移动明确出现在图中。隐式数据移动则可能会对DPC++中的命令组和任务图产生隐藏的作用。
与主机同步
我们讨论的最后一个话题是如何使图的执行与主机同步。
第一种方法是等待,队列对象由两种方法,wait和wait_and_throw,不过这种方法过于简单,我们可能需要更细致的控制;第二种方法是对事件进行同步,允许程序只在特定的动作或命令组上同步;第三种方法是使用主机accessor,即host_accessor,确保被复制回主机的数据是计算完成之后的值,但需要注意的是主机上的原始内存不能保证包含最新的值,主机accessor存在并保持数据可用时,设备不能访问该缓冲区,因此一个常见的模式是在某个C++作用域内创建主机accessor;最后一种方法是利用缓冲区的属性use_mutex,不过这种方式并不常见。
通信与同步
Work-Groups和Work-Items
我们之前讨论过ND-range和分层并行kernel将work-item组织称work-group的形式,保证work-group中的work-item并发执行。
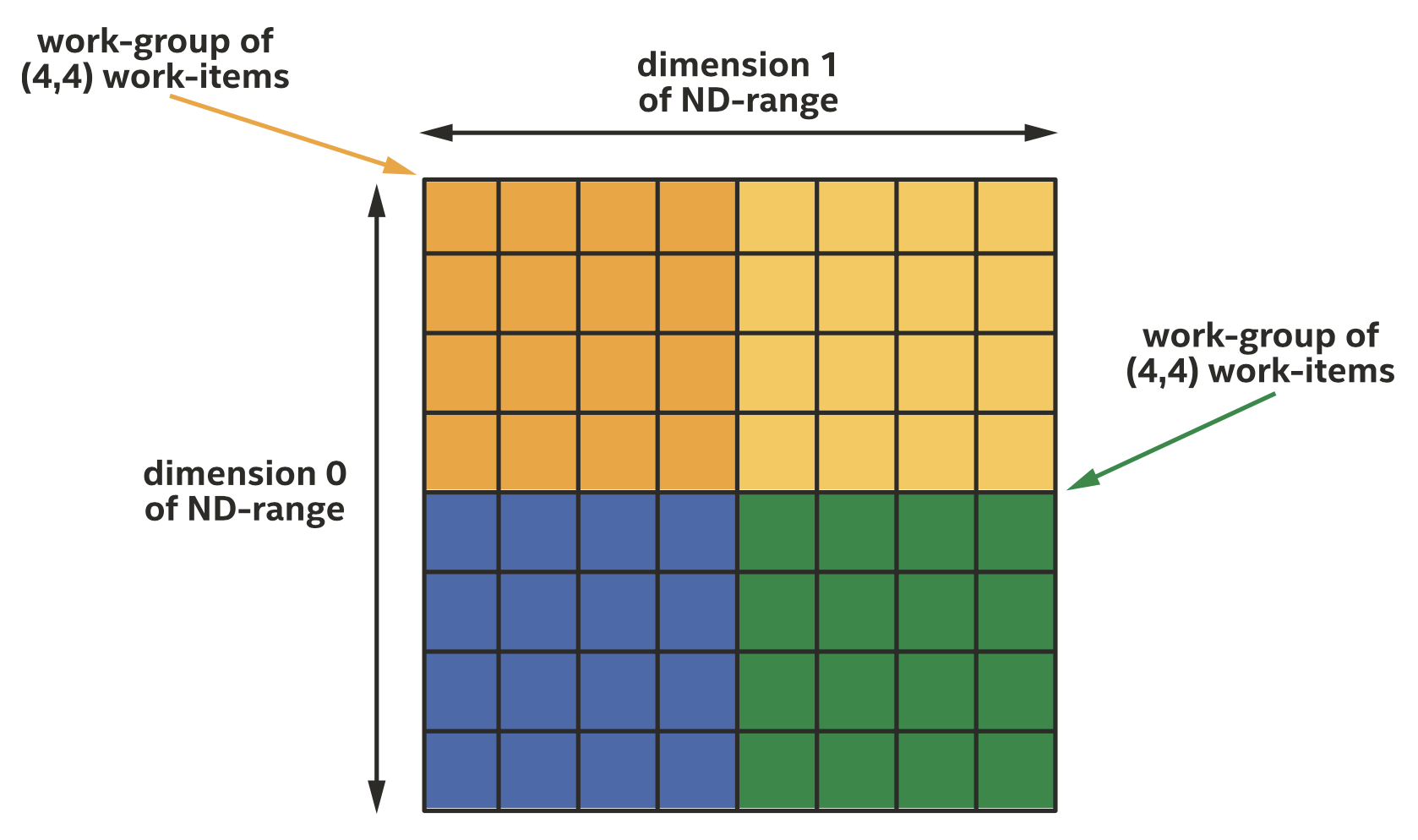 大小为(8,8)的二维ND-range被切分成四个大小为(4,4)的work-groups
大小为(8,8)的二维ND-range被切分成四个大小为(4,4)的work-groups
同一work-group内的work-item可以保证同时执行,不同work-group内的work-item不能保证同时执行,这种情况下如果不同work-group的work-item进行通信,可能会出现死锁。
如何高效通信
通过Barrier进行同步
Barrier由两个关键目的:首先是保证一个work-group内的work-item同步执行,其次是同步每个work-item访问内存的状态,即确保内存一致性。
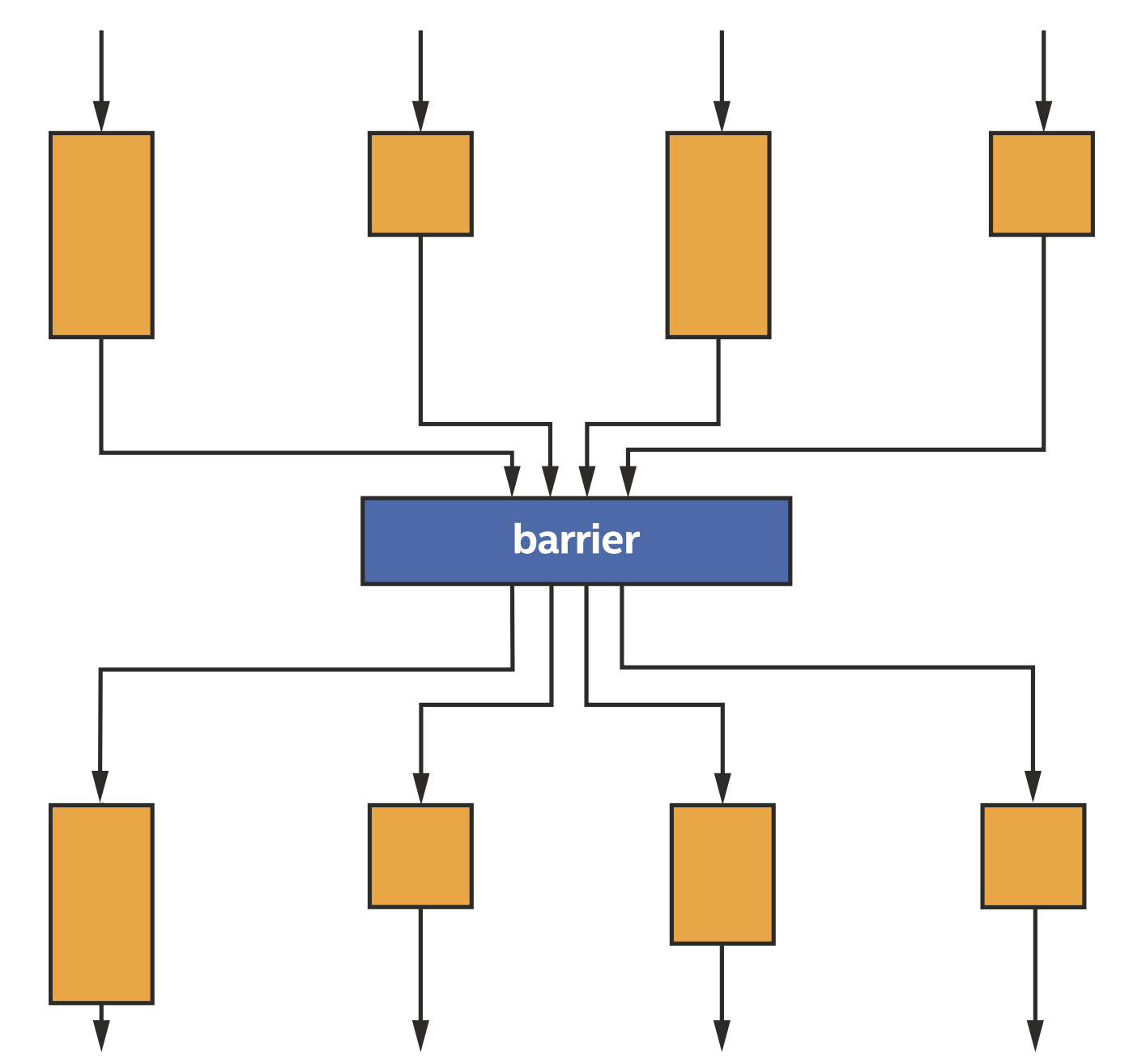 同一个work-group内的四个work-items通过barrier进行同步
同一个work-group内的四个work-items通过barrier进行同步
Work-Group本地内存
通信可以通过USM或缓冲区进行,但可能效率不高,因而可以专门划分一部分内存用于通信,作为work-group的本地内存。
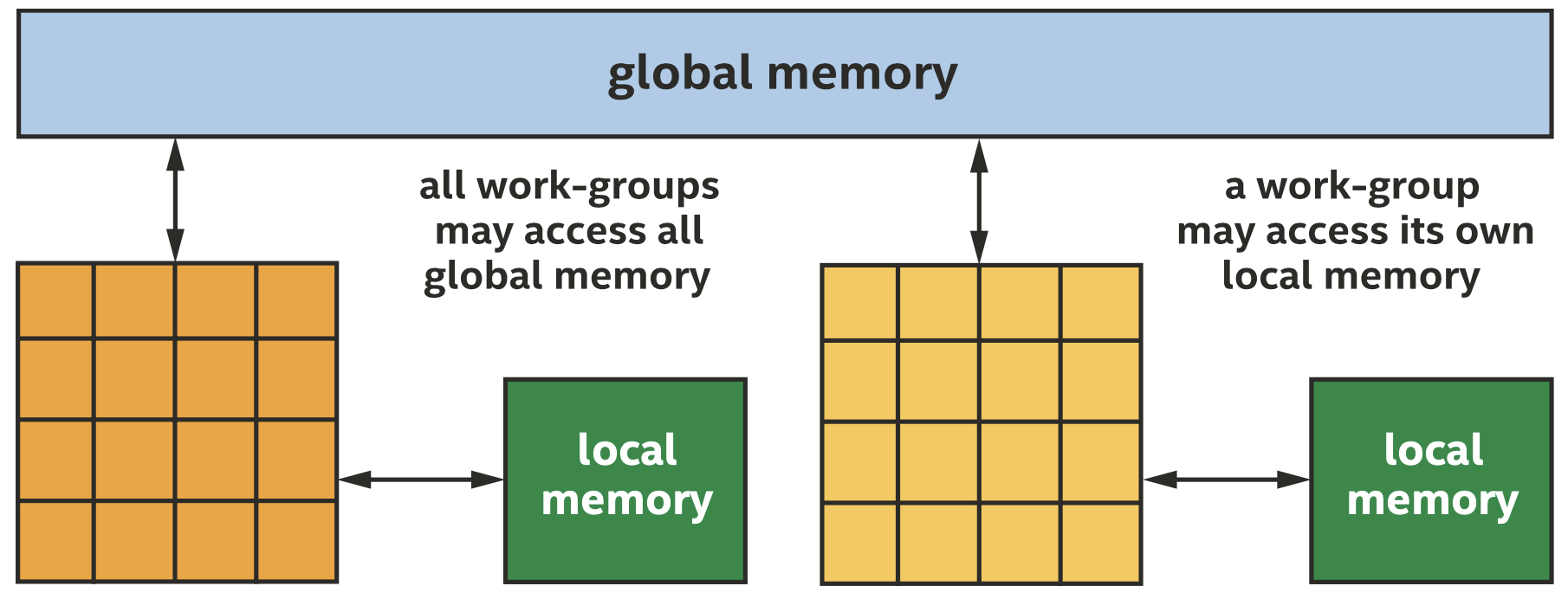 每个work-group都可以访问全局内存或自己的本地内存
每个work-group都可以访问全局内存或自己的本地内存
当一个work-group开始执行时,本地内存的内容是未初始化的,且执行完成后会释放本地内存,因而本地内存只能用于临时存储。对CPU来说,本地内存和全局内存在物理上没什么区别,但是对GPU等其他设备而言,访问本地内存的性能会更好。我们可以使用info::device::local_mem_type来确定一个加速器是否有专门的资源用于本地内存。
使用Work-Group Barriers和本地内存
注意Work-item之间的通信需要work-group的存在,因此这些概念只在ND-range kernel和分层kernel中出现。我们以矩阵乘法kernel为例介绍work-groupo之间的通信,在许多设备(但不是所有设备上),通过本地内存进行通信可以提高矩阵乘法kernel的性能。
1
2
3
4
5
6
7
8
9
10
11
h.parallel_for(range{M, N}, [=](id<2> id) {
int m = id[0];
int n = id[1];
T sum = 0;
for (int k = 0; k < K; k++) {
sum += matrixA[m][k] * matrixB[k][n];
}
matrixC[m][n] = sum;
});
需要注意的是,很多供应商专门对矩阵乘法做了优化,例如可以从oneMKL中寻找合适的解决方案,而非自己重新实现一个矩阵乘法的kernel。
我们之前已经注意到通过对work-item进行分组可以提升访问局部性,提高缓存命中率,在这一节中我们不再依靠隐式缓存行为,而使用本地内存作为显式缓存,在确定数据访问位置的情况下来提升性能。对很多算法而言,我们确实可以把本地内存看作是显式的缓存。
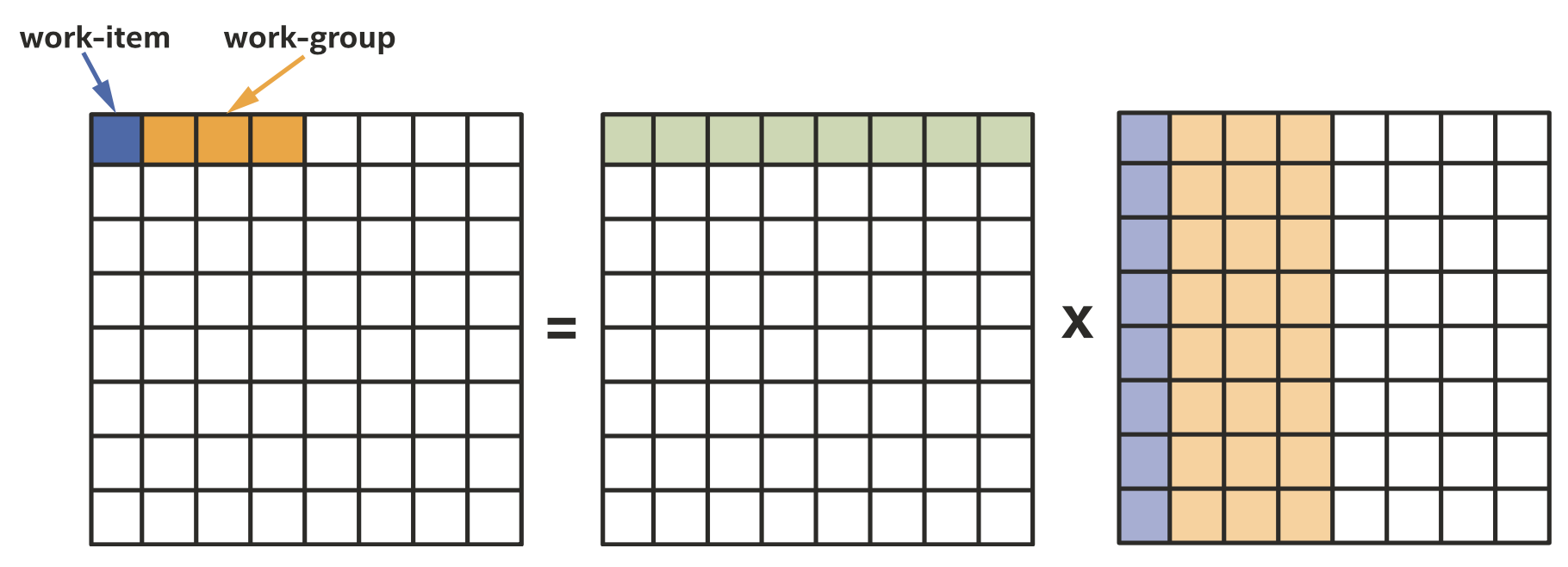 把矩阵乘法映射到work-groups和work-items
把矩阵乘法映射到work-groups和work-items
我们按上图所示的方式划分work-group,我们注意到绿色的部分很适合放在本地内存中。由于本地内存大小优先,我们把将要在本地内存上处理的矩阵部分称为tile,对每一个tile我们把矩阵的数据load到本地内存中,同步work-items,然后就可以从本地内存中load数据了,如下所示。注意我们选择的tile大小与工作组大小相等,这并非必须,但是选择一个work-group大小倍数的tile是很常见且方便的。
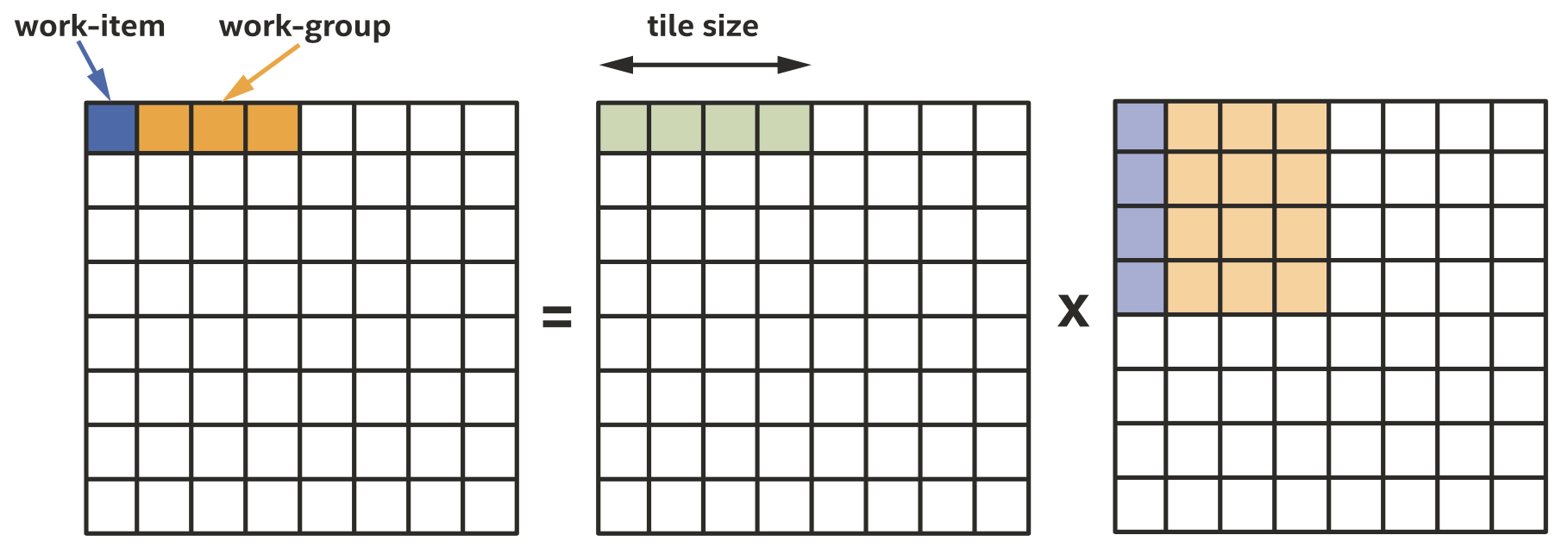 绿色的数据从本地内存访问,蓝色和淡橙色的部分从全局内存访问
绿色的数据从本地内存访问,蓝色和淡橙色的部分从全局内存访问
ND-Range Kernel中的Work-Group Barriers和本地内存
Kernel声明并操作一个本地accessor,代表本地地址空间中的内存分配,并调用一个barrier函数来同步work-group中的work-items。访问本地内存需要使用本地accessor,但本地accessor不是从缓冲区对象创建的。本地accessor必须是read-write属性的。为了同步ND-range kernel work-group内的work-item,需要调用nd_item类中的barrier函数。
ND-range kernel版本的矩阵乘法如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
// Traditional accessors, representing matrices in global memory:
accessor matrixA{bufA, h};
accessor matrixB{bufB, h};
accessor matrixC{bufC, h};
// Local accessor, for one matrix tile:
constexpr int tile_size = 16;
auto tileA =
accessor<T, 1, access::mode::read_write, access::target::local>(
tile_size, h);
h.parallel_for(
nd_range<2>{ {M, N}, {1, tile_size}}, [=](nd_item<2> item) {
// Indices in the global index space:
int m = item.get_global_id()[0];
int n = item.get_global_id()[1];
// Index in the local index space:
int i = item.get_local_id()[1];
T sum = 0;
for (int kk = 0; kk < K; kk += tile_size) {
// Load the matrix tile from matrix A, and synchronize
// to ensure all work-items have a consistent view
// of the matrix tile in local memory.
tileA[i] = matrixA[m][kk + i];
item.barrier();
// Perform computation using the local memory tile, and
// matrix B in global memory.
for (int k = 0; k < tile_size; k++) {
sum += tileA[k] * matrixB[kk + k][n];
}
// After computation, synchronize again, to ensure all
// reads from the local memory tile are complete.
item.barrier();
}
// Write the final result to global memory.
matrixC[m][n] = sum;
});
分层Kernel中的Work-Group Barriers和本地内存
与ND-range kernel不同,分层kernel中的本地内存和barrier是隐式的,不需要特殊的语法或函数调用。在分层kernel中,我们使用parallel_for_work_group和parallel_for_work_item函数来表达两个层次的并行执行,可以通过这两个层次来表达一个变量是否在work-group的本地内存中,以及是否被work-group内的所有work-item共享。
分层kernel版本的矩阵乘法如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
const int tileSize = 16;
range group_size{1, tileSize};
range num_groups{M, N / tileSize};
h.parallel_for_work_group(num_groups, group_size, [=](group<2> group) {
// Because this array is declared at work-group scope
// it is in local memory
T tileA[16];
for (int kk = 0; kk < K; kk += tileSize) {
// A barrier may be inserted between scopes here
// automatically, unless the compiler can prove it is
// not required
// Load the matrix tile from matrix A
group.parallel_for_work_item([&](h_item<2> item) {
int m = item.get_global_id()[0];
int i = item.get_local_id()[1];
tileA[i] = matrixA[m][kk + i];
});
// A barrier gets inserted here automatically, so all
// work items have a consistent view of memory
group.parallel_for_work_item([&](h_item<2> item) {
int m = item.get_global_id()[0];
int n = item.get_global_id()[1];
for (int k = 0; k < tileSize; k++) {
matrixC[m][n] += tileA[k] * matrixB[kk + k][n];
}
});
// A barrier gets inserted here automatically, too
}
});
Sub-Group
ND-range kernel中还有一种分组方式叫sub-group。Sub-group也有自己的barrier函数,只同步sub-group内的work-items。不过sub-group没有专门的内存空间,通常使用集体函数(collective function)来交换数据。我们接下来用broadcast广播集体函数来实现基于sub-group的矩阵乘法。
ND-range中使用sub-group的kernel版本的矩阵乘法如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// Note: This example assumes that the sub-group size is greater than or
// equal to the tile size!
static const int tileSize = 4;
h.parallel_for(
nd_range<2>{ {M, N}, {1, tileSize}}, [=](nd_item<2> item) {
auto sg = item.get_sub_group();
// Indices in the global index space:
int m = item.get_global_id()[0];
int n = item.get_global_id()[1];
// Index in the local index space:
int i = item.get_local_id()[1];
T sum = 0;
for (int_fast64_t kk = 0; kk < K; kk += tileSize) {
// Load the matrix tile from matrix A.
T tileA = matrixA[m][kk + i];
// Perform computation by broadcasting from the matrix
// tile and loading from matrix B in global memory. The loop
// variable k describes which work-item in the sub-group to
// broadcast data from.
for (int k = 0; k < tileSize; k++) {
sum += group_broadcast(sg, tileA, k) * matrixB[kk + k][n];
}
}
// Write the final result to global memory.
matrixC[m][n] = sum;
});
集体函数
我们现在进一步讨论集体函数,对常见通信模式使用集体函数可以简化代码并提升性能。
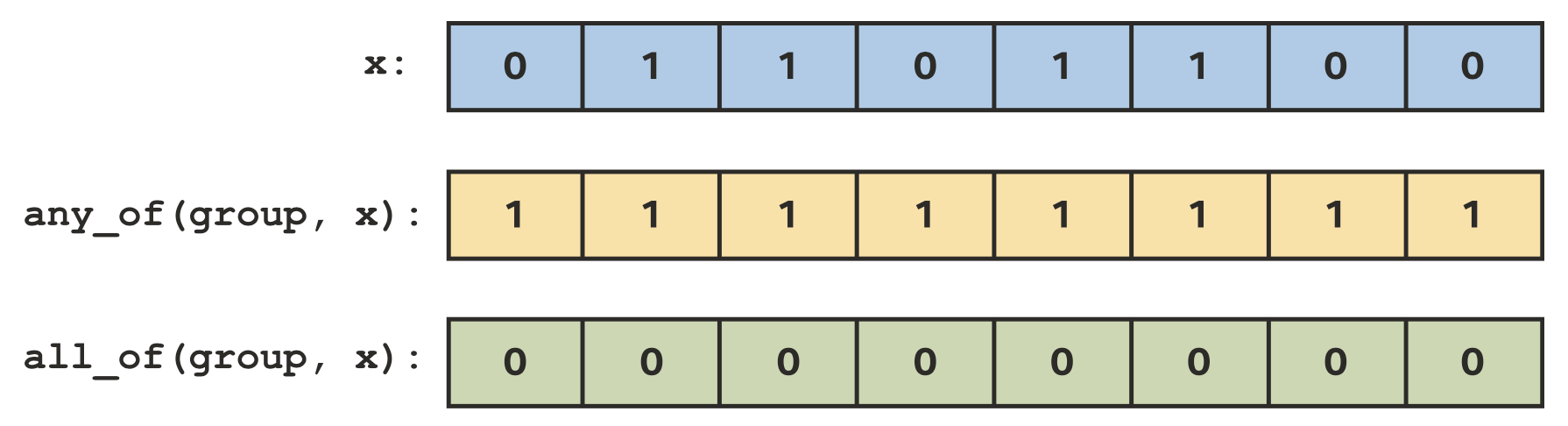
broadcast广播函数运行一个work-item和其他组内的work-item共享变量的值,work-group和sub-group都支持广播。any_of和all_of投票函数可以用来比较一个work-group内bool条件的结果,work-group和sub-group都支持投票。shuffle操作可以在一个sub-group内进行任意的通信。Sub-group的load和store可以通知编译器组内的所有work-item都是从同一位置开始load连续的数据,以及可以优化大量连续数据的load和store。
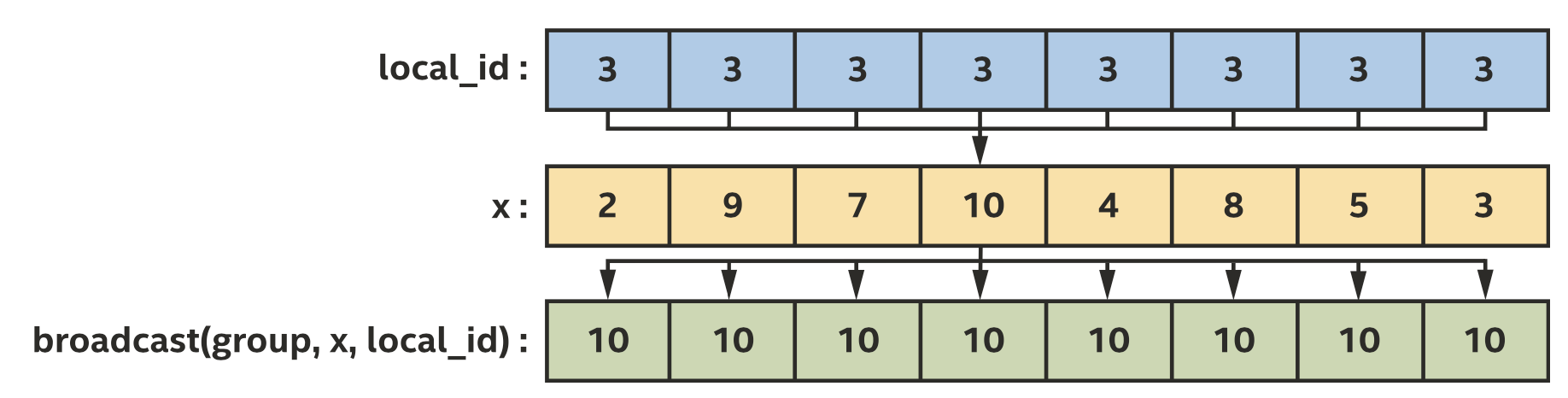 广播函数
广播函数
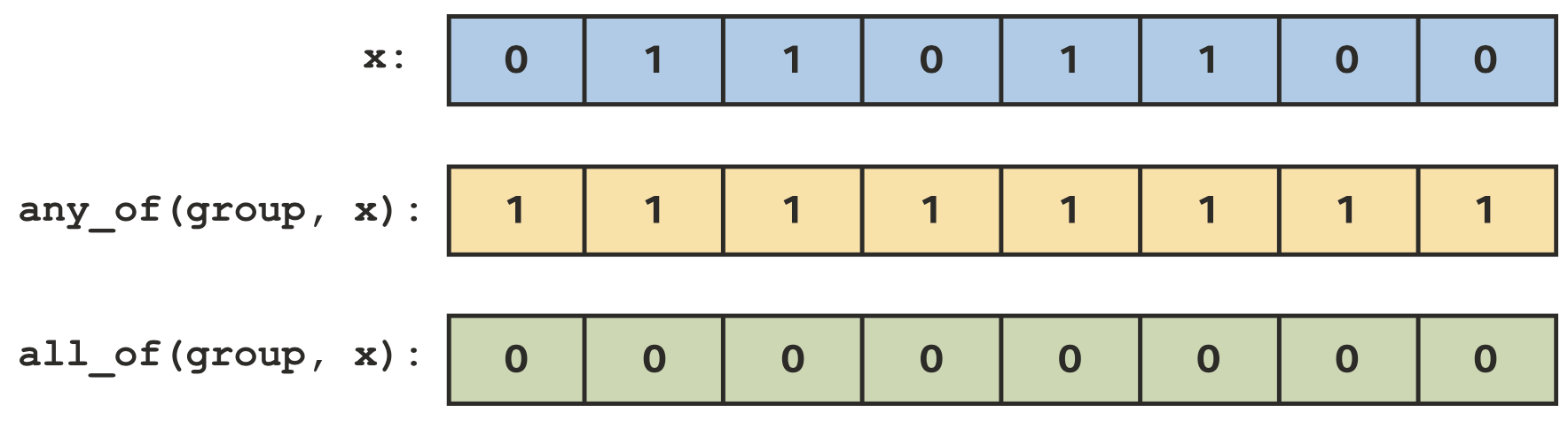 投票函数
投票函数
 使用通用
使用通用shuffle操作,基于计算好的排列下标来对x的值进行排序
 使用
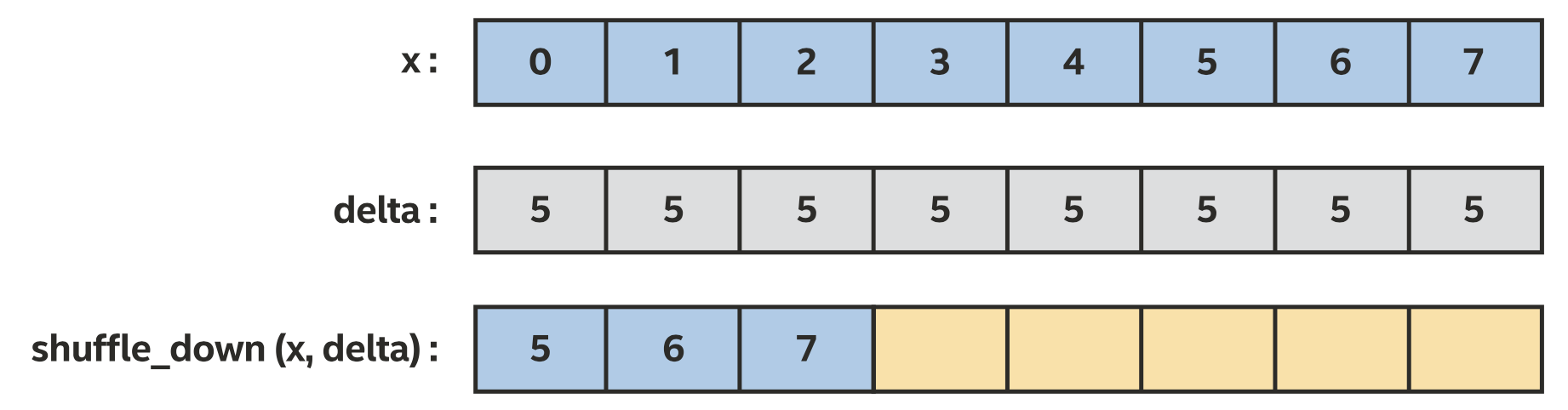
使用shuffle_down来移动sub-group内x的值
 使用
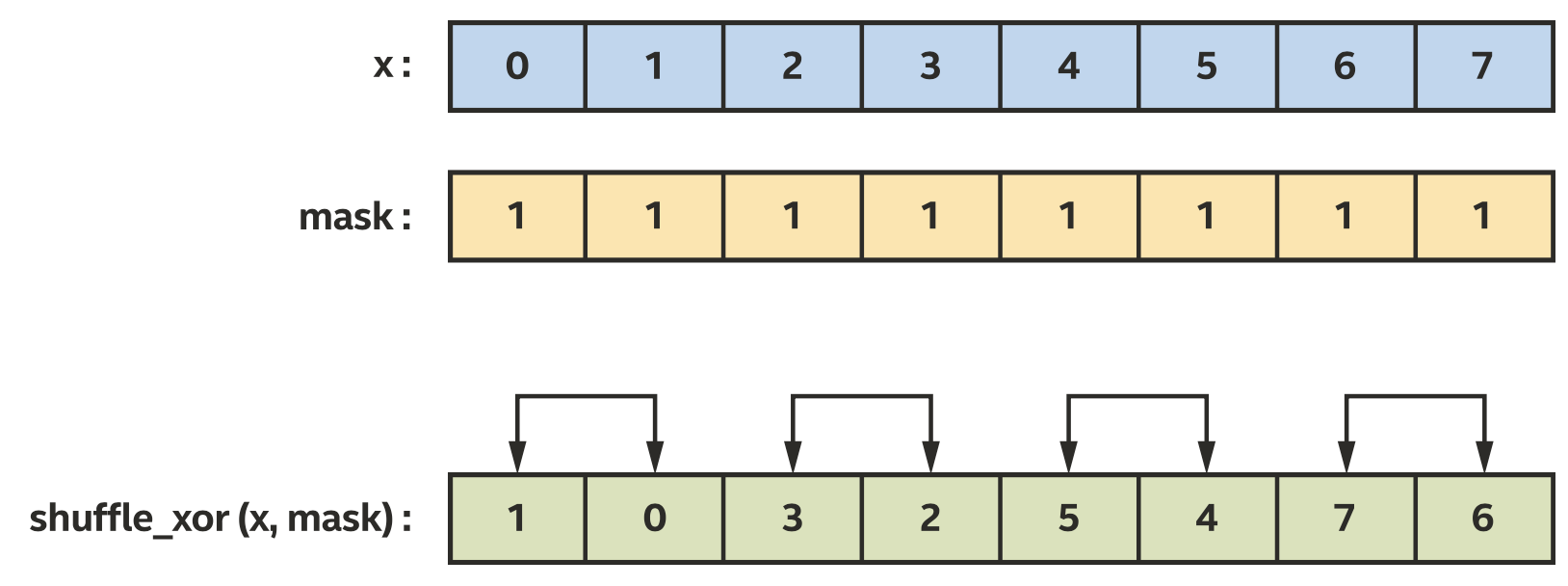
使用shuffle_xor来交换相邻的x
 使用
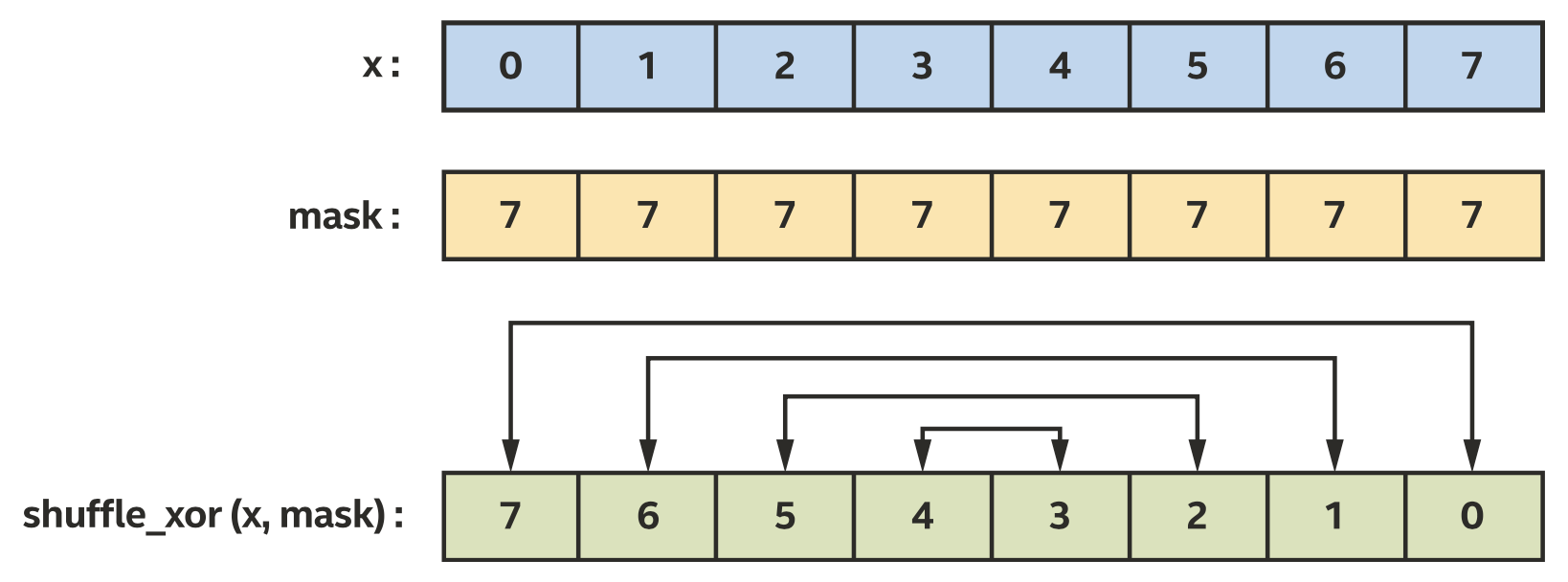
使用shuffle_xor来反转x
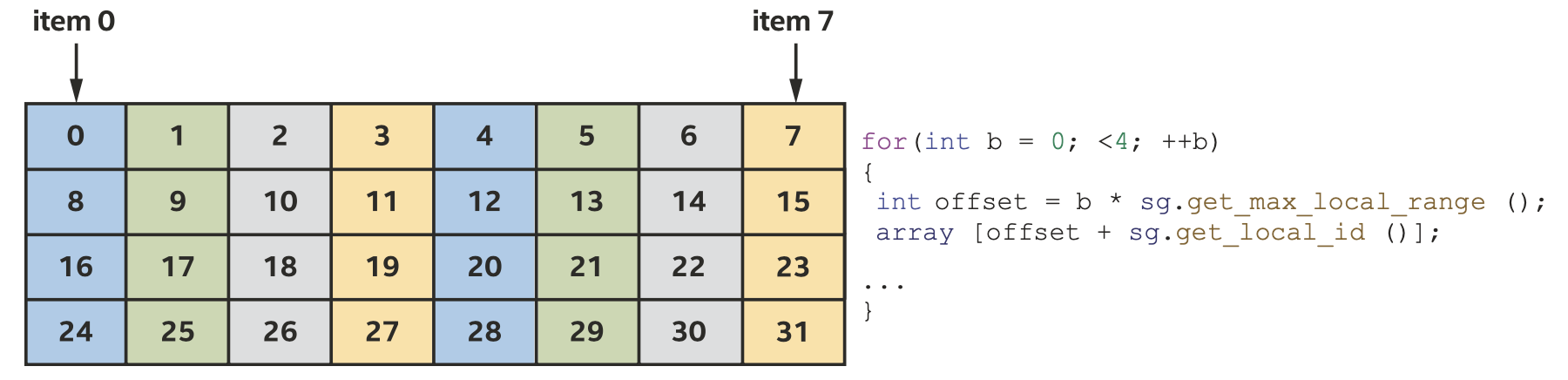 Sub-group访问4个相邻区块的内存访问模式
Sub-group访问4个相邻区块的内存访问模式
定义Kernel
我们主要讨论三种表示kernel的方法:lambda表达式、命名函数对象(functors)和其他语言或API创建的kernel。
Lambda表达式
到目前为止我们都在使用lambda表达式来定义kernel,如下是lambda表达式的一般形式。
 Kernel lambda表达式的一般形式,包括了可选元素
Kernel lambda表达式的一般形式,包括了可选元素
一般的C++ lambda表达式可以通过复制或引用来捕获一个变量,但是对kernel lambda表达式,变量只能通过复制来捕获。异常必须使用noexcept,因为kernel不支持任何形式的异常。lambda属性也是支持的,可以用来控制kernel的编译方式,例如图中的reqd_work_group_size可以用来表示kernel要求特定的work-group大小。可以指定返回类型,但是对kernel来说必须是void。
命名函数对象
命名函数对象,也叫functors,是C++定义的一种特殊的类,相比lambda表达式往往需要更多代码,但也提供了更多的控制和额外的能力,和其他C++类一样也可以使用模板。下面是使用命名函数对象的一个例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
#include <CL/sycl.hpp>
#include <array>
#include <iostream>
using namespace sycl;
class Add {
public:
Add(accessor<int> acc) : data_acc(acc) {}
void operator()(id<1> i) const {
data_acc[i] = data_acc[i] + 1;
}
private:
accessor<int> data_acc;
};
int main() {
constexpr size_t size = 16;
std::array<int, size> data;
for (int i = 0; i < size; i++) {
data[i] = i;
}
{
buffer data_buf{data};
queue Q{ host_selector{} };
std::cout << "Running on device: "
<< Q.get_device().get_info<info::device::name>() << "\n";
Q.submit([&](handler& h) {
accessor data_acc {data_buf, h};
h.parallel_for(size, Add(data_acc));
});
}
for (int i = 0; i < size; i++) {
if (data[i] != i + 1) {
std::cout << "Results did not validate at index " << i << "!\n";
return -1;
}
}
std::cout << "Success!\n";
return 0;
}
其他API
下面的一个例子展示了SYCL kernel如何写成OpenCL C kernel。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// Note: This must select a device that supports interop with OpenCL kernel
// objects!
queue Q{ cpu_selector{} };
context sc = Q.get_context();
const char* kernelSource =
R"CLC(
kernel void add(global int* data) {
int index = get_global_id(0);
data[index] = data[index] + 1;
}
)CLC";
cl_context c = get_native<backend::opencl, context>(sc);
cl_program p =
clCreateProgramWithSource(c, 1, &kernelSource, nullptr, nullptr);
clBuildProgram(p, 0, nullptr, nullptr, nullptr, nullptr);
cl_kernel k = clCreateKernel(p, "add", nullptr);
std::cout << "Running on device: "
<< Q.get_device().get_info<info::device::name>() << "\n";
Q.submit([&](handler& h) {
accessor data_acc{data_buf, h};
h.set_args(data_acc);
h.parallel_for(size, make_kernel<backend::opencl>(k, sc));
});
clReleaseContext(c);
clReleaseProgram(p);
clReleaseKernel(k);
具体的细节比较复杂,可以参考原书。