在前一节中我们简单介绍了主机与设备代码、数据管理与移动等基本概念,这一节我们进一步深入讨论如何处理、开发代码以充分挖掘程序中的并行性。
表达并行性
并行编程往往很有挑战性,且我们会有如下一些问题:
为什么有不止一种方法来表达并行性?
我们应该使用哪种方法来表达并行性?
我需要了解多少关于执行模型的概念?
Kernel内的并行性
Kernel开发应该保证可移植性,也就是说并行性不应该被硬编码以适应不同的硬件系统(如GPU、SIMD单元等),但可移植性可能也会牺牲性能。在应用程序开发过程中,在性能、可移植性和生产力之间取得适当的平衡是我们必须面对的挑战。需要关注的两个概念是多维kernel以及kernel与loop之间的区别。
SYCL语言特性
当我们编写一个并行kernel时,我们需要决定使用哪种类型的kernel以及如何在我们的程序中表达。我们在本节中使用lambda表达式来表达kernel。Kernel有三种形式:基本数据并行、ND-range数据并行、分层数据并行。
基本数据并行
基本数据并行kernel是以单程序多数据流(SPMD)的方式编写的,优势在于同一个程序可以被隐式映射到多个级别与并行资源,例如可以被流水线化、打包在一起使用SIMD单元执行、或者分散到多个线程执行等。基本数据并行的执行空间称为执行范围(range),kernel的每一个实例称为一个item,如下图所示。
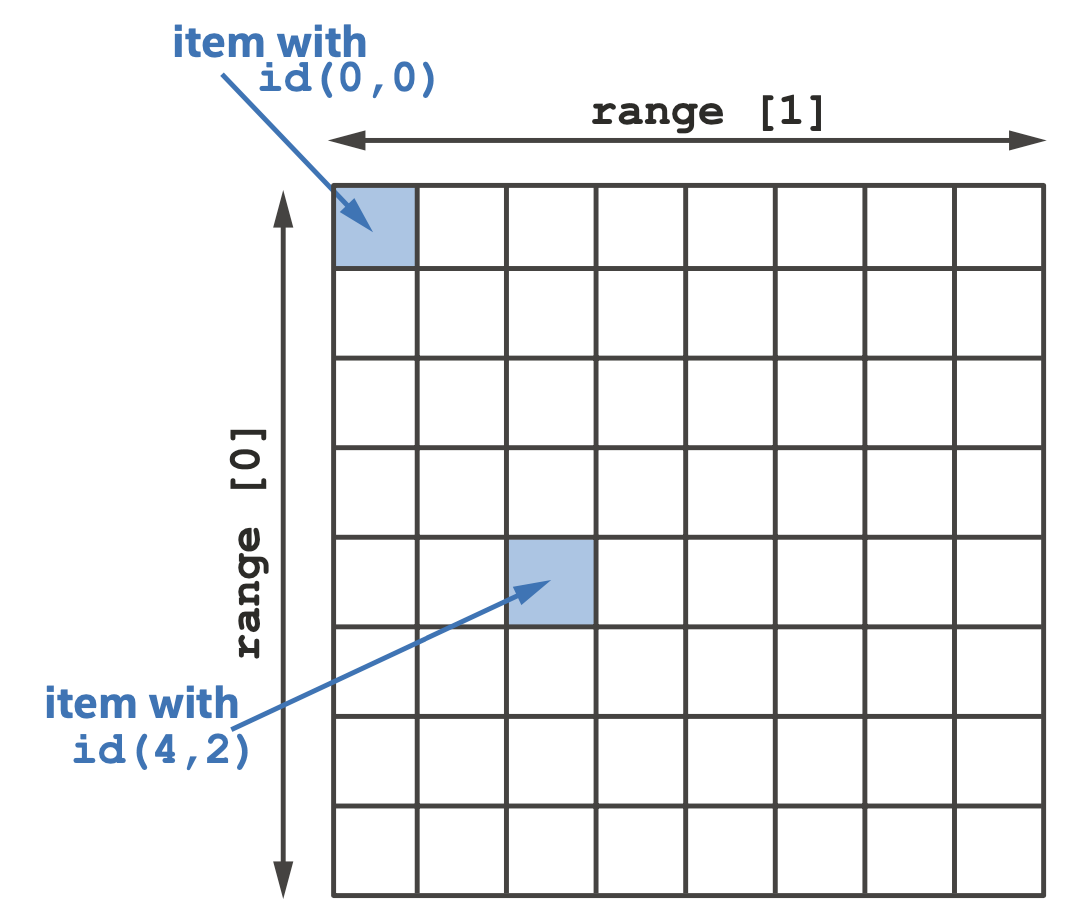 基本数据并行kernel的执行空间
基本数据并行kernel的执行空间
基本的数据并行kernel的功能是通过三个C++类表示的:range、id和item。range表示一个一维、二维或三维的范围,维度需要在编译期确定,但每个维度的大小可以是动态的,下面的代码是range类的简化定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
template <int Dimensions = 1>
class range {
public:
// Construct a range with one, two or three dimensions
range(size_t dim0);
range(size_t dim0, size_t dim1);
range(size_t dim0, size_t dim1, size_t dim2);
// Return the size of the range in a specific dimension
size_t get(int dimension) const;
size_t &operator[](int dimension);
size_t operator[](int dimension) const;
// Return the product of the size of each dimension
size_t size() const;
// Arithmetic operations on ranges are also supported
};
id表示一个一维、二维或三维范围内的索引。尽管我们可以构造一个id来代表一个任意的索引,但为了获得与特定kernel实例相关的索引,我们必须将其作为kernel函数的一个参数。下面的代码是id类的简化定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
template <int Dimensions = 1>
class id {
public:
// Construct an id with one, two or three dimensions
id(size_t dim0);
id(size_t dim0, size_t dim1);
id(size_t dim0, size_t dim1, size_t dim2);
// Return the component of the id in a specific dimension
size_t get(int dimension) const;
size_t &operator[](int dimension);
size_t operator[](int dimension) const;
// Arithmetic operations on ranges are also supported
};
item代表了一个kernel函数的单个实例,同时封装了其执行范围和实例在该范围内的索引。和id的主要区别在于item给出了额外的函数来查询范围与线性化的索引。与id一样,获得与特定kernel实例相关item的唯一方法是作为kernel函数的参数传入。下面的代码是item类的简化定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
template <int Dimensions = 1, bool WithOffset = true>
class item {
public:
// Return the index of this item in the kernel's execution range
id<Dimensions> get_id() const;
size_t get_id(int dimension) const;
size_t operator[](int dimension) const;
// Return the execution range of the kernel executed by this item
range<Dimensions> get_range() const;
size_t get_range(int dimension) const;
// Return the offset of this item (if with_offset == true)
id<Dimensions> get_offset() const;
// Return the linear index of this item
// e.g. id(0) * range(1) * range(2) + id(1) * range(2) + id(2)
size_t get_linear_id() const;
};
ND-range数据并行
这种类型同样适用SPMD风格编写,不过引入了组的概念。一个ND-range kernel的执行范围被划分为work-groups、sub-groups和work-items,sub-group总是一维的,如下图所示。
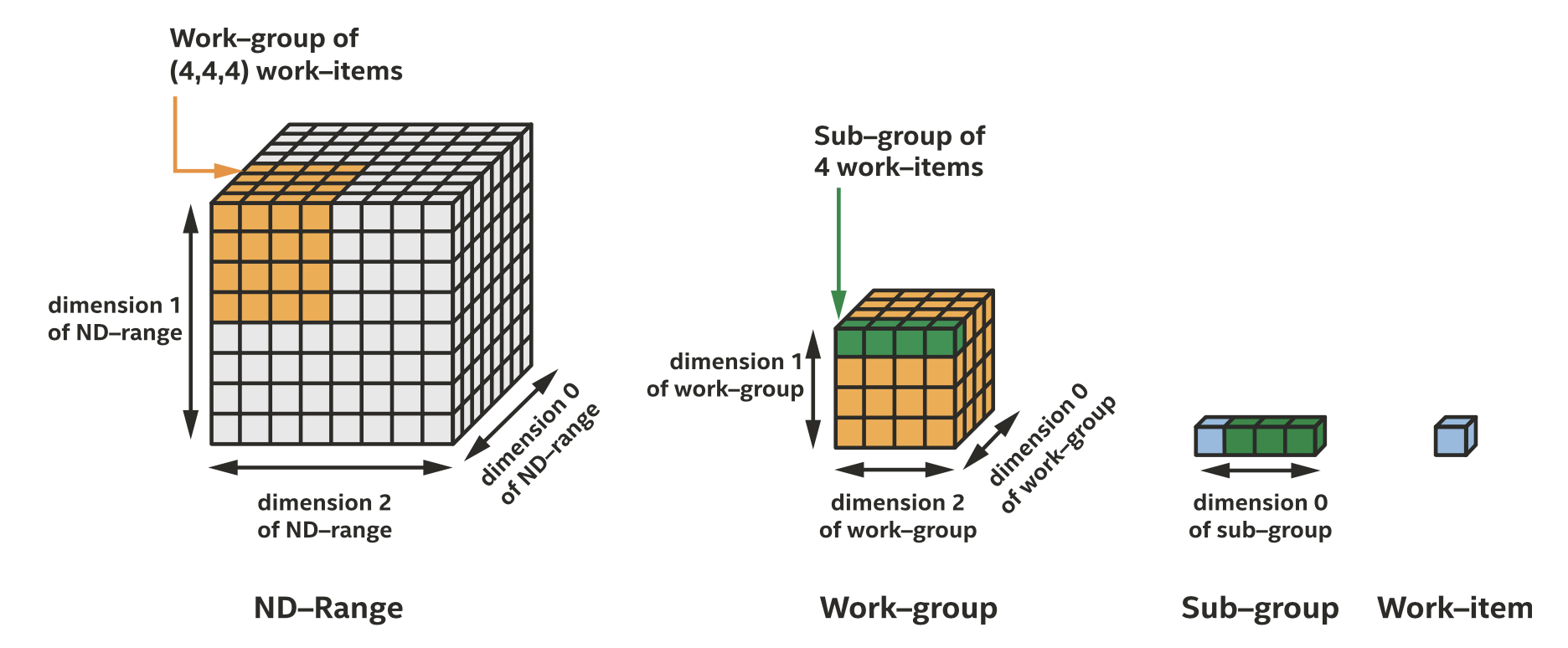 三维ND-range被划分为work-groups、sub-groups和work-items
三维ND-range被划分为work-groups、sub-groups和work-items
每种类型的组到硬件资源的映射是由实现定义的,正是这种灵活性使程序能够在各种各样的硬件上执行。Work-item代表了一个kernel函数的实例,可以按任何顺序执行,除了对全局内存的原子内存操作之外,不能相互通信或同步;Work-group可以按任何顺序执行,work-group内的work-items可以访问work-group本地内存,可以映射到一些设备上的本地存储器,可以使用work-group barriers进行同步,使用work-group内存fences保证内存一致性,可以访问groupo函数;Sub-group可以进一步进行局部的调度,例如可以使用编译器向量化的功能使sub-group内的work-item并行执行,sub-group内的work-item可以进行同步,但没有自己的本地内存,但可以使用shuffle操作直接交换数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// Create buffers associated with inputs and output
buffer<float, 2> a_buf(a.data(), range<2>(N, N)),
b_buf(b.data(), range<2>(N, N)), c_buf(c.data(), range<2>(N, N));
// Submit the kernel to the queue
Q.submit([&](handler& h) {
accessor a{a_buf, h};
accessor b{b_buf, h};
accessor c{c_buf, h};
range global{N, N};
range local{B, B};
h.parallel_for(nd_range{global, local}, [=](nd_item<2> it) {
int j = it.get_global_id(0);
int i = it.get_global_id(1);
for (int k = 0; k < N; ++k) {
c[j][i] += a[j][k] * b[k][i];
}
});
});
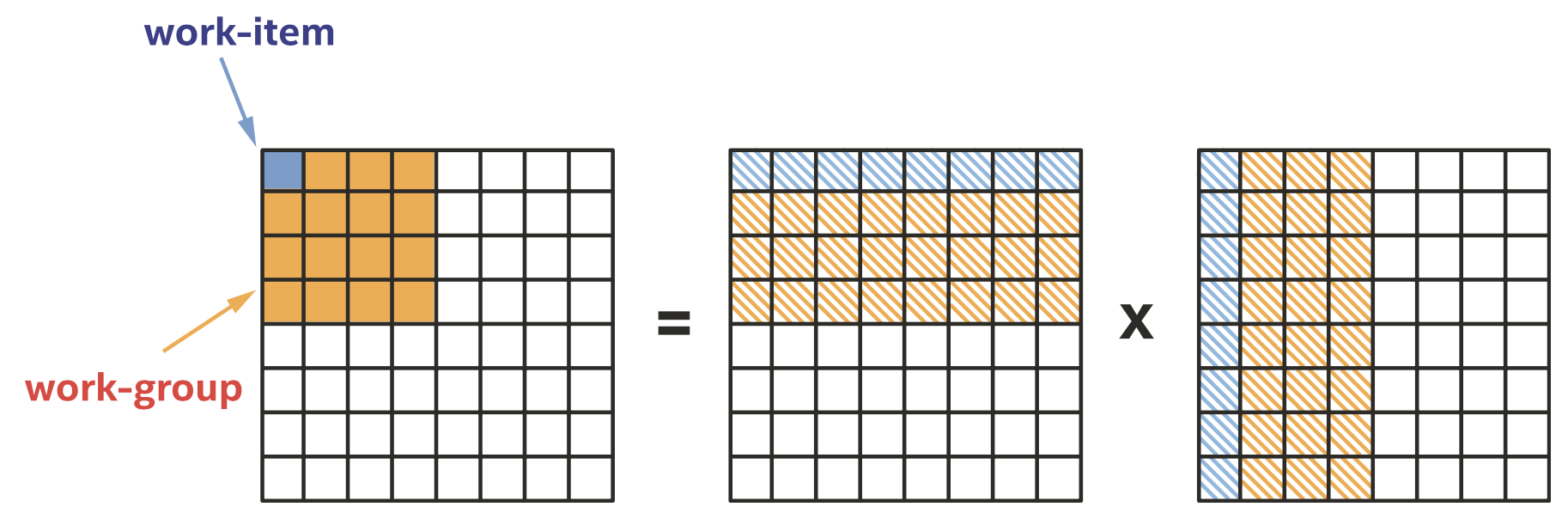 将矩阵乘法映射到work-groups和work-items
将矩阵乘法映射到work-groups和work-items
和基本数据并行kernel相比,ND-range数据并行kernel使用了不同的类。nd_range类表示一个分组的执行范围,构造函数的参数是两个range类的实例,第一个表示全局执行范围,第二个表示每个work-group的局部执行范围。下面的代码是nd_range类的简化定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
template <int Dimensions = 1>
class nd_range {
public:
// Construct an nd_range from global and work-group local ranges
nd_range(range<Dimensions> global, range<Dimensions> local);
// Return the global and work-group local ranges
range<Dimensions> get_global_range() const;
range<Dimensions> get_local_range() const;
// Return the number of work-groups in the global range
range<Dimensions> get_group_range() const;
};
nd_item类似于item,不同之处在于范围内的查询和表示方式。下面的代码是nd_item类的简化定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
template <int Dimensions = 1>
class nd_item {
public:
// Return the index of this item in the kernel's execution range
id<Dimensions> get_global_id() const;
size_t get_global_id(int dimension) const;
size_t get_global_linear_id() const;
// Return the execution range of the kernel executed by this item
range<Dimensions> get_global_range() const;
size_t get_global_range(int dimension) const;
// Return the index of this item within its parent work-group
id<Dimensions> get_local_id() const;
size_t get_local_id(int dimension) const;
size_t get_local_linear_id() const;
// Return the execution range of this item's parent work-group
range<Dimensions> get_local_range() const;
size_t get_local_range(int dimension) const;
// Return a handle to the work-group
// or sub-group containing this item
group<Dimensions> get_group() const;
sub_group get_sub_group() const;
};
group类封装了有关work-group的功能,简化的代码如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template <int Dimensions = 1>
class group {
public:
// Return the index of this group in the kernel's execution range
id<Dimensions> get_id() const;
size_t get_id(int dimension) const;
size_t get_linear_id() const;
// Return the number of groups in the kernel's execution range
range<Dimensions> get_group_range() const;
size_t get_group_range(int dimension) const;
// Return the number of work-items in this group
range<Dimensions> get_local_range() const;
size_t get_local_range(int dimension) const;
};
sub_group类封装了有关sub-group的功能,简化的代码如下所示。注意sub_group类是访问sub-group的唯一途径。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class sub_group {
public:
// Return the index of the sub-group
id<1> get_group_id() const;
// Return the number of sub-groups in this item's parent work-group
range<1> get_group_range() const;
// Return the index of the work-item in this sub-group
id<1> get_local_id() const;
// Return the number of work-items in this sub-group
range<1> get_local_range() const;
// Return the maximum number of work-items in any
// sub-group in this item's parent work-group
range<1> get_max_local_range() const;
};
分层数据并行
分层数据并行kernel提供了一种实验性的替代语法,通过work-groups和work-itmes来表达kernel,但使用嵌套调用的parallel_for函数,其复杂性在于parallel_for每次嵌套调用都会创建一个单独的SPMD环境。在分层数据并行kernel中,parallel_for函数被paralle_for_work_group和parallel_for_work_item函数取代。
具体的实现细节与示例代码可以参考原书。
在不同kernel形式之间选择主要是个人偏好的问题,同时也会影响如何表达所需的某些功能。具体如何选择kernel的形式可以参考下图。
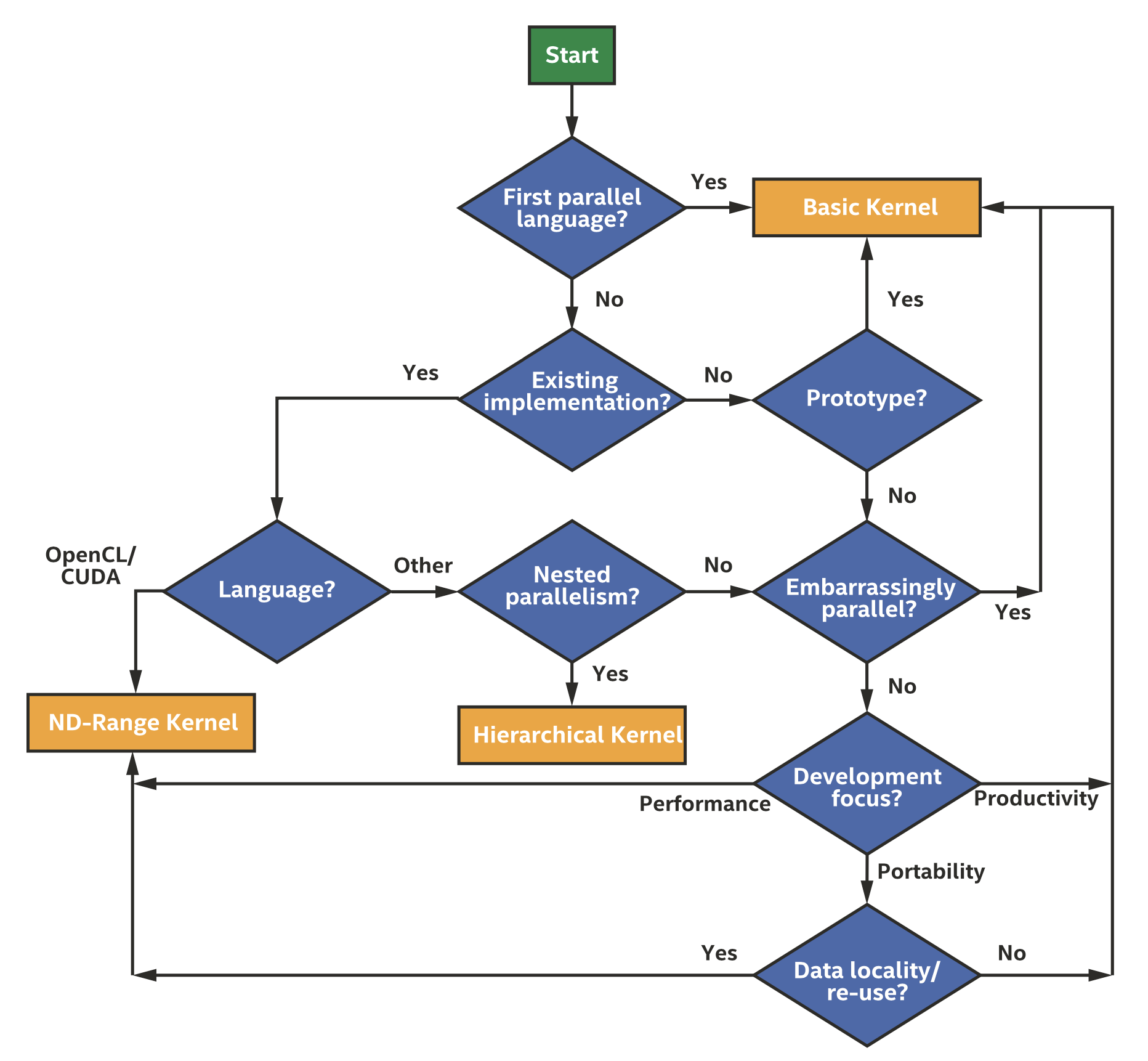 选择合适的kernel形式
选择合适的kernel形式
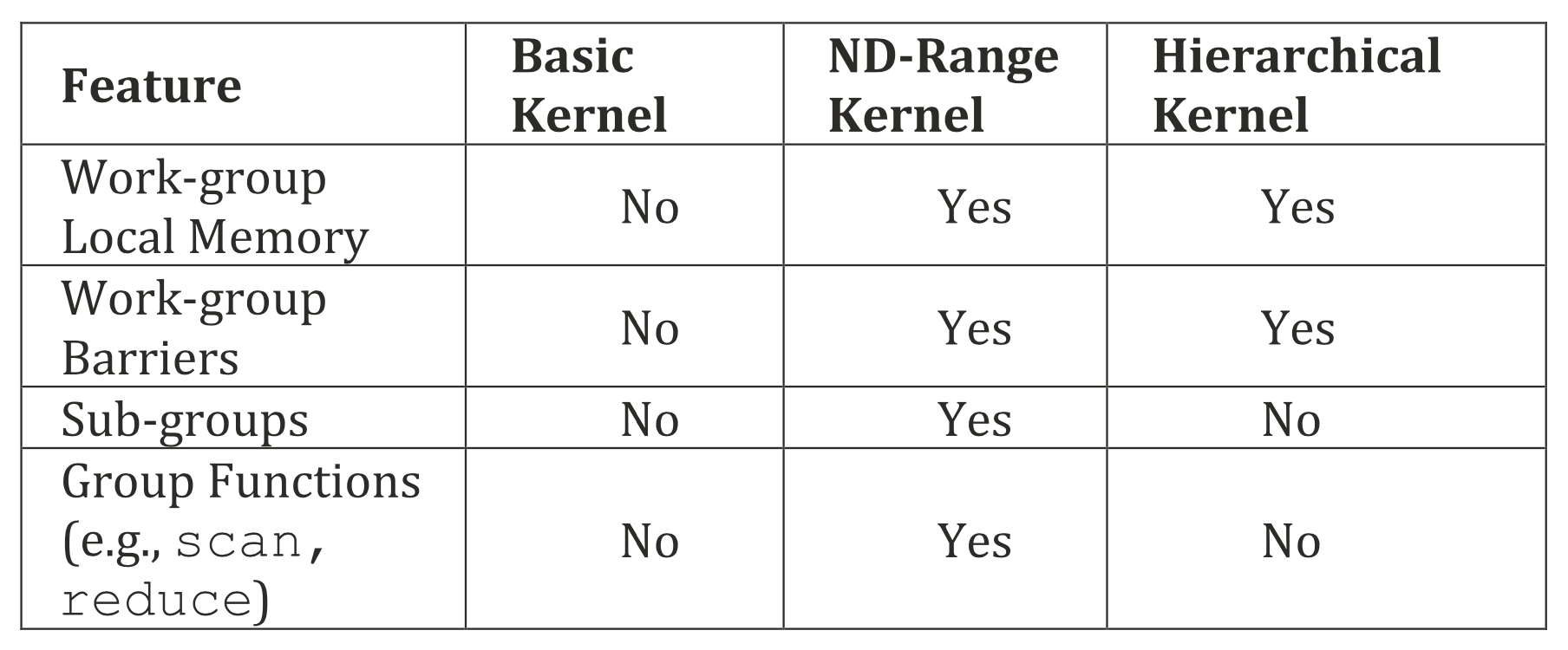 每种kernel形式的特性
每种kernel形式的特性