《数据并行C++》原书英文名为Data Parallel C++,可以在这里下载pdf。
入门
数据并行性让我们有机会可以利用异构系统中的并行资源来对计算进行加速,如使用CPU中的SIMD单元、GPU、FPGA或者其他ASIC加速器。SYCL是一个行业驱动的标准,不过SYCL只是一个名字,不是什么缩写。DPC++是一个开源的编译器项目,基于LLVM,由Intel发起,是SYCL的一种实现。
搭建环境和使用DPC++编译器可以参考这篇文档,本书用到的示例代码在这里,SYCL语言标准可以参考这里,DPC++编译器的文档可以参考这里。
DPC++与SYCL的一些概念
SYCL程序可以是单源的,也就是说compute kernel的代码和协调这些kernel执行的主机代码可以放在同一个源文件中。
每个程序从主机上开始执行,主机通常是一个CPU。
在一个程序中使用多个设备才叫做异构编程,设备可以包括GPU、FPGA、DSP、ASIC、CPU、AI加速器等。
多个程序可以共享设备。
一个设备执行的代码叫做kernel,kernel代码通常不支持的功能包括动态内存分配、静态变量、函数指针、调用virtual成员函数、递归等。
任务通过队列传输给设备,主机程序不需要等待,这种模式称为异步编程,程序可以看作是一个异步任务图。
代码在哪执行
本章描述了代码可以在哪里执行、何时执行、以及用于控制执行位置的机制。
单源
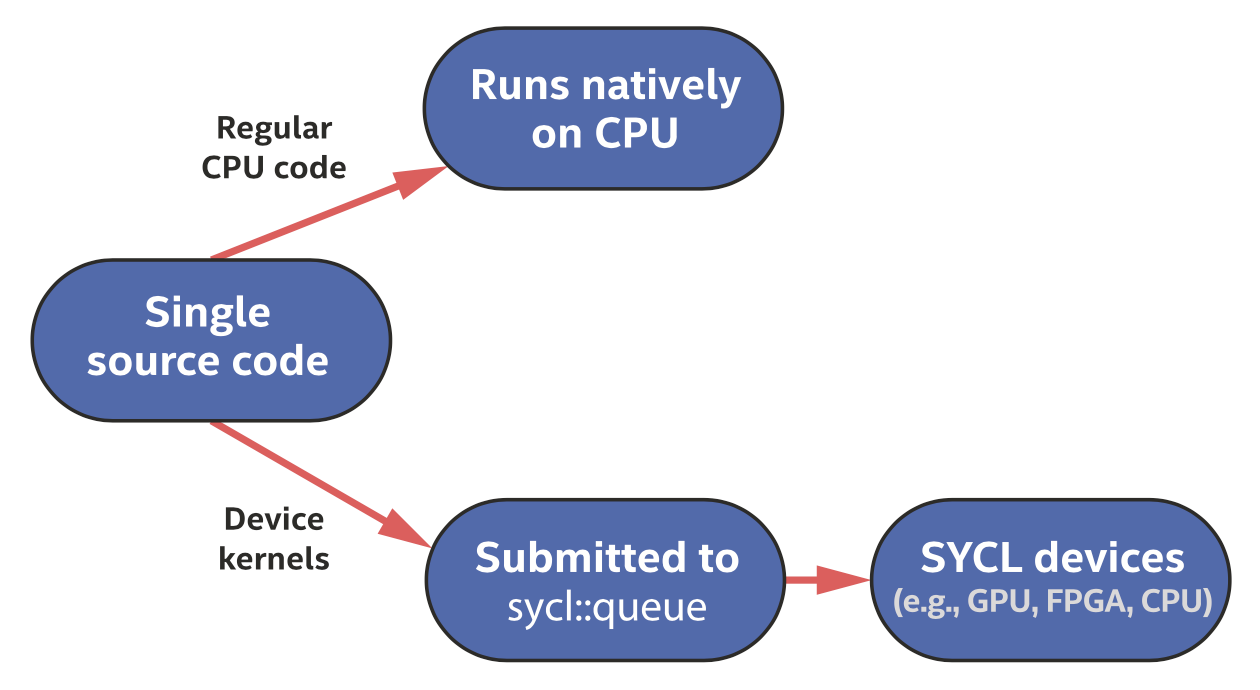 单源代码同时包含主机代码和设备代码
单源代码同时包含主机代码和设备代码
 简单的SYCL程序
简单的SYCL程序
主机代码是一个应用程序的骨干,定义并控制对可用设备的工作分配,并在运行时管理数据和依赖关系。主机通过队列的机制将任务提交给设备,设备代码有一些重要性质:设备代码异步执行(所有依赖满足之后就会开始工作,不阻塞主机代码执行)、设备代码有一些限制(如有时不支持动态内存分配)、SYCL定义的一些函数和查询功能只能在设备代码中使用。我们把包含了设备代码的、提交给队列的任务称为动作(actions),动作不仅包括设备代码的执行,也包括了内存数据移动。
选择执行代码的设备
方法1:在任何类型的设备上运行
当我们不关心我们的设备代码将在哪里运行时,我们可以直接让运行时系统进行选择。我们在讨论选择什么样的设备之前,先介绍程序和设备互动的机制,也就是队列。一个队列被绑定到一个单一的设备上,绑定的过程发生在构造函数中,如下图所示。
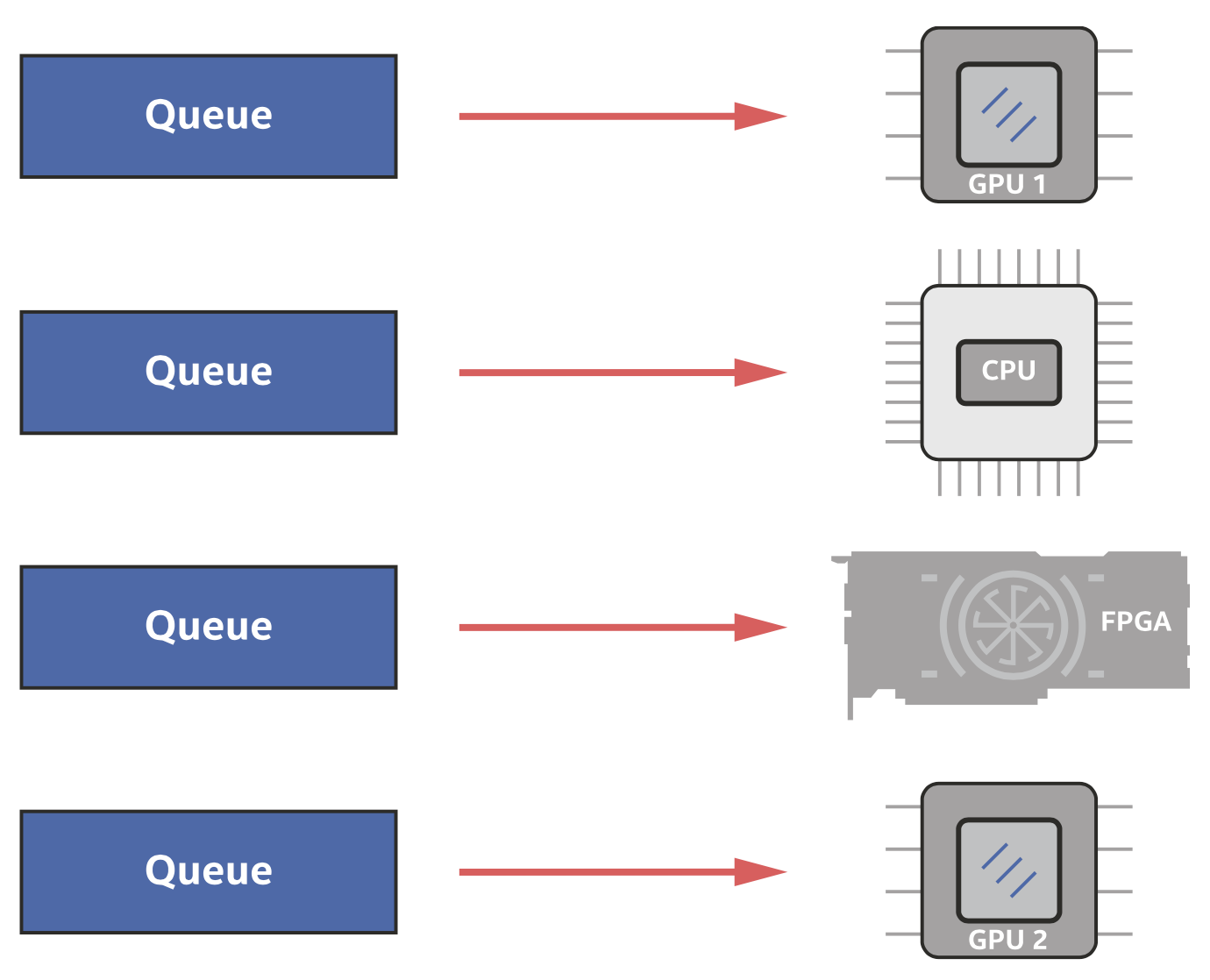 一个队列绑定到一个单一的设备
一个队列绑定到一个单一的设备
可以在一个程序中创建多个队列,多个不同的队列也可以绑定到一个设备(如GPU)上,提交到不同的队列将导致在设备上进行合并的工作。
如果没有指定队列应该绑定的设备,就会在运行时选择可用的设备,SYCL保证至少有一个设备总是可用的,即主机设备本身。
方法2:使用主机设备进行开发和调试
主机设备提供了一个保证,即设备代码总是可以被运行(不依赖加速器硬件),并有几个主要用途,如在没有加速器的系统上开发设备代码、用非加速器工具对设备代码进行调试、作为备份等。
方法3:使用GPU(或者其他加速器)
设备被分为几个大类:主机设备、加速器设备,加速器又可以分为CPU设备、GPU设备、以及其他加速器(包括FPGA、DSP等)。SYCL为这些大类提供了内置的选择器类,包括default_selector、host_selector、cpu_selector、gpu_selector、accelerator_selector,DPC++在CL/sycl/intel/fpga_extensions.hpp提供了一个额外的选择器INTEL::fpga_selector。
使用多个设备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <CL/sycl.hpp>
#include <sycl/ext/intel/fpga_extensions.hpp> // For fpga_selector
#include <iostream>
using namespace sycl;
int main() {
queue my_gpu_queue( gpu_selector{} );
queue my_fpga_queue( ext::intel::fpga_selector{} );
std::cout << "Selected device 1: " <<
my_gpu_queue.get_device().get_info<info::device::name>() << "\n";
std::cout << "Selected device 2: " <<
my_fpga_queue.get_device().get_info<info::device::name>() << "\n";
return 0;
}
自定义设备选择
我们也可以编写一个自定义的选择器,例如从系统中可用的一组GPU中挑选出一个所需的GPU,选择器派生自device_selector这个抽象类。例如下面的代码负责选择Intel Arria系列的FPGA器件。
1
2
3
4
5
6
7
8
9
10
11
12
13
class my_selector : public device_selector {
public:
int operator()(const device &dev) const override {
if (
dev.get_info<info::device::name>().find("Arria")
!= std::string::npos &&
dev.get_info<info::device::vendor>().find("Intel")
!= std::string::npos) {
return 1;
}
return -1;
}
};
在一个设备上创建工作
应用程序通常包含主机代码和设备代码的组合。有几个类成员允许我们提交设备代码来执行,由于这些工作调度结构是提交设备代码的唯一方法,它们允许我们很容易地将设备代码与主机代码区分开来。本章的其余部分介绍了一些工作调度结构,目的是帮助我们理解和识别设备代码和在主机处理器上原生执行的主机代码之间的划分。
任务图
该图中的每个节点(工作单元)都包含了一个要在设备上执行的动作,最常见的动作是数据并行 设备kernel的调用。
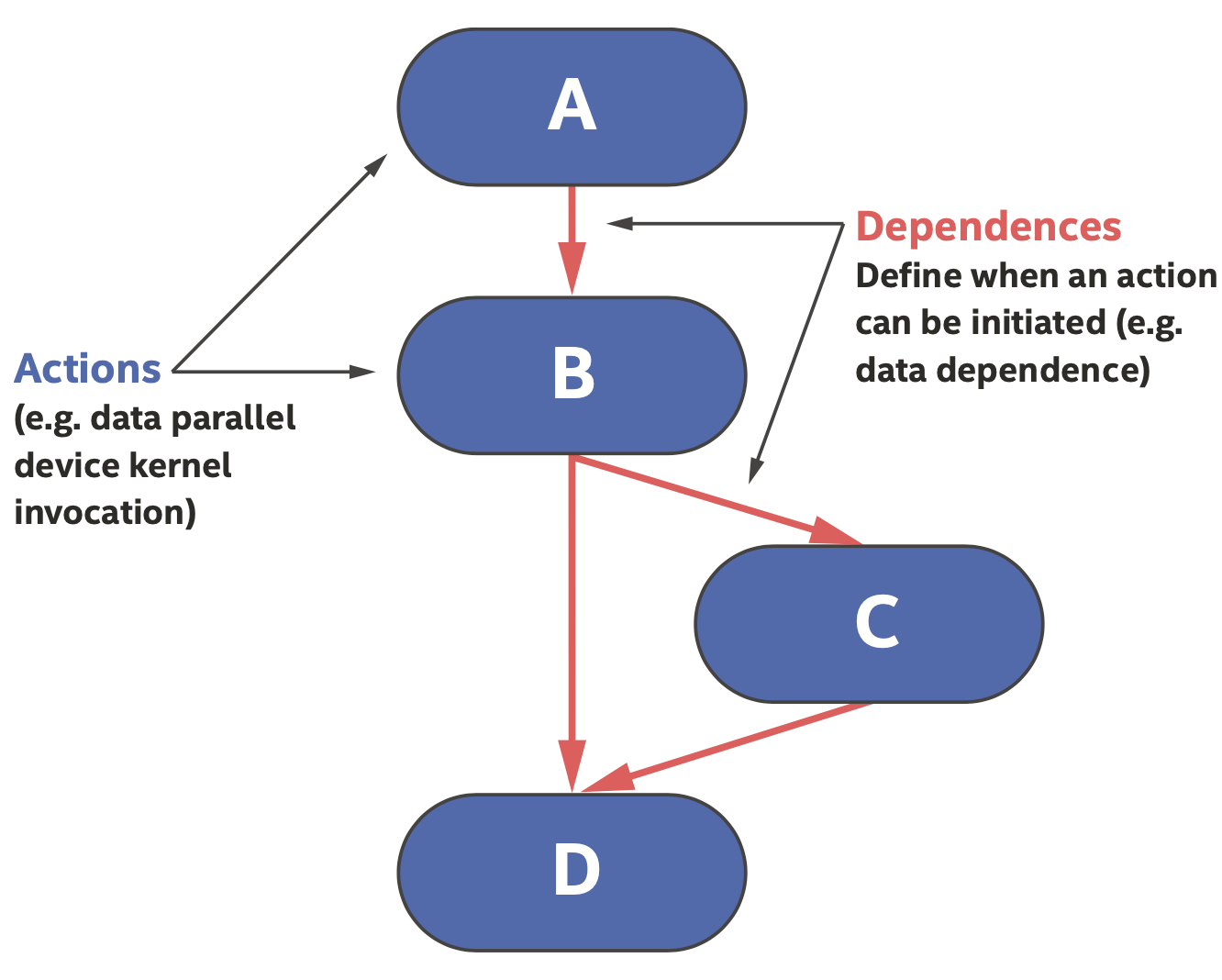 任务图定义了一个或多个设备上异步执行的动作以及动作间的依赖关系
任务图定义了一个或多个设备上异步执行的动作以及动作间的依赖关系
传递设备代码
之前例子中的lambda表达式是要在设备上执行的设备代码,其中parallel_for是让我们区分设备代码和主机代码的结构,是设备调度机制中的一种,且为handler类的成员。下面的代码给出了handler类的一个简化定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
class handler {
public:
// Specify event(s) that must be complete before the action
// defined in this command group executes.
void depends_on(std::vector<event>& events);
// Guarantee that the memory object accessed by the accessor
// is updated on the host after this action executes.
template <typename AccessorT>
void update_host(AccessorT acc);
// Submit a memset operation writing to the specified pointer.
// Return an event representing this operation.
event memset(void *ptr, int value, size_t count);
// Submit a memcpy operation copying from src to dest.
// Return an event representing this operation.
event memcpy(void *dest, const void *src, size_t count);
// Copy to/from an accessor and host memory.
// Accessors are required to have appropriate correct permissions.
// Pointer can be a raw pointer or shared_ptr.
template <typename SrcAccessorT, typename DestPointerT>
void copy(SrcAccessorT src, DestPointerT dest);
template <typename SrcPointerT, typename DestAccessorT>
void copy(SrcPointerT src, DestAccessorT dest);
// Copy between accessors.
// Accessors are required to have appropriate correct permissions.
template <typename SrcAccessorT, typename DestAccessorT>
void copy(SrcAccessorT src, DestAccessorT dest);
// Submit different forms of kernel for execution.
template <typename KernelName, typename KernelType>
void single_task(KernelType kernel);
template <typename KernelName, typename KernelType, int Dims>
void parallel_for(range<Dims> num_work_items,
KernelType kernel);
template <typename KernelName, typename KernelType, int Dims>
void parallel_for(nd_range<Dims> execution_range,
KernelType kernel);
template <typename KernelName, typename KernelType, int Dims>
void parallel_for_work_group(range<Dims> num_groups,
KernelType kernel);
template <typename KernelName, typename KernelType, int Dims>
void parallel_for_work_group(range<Dims> num_groups,
range<Dims> group_size,
KernelType kernel);
};
除了使用handler之外,也有一些queue类的成员函数可以用来提交工作,可以作为简化代码的快捷方式,如下面的代码所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class queue {
public:
// Submit a memset operation writing to the specified pointer.
// Return an event representing this operation.
event memset(void *ptr, int value, size_t count);
// Submit a memcpy operation copying from src to dest.
// Return an event representing this operation.
event memcpy(void *dest, const void *src, size_t count);
// Submit different forms of kernel for execution.
// Return an event representing the kernel operation.
template <typename KernelName, typename KernelType>
event single_task(KernelType kernel);
template <typename KernelName, typename KernelType, int Dims>
event parallel_for(range<Dims> num_work_items,
KernelType kernel);
template <typename KernelName, typename KernelType, int Dims>
event parallel_for(nd_range<Dims> execution_range,
KernelType kernel);
// Submit different forms of kernel for execution.
// Wait for the specified event(s) to complete
// before executing the kernel.
// Return an event representing the kernel operation.
template <typename KernelName, typename KernelType>
event single_task(const std::vector<event>& events,
KernelType kernel);
template <typename KernelName, typename KernelType, int Dims>
event parallel_for(range<Dims> num_work_items,
const std::vector<event>& events,
KernelType kernel);
template <typename KernelName, typename KernelType, int Dims>
event parallel_for(nd_range<Dims> execution_range,
const std::vector<event>& events,
KernelType kernel);
};
动作
之前提到的parallel_for定义了要在一个设备上执行的工作,parallel_for属于提交到一个队列的命令组(command group, CG),在命令组中,由两类代码:动作调用(等待队列执行设备代码或进行手动内存操作)与主机代码(负责设置依赖关系),具体如下图所示。
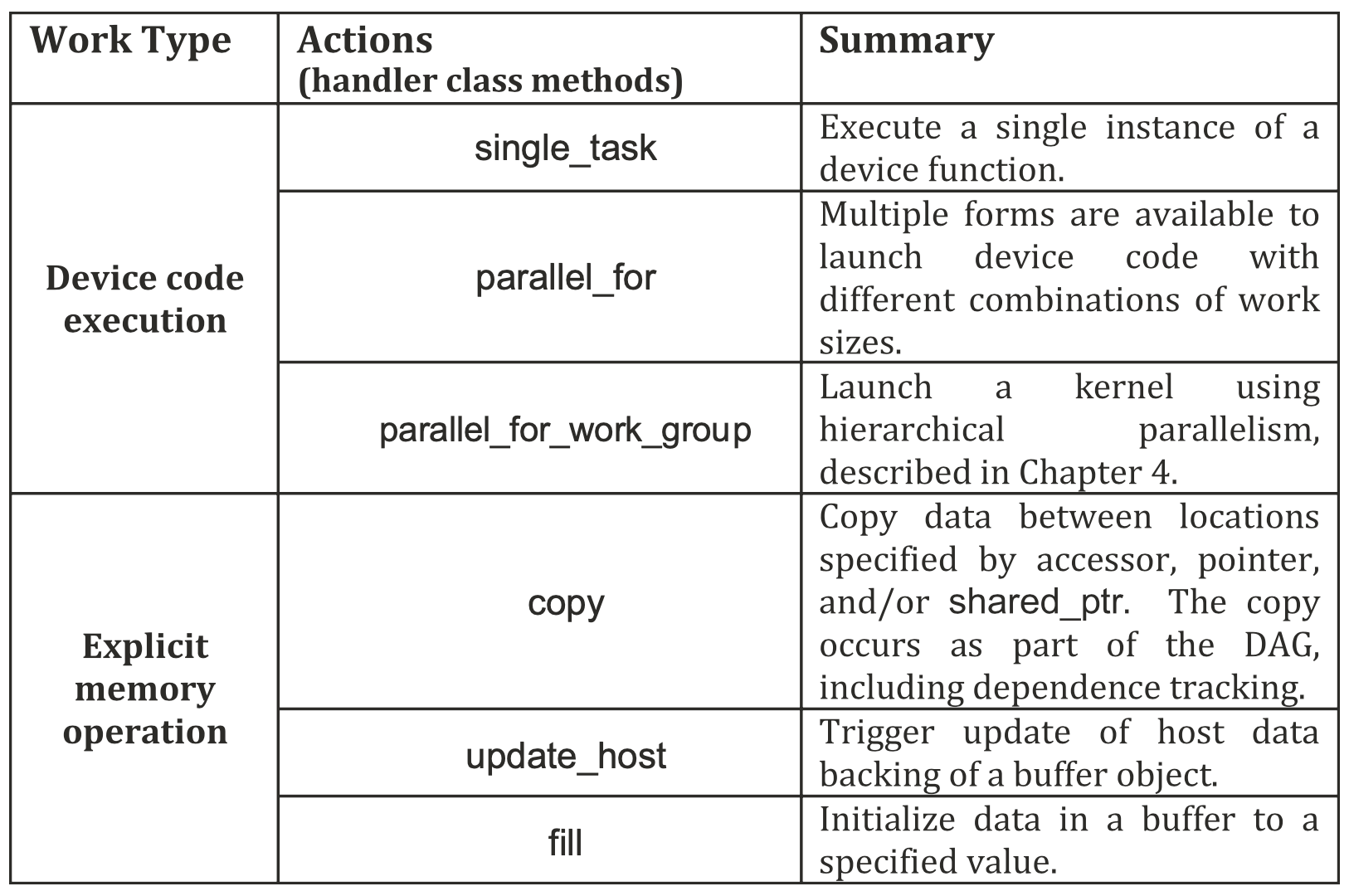 调用设备代码或进行内存操作的动作
调用设备代码或进行内存操作的动作
一个命令组中只能调用上面的一个动作,且每次提交调用只能向队列提交一个命令组,因而可以生成任务图节点之间的依赖关系。
 提交设备代码
提交设备代码
上图中存在三类代码:主机代码、命令组内的主机代码、动作。
数据管理
有两种方式管理数据:统一共享内存(unified shared memory, USM)和缓冲区,前者基于指针,后者提供了更高层次的抽象。由于我们的代码可能在多个设备上运行,而这些设备不一定共享内存,所以我们需要管理数据移动。即使数据是共享的(如USM),同步和一致性也是我们需要理解和管理的。我们把对加速器内部存储器的访问称为本地访问。对另一个设备的存储器的访问称为远程访问,远程访问往往比本地访问要慢。
管理多个存储器
管理多个存储器可以通过两种方式完成:在程序中显式管理或在运行时隐式管理。前者的优点是可以完全控制数据在不同存储器之间传输的时机,缺点在于这样的过程可能很繁琐且容易出错;后者的优点是数据移动的工作由运行时系统自动完成,可以保证正确性,但缺点就是性能较差。
USM、缓冲区、Images
有三种管理内存的抽象方法:USM、缓冲区、Images。USM基于指针,对程序员比较熟悉;缓冲区有自己的模板类,可以描述一维、二维或三维数组,通过accessor对象进行访问;Images是特殊的缓冲区,提供了专门用于图像处理的额外功能。由于缓冲区和Images的接口基本相同,我们主要关注前两者。
USM
支持USM的设备有一个统一的虚拟地址空间,也就是说任何由主机上的USM动态内存分配函数返回的指针也可以被设备访问。USM定义了三种不同类型的内存分配:设备、主机和共享。所有类型的分配都在主机上进行,三种类型的区别如下图所示。
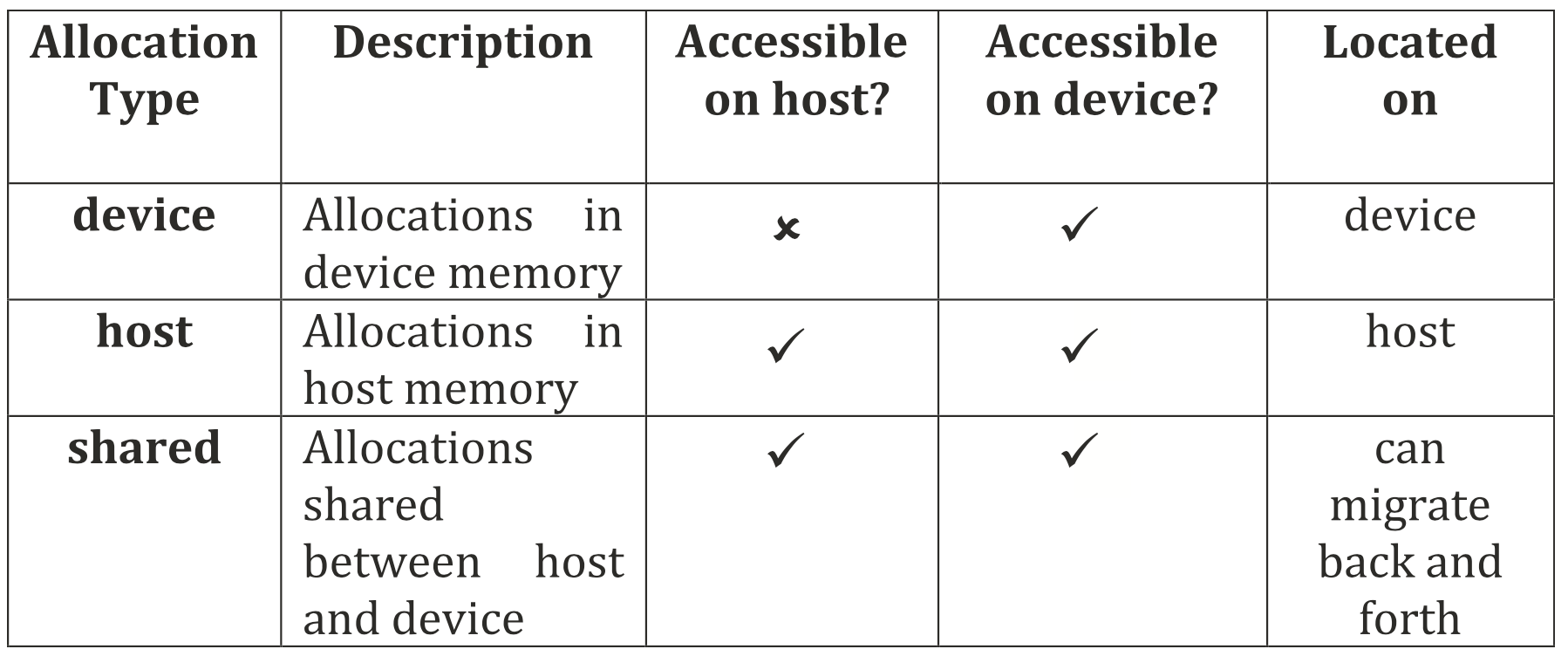 USM内存分配类型
USM内存分配类型
缓冲区
缓冲区是一个数据抽象,代表一个或多个特定C++类型的对象,缓冲区对象的元素可以是标量数据类型(如int、float或double)、向量数据类型,或用户定义的类或struct。缓冲区代表数据对象,而不是具体的内存地址,所以不能像常规的C++数组那样被直接访问,而需要用accessor对象进行访问。
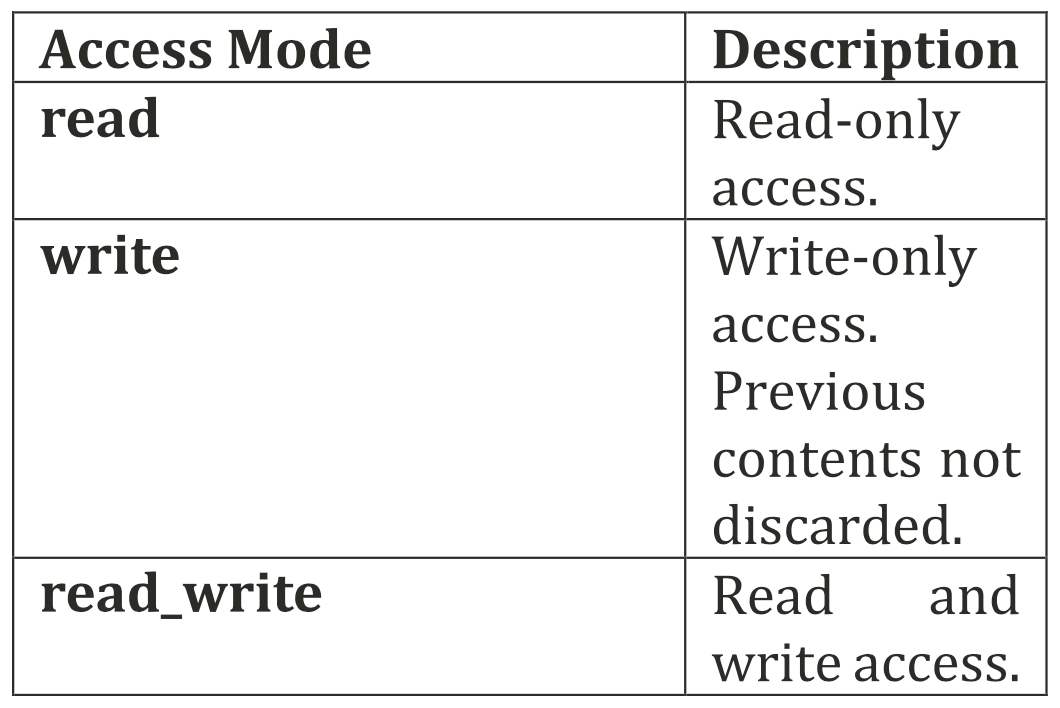 缓冲区访问模式
缓冲区访问模式
在创建accessor时,我们可以告知运行时我们将如何使用缓冲区,以便为优化提供更多信息,默认为read_write。
访问数据的顺序
Kernel可以看作是提交执行的异步任务,任务之间可能存在数据依赖的关系,数据依赖也会产生额外的数据传输。我们把一个程序中的所有任务和它们之间存在的依赖关系可视化为一个图,即任务图,是一个有向无环图(DAG)。任务的完成可以是顺序的,也可以是乱序的。
 顺序队列
顺序队列
队列默认是乱序的,因而必须提供方法来排序提交的任务,我们需要说明任务之间的依赖关系来进行排序,这些依赖关系可以使用命令组(CG)显式或隐式定义。
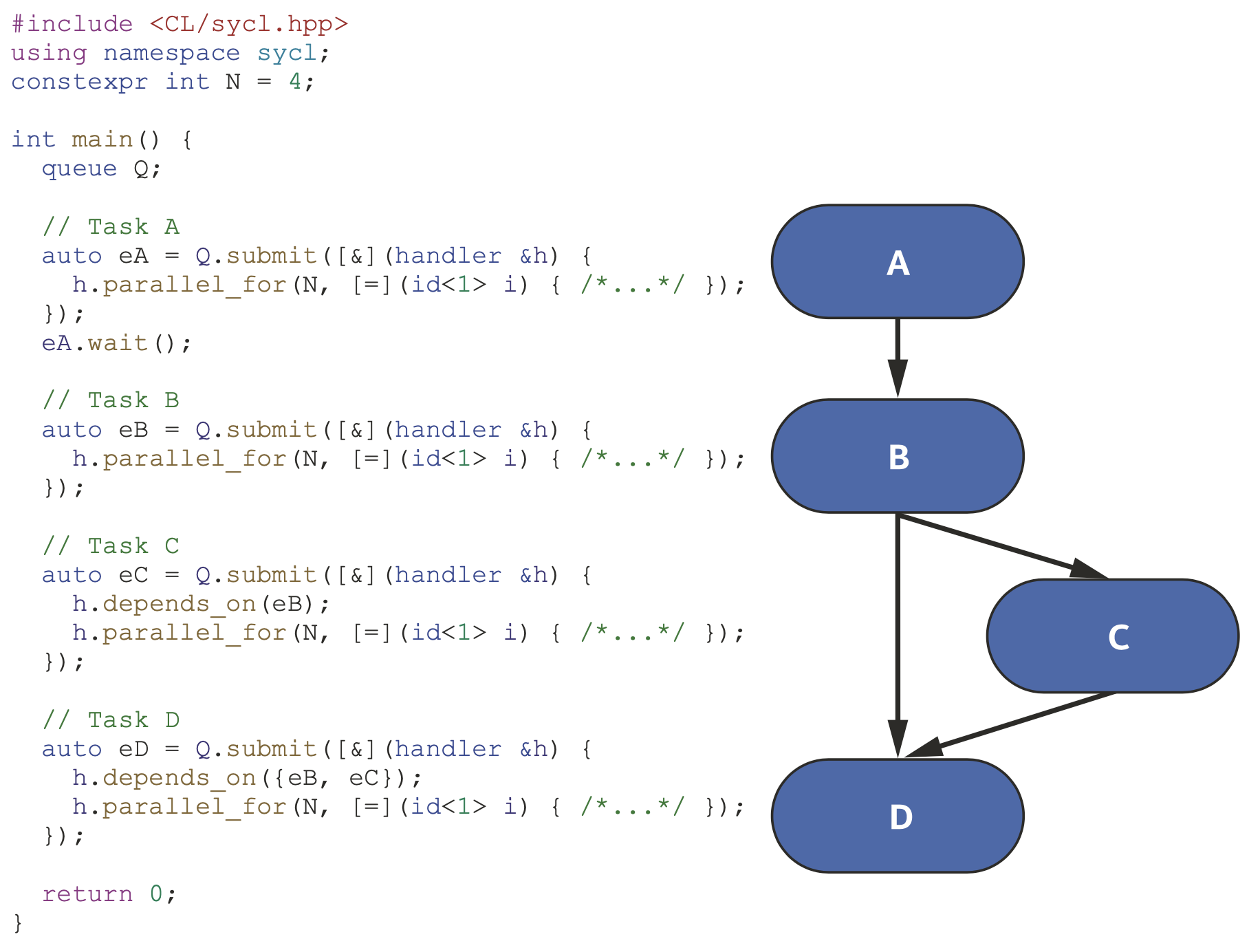 使用
使用events和depends_on
隐式的数据依赖也可能来自对缓冲区通过accessor的访问,依赖关系如下图所示。
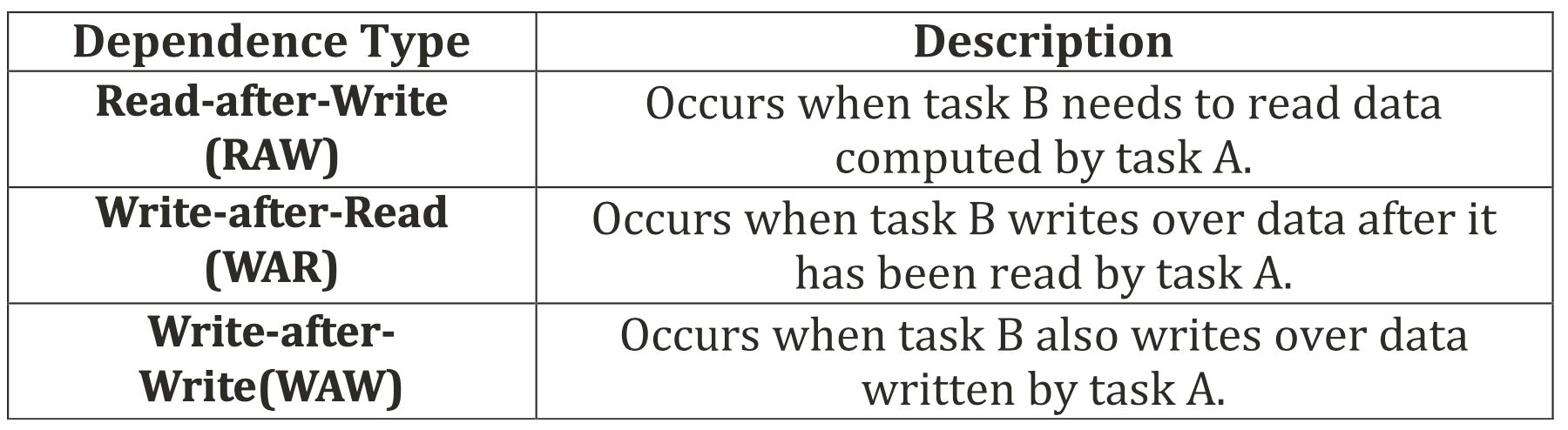 三种数据依赖关系
三种数据依赖关系