我们之前简单讨论过管理数据的两种方式,即USM和缓冲区,前者主要使用指针,后者则是一个更高层次的接口,我们接下来深入讨论如何管理数据。
USM
USM基于C++的指针,可以很容易地将现有代码迁移到USM上。
分配类型
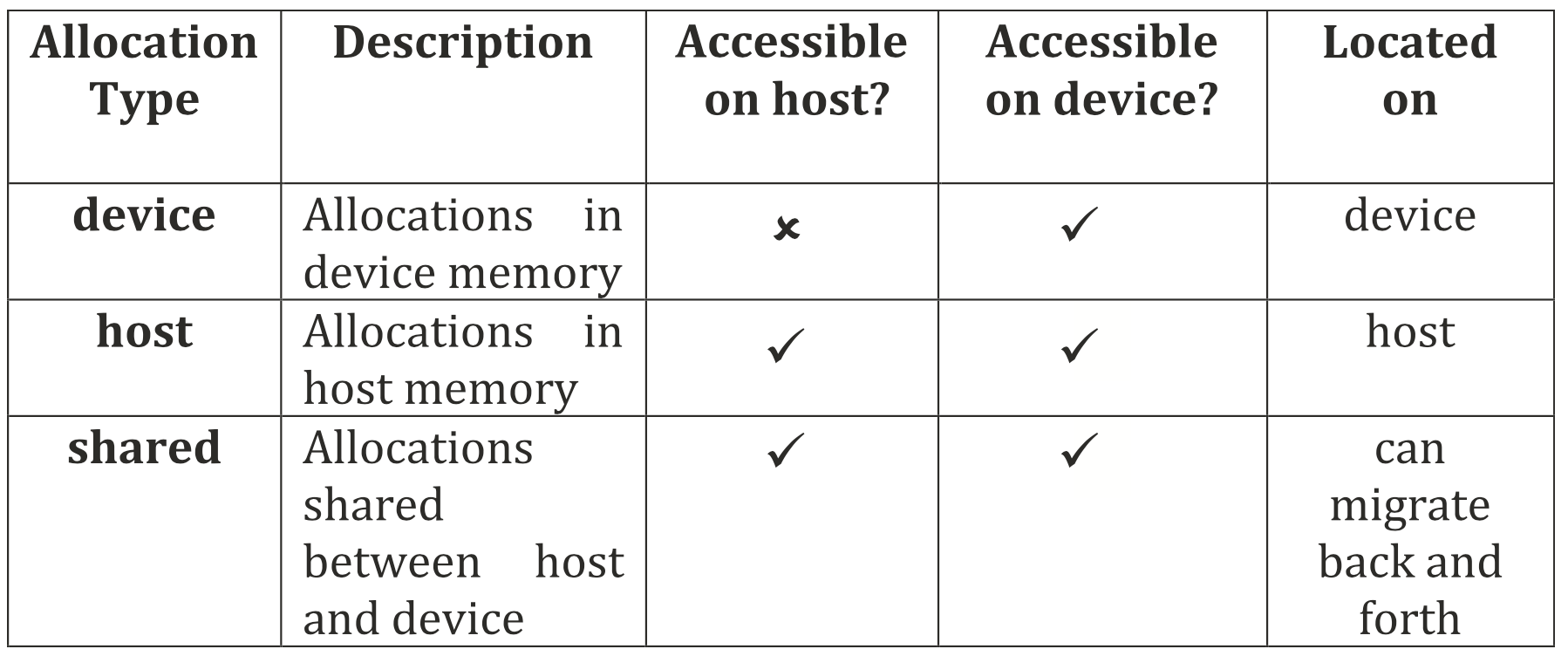 USM内存分配类型
USM内存分配类型
USM定义了三种不同类型的内存分配,每种分配都有独特的语义,需要注意的是,一个设备甚至可能不支持所有类型的USM分配。
设备分配
这种分配类型可以在设备存储器上分配内存,如(G)DDR或HBM等,但不能在主机上访问。如果需要在主机上访问,需要使用USM memcpy机制来复制数据。
主机分配
主机分配在主机的内存中分配空间,在主机和设备上都可以访问,但不能迁移到设备的存储器中。从设备访问是远程进行的,通常会通过一个较慢的总线,如PCI-Express。
共享分配
共享分配结合了前两者的优点,可以在主机和设备上访问,且可以自行迁移数据而无需干预。不过,共享分配仍然有潜在的问题,如果自动迁移数据可能会增加延迟,无法控制。
内存分配
在C++中,我们只需要关心需要多少内存以及还剩多少内存可以分配,但USM需要更多的信息。首先需要知道指定哪种类型的分配;其次需要指定一个context上下文对象,上下文代表一个或一组设备,可以在上面执行kernel,USM分配不保证可以在不同的上下文中使用;最后,设备分配要求我们指定在哪个设备上分配内存。
USM提供了不同风格的语法,我们接下来简单讨论一下。
C风格内存分配
主要使用malloc函数,可以使用两种风格:命名函数和单一函数。命名函数有malloc_device、malloc_host和malloc_shared,单一函数则需要malloc附加参数。此外,每个malloc都有一个aligned_alloc的对应函数,可以返回对齐的内存指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// Named Functions
void *malloc_device(size_t size, const device &dev, const context &ctxt);
void *malloc_device(size_t size, const queue &q);
void *aligned_alloc_device(size_t alignment, size_t size,
const device &dev, const context &ctxt);
void *aligned_alloc_device(size_t alignment, size_t size, const queue &q);
void *malloc_host(size_t size, const context &ctxt);
void *malloc_host(size_t size, const queue &q);
void *aligned_alloc_host(size_t alignment, size_t size, const context &ctxt);
void *aligned_alloc_host(size_t alignment, size_t size, const queue &q);
void *malloc_shared(size_t size, const device &dev, const context &ctxt);
void *malloc_shared(size_t size, const queue &q);
void *aligned_alloc_shared(size_t alignment, size_t size,
const device &dev, const context &ctxt);
void *aligned_alloc_shared(size_t alignment, size_t size, const queue &q);
// Single Function
void *malloc(size_t size, const device &dev, const context &ctxt,
usm::alloc kind);
void *malloc(size_t size, const queue &q, usm::alloc kind);
void *aligned_alloc(size_t alignment, size_t size,
const device &dev, const context &ctxt,
usm::alloc kind);
void *aligned_alloc(size_t alignment, size_t size, const queue &q,
usm::alloc kind);
C++风格内存分配
我们同样有命名和单一函数版本的分配函数,以及默认和对齐的函数。不过在C++风格中,我们可以使用模板。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// Named Functions
template <typename T>
T *malloc_device(size_t Count, const device &Dev, const context &Ctxt);
template <typename T>
T *malloc_device(size_t Count, const queue &Q);
template <typename T>
T *aligned_alloc_device(size_t Alignment, size_t Count, const device &Dev,
const context &Ctxt);
T *aligned_alloc_device(size_t Alignment, size_t Count, const queue &Q);
template <typename T>
T *malloc_host(size_t Count, const context &Ctxt);
template <typename T>
T *malloc_host(size_t Count, const queue &Q);
template <typename T>
T *aligned_alloc_host(size_t Alignment, size_t Count, const context &Ctxt);
template <typename T>
T *aligned_alloc_host(size_t Alignment, size_t Count, const queue &Q);
template <typename T>
T *malloc_shared(size_t Count, const device &Dev, const context &Ctxt);
template <typename T>
T *malloc_shared(size_t Count, const queue &Q);
template <typename T>
T *aligned_alloc_shared(size_t Alignment, size_t Count, const device &Dev,
const context &Ctxt);
template <typename T>
T *aligned_alloc_shared(size_t Alignment, size_t Count, const queue &Q);
// Single Function
template <typename T>
T *malloc(size_t Count, const device &Dev, const context &Ctxt,
usm::alloc Kind);
template <typename T>
T *malloc(size_t Count, const queue &Q, usm::alloc Kind);
template <typename T>
T *aligned_alloc(size_t Alignment, size_t Count, const device &Dev,
const context &Ctxt, usm::alloc Kind);
template <typename T>
T *aligned_alloc(size_t Alignment, size_t Count, const queue &Q,
usm::alloc Kind);
C++分配器
这种方式基于C++的分配器接口,如果代码大量使用容器的话,这种方式是最方便的。
内存释放
USM定义了一个free函数来释放由malloc或aligned_malloc分配的内存,也可以接受上下文作为一个额外的参数。如果是用C++分配器对象分配的,也应该用该对象的方法来释放内存。
数据管理
数据初始化
有各种方式可以对一段内存空间进行初始化。首先可以通过一个kernel来完成;我们也可以通过主机代码中的一个循环来实现,不过无法访问设备内存;最后我们也可以使用memset函数,往内存中填充字节,USM还提供了类似的fill函数,让我们可以用一个任意的模式来填充内存
数据移动
USM定义了两种我们可以用来管理数据的策略:显式和隐式。我们哪种策略与硬件支持的或USM分配类型有关。
显式数据移动可以通过调用memcpy函数在主机和设备之间复制数据。
隐式数据移动则不需要我们手动干预,主要涉及到USM共享分配,但也涉及到一些问题,如主机和设备不应该试图在同一时间访问共享分配内存、分配受到设备内存的限制、影响性能等。当设备支持共享分配的按需迁移时,数据移动可能会提前完成,但kernel在等待数据移动完成之前可能会停顿。DPC++提供了方法来修改自动迁移机制,主要由两个函数prefetch和mem_advise,具体的细节比较复杂,应该参考文档。
查询
不是所有的设备都支持USM的所有功能,我们可以查询一个设备是否支持某些功能,包括指针查询和设备能力查询。指针查询可以回答两个问题,使用get_pointer_type函数可以查询指针指向什么类型的USM分配,使用get_pointer_device函数可以查询USM指针是针对什么设备分配的;设备能力查询可以通过调用设备对象的get_info来测试一个设备支持哪些类型的USM分配。
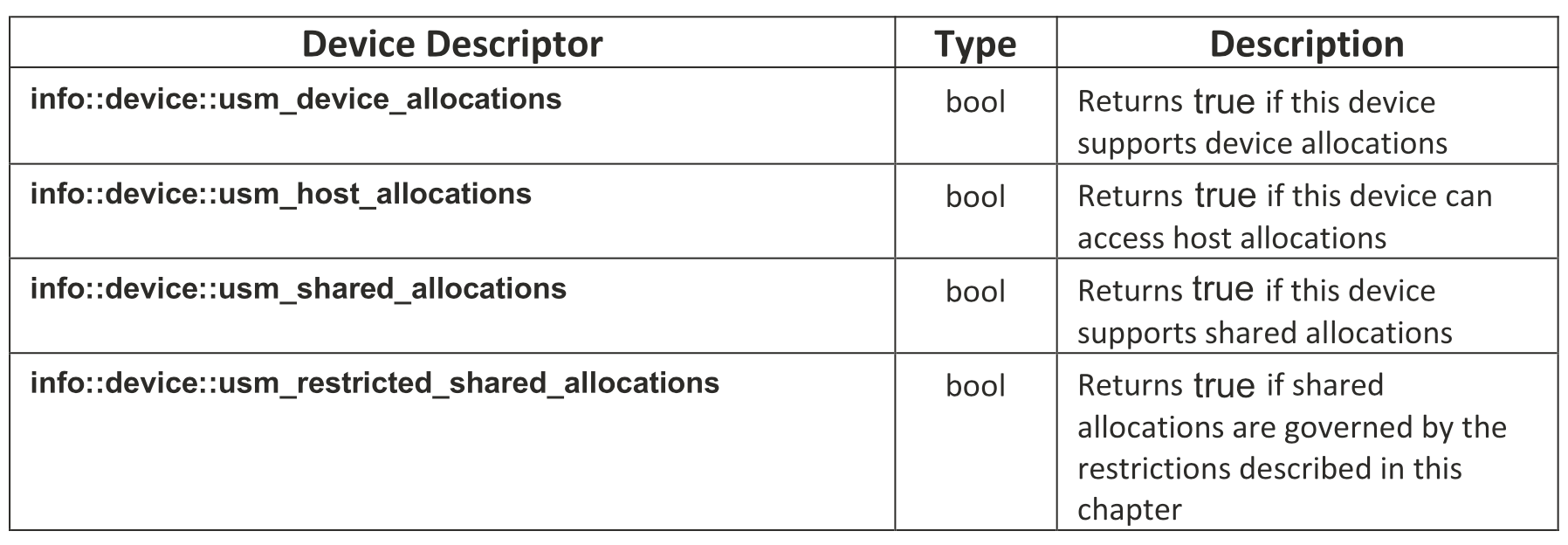 USM设备信息描述符
USM设备信息描述符
缓冲区
缓冲区是一个更高层次的抽象,本身只代表数据,而如何管理数据(包括如何存储以及移动)则是运行时的工作。我们接下来讨论如何创建和使用缓冲区,以及accessor对象的概念。
缓冲区的创建和使用
1
2
template <typename T, int Dimensions, AllocatorT allocator>
class buffer;
创建
我们在下面的代码中展示了几种创建缓冲区对象的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Create a buffer of 2x5 ints using the default allocator
buffer<int, 2, buffer_allocator> b1{range<2>{2, 5}};
// Create a buffer of 2x5 ints using the default allocator
// and CTAD for range
buffer<int, 2> b2{range{2, 5}};
// Create a buffer of 20 floats using a
// default-constructed std::allocator
buffer<float, 1, std::allocator<float>> b3{range{20}};
// Create a buffer of 20 floats using a passed-in allocator
std::allocator<float> myFloatAlloc;
buffer<float, 1, std::allocator<float>> b4{range(20), myFloatAlloc};
注意在b2缓冲区的创建中我们使用了C++ 17引入的模板类参数推断(class template argument deduction, CTAD)功能,省略了range<2>{2, 5}中的<2>,因为我们可以推断出这是一个二维的范围。
我们也可以使用现有的C++内存分配来创建缓冲区,并且在这种方式中可以初始化其中的数据。
1
2
3
4
5
6
7
8
9
10
11
12
// Create a buffer of 4 doubles and initialize it from a host pointer
double myDoubles[4] = {1.1, 2.2, 3.3, 4.4};
buffer b5{myDoubles, range{4}};
// Create a buffer of 5 doubles and initialize it from a host pointer
// to const double
const double myConstDbls[5] = {1.0, 2.0, 3.0, 4.0, 5.0};
buffer b6{myConstDbls, range{5}};
// Create a buffer from a shared pointer to int
auto sharedPtr = std::make_shared<int>(42);
buffer b7{sharedPtr, range{1}};
最后,我们可以使用C++容器来创建缓冲区,可以通过一个缓冲区创建一个子缓冲区。
1
2
3
4
5
6
7
8
9
10
// Create a buffer of ints from an input iterator
std::vector<int> myVec;
buffer b8{myVec.begin(), myVec.end()};
buffer b9{myVec};
// Create a buffer of 2x5 ints and 2 non-overlapping
// sub-buffers of 5 ints.
buffer<int, 2> b10{range{2, 5}};
buffer b11{b10, id{0, 0}, range{1, 5}};
buffer b12{b10, id{1, 0}, range{1, 5}};
使用
我们不能直接访问缓冲区的数据,只能使用accessor,我们会在之后进一步讨论这一点。不过我们仍然可以访问缓冲区的一些特性,比如可以查询缓冲区的大小、分配器对象、是否是子缓冲区等。
Accessor
accessor对象由accessor类创建,有五个模板参数,分别为访问数据的类型、维度、访问模式、访问目标、是否为placeholder。
 访问模式
访问模式
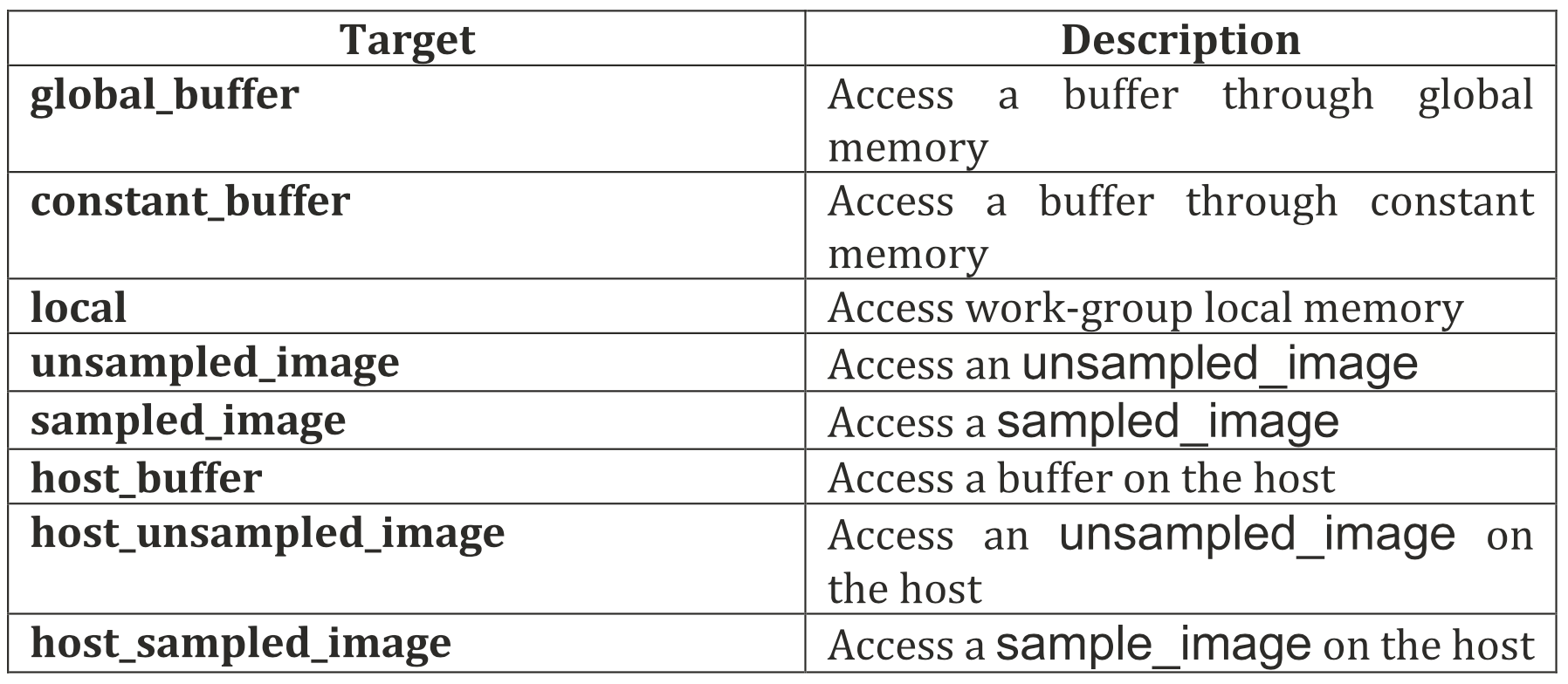 访问目标
访问目标
创建
下面的例子展示了如何创建并使用accessor。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <cassert>
#include <CL/sycl.hpp>
using namespace sycl;
constexpr int N = 42;
int main() {
queue Q;
// create 3 buffers of 42 ints
buffer<int> A{range{N}};
buffer<int> B{range{N}};
buffer<int> C{range{N}};
accessor pC{C};
Q.submit([&](handler &h) {
accessor aA{A, h};
accessor aB{B, h};
accessor aC{C, h};
h.parallel_for(N, [=](id<1> i) {
aA[i] = 1;
aB[i] = 40;
aC[i] = 0;
});
});
Q.submit([&](handler &h) {
accessor aA{A, h};
accessor aB{B, h};
accessor aC{C, h};
h.parallel_for(N, [=](id<1> i) { aC[i] += aA[i] + aB[i]; });
});
Q.submit([&](handler &h) {
h.require(pC);
h.parallel_for(N, [=](id<1> i) { pC[i]++; });
});
host_accessor result{C};
for (int i = 0; i < N; i++) {
assert(result[i] == N);
}
return 0;
}
我们介绍一个工具,叫做访问标记(access tag),这是一种简洁的可以表达访问模式和目标组合的方式,作为参数传递给accessor的构造函数,可能的标记如下所示,C++ CTAD可以正确推断出所需的访问模式和目标。
 访问标记
访问标记
修改后的程序如下所示。注意还有一个新参数叫noinit,运行时可以知道缓冲区之前的内容可以被直接丢弃,因而可以消除不必要的数据移动。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
#include <CL/sycl.hpp>
#include <cassert>
using namespace sycl;
constexpr int N = 42;
int main() {
queue Q;
// Create 3 buffers of 42 ints
buffer<int> A{range{N}};
buffer<int> B{range{N}};
buffer<int> C{range{N}};
accessor pC{C};
Q.submit([&](handler &h) {
accessor aA{A, h, write_only, no_init};
accessor aB{B, h, write_only, no_init};
accessor aC{C, h, write_only, no_init};
h.parallel_for(N, [=](id<1> i) {
aA[i] = 1;
aB[i] = 40;
aC[i] = 0;
});
});
Q.submit([&](handler &h) {
accessor aA{A, h, read_only};
accessor aB{B, h, read_only};
accessor aC{C, h, read_write};
h.parallel_for(N, [=](id<1> i) { aC[i] += aA[i] + aB[i]; });
});
Q.submit([&](handler &h) {
h.require(pC);
h.parallel_for(N, [=](id<1> i) { pC[i]++; });
});
host_accessor result{C, read_only};
for (int i = 0; i < N; i++) {
assert(result[i] == N);
}
return 0;
}
使用
之前我们提到,accessor最重要的功能是让我们可以访问数据,通常是通过[]操作符来完成的。accessor可以返回一个指向底层数据的指针,也可以查询访问的元素的数量、数据范围等。